
为什么大模型在 OCR 任务上表现不佳?
为什么大模型在 OCR 任务上表现不佳?你是否曾经用最先进的大语言模型处理企业文档,却发现它把财务报表中的“$1,234.56”读成了“123456”?或者在处理医疗记录时,将“0.5mg”误读为“5mg”?对于依赖数据准确性的运营和采购团队来说,这些问题不仅影响工作效率,更可能导致财务损失、法律风险甚至造成医疗事故。
来自主题: AI技术研报
7326 点击 2025-03-28 10:25
你是否曾经用最先进的大语言模型处理企业文档,却发现它把财务报表中的“$1,234.56”读成了“123456”?或者在处理医疗记录时,将“0.5mg”误读为“5mg”?对于依赖数据准确性的运营和采购团队来说,这些问题不仅影响工作效率,更可能导致财务损失、法律风险甚至造成医疗事故。

蚂蚁开源大模型的低成本训练细节,疑似曝光!

新产品发布两天后,在 OpenAI 创始人山姆·阿尔特曼(Sam Altman)的推文下,有人祝贺他十年努力终于带来了 AGI——社交网络上全是吉卜力图像 “All Ghibli Images”。
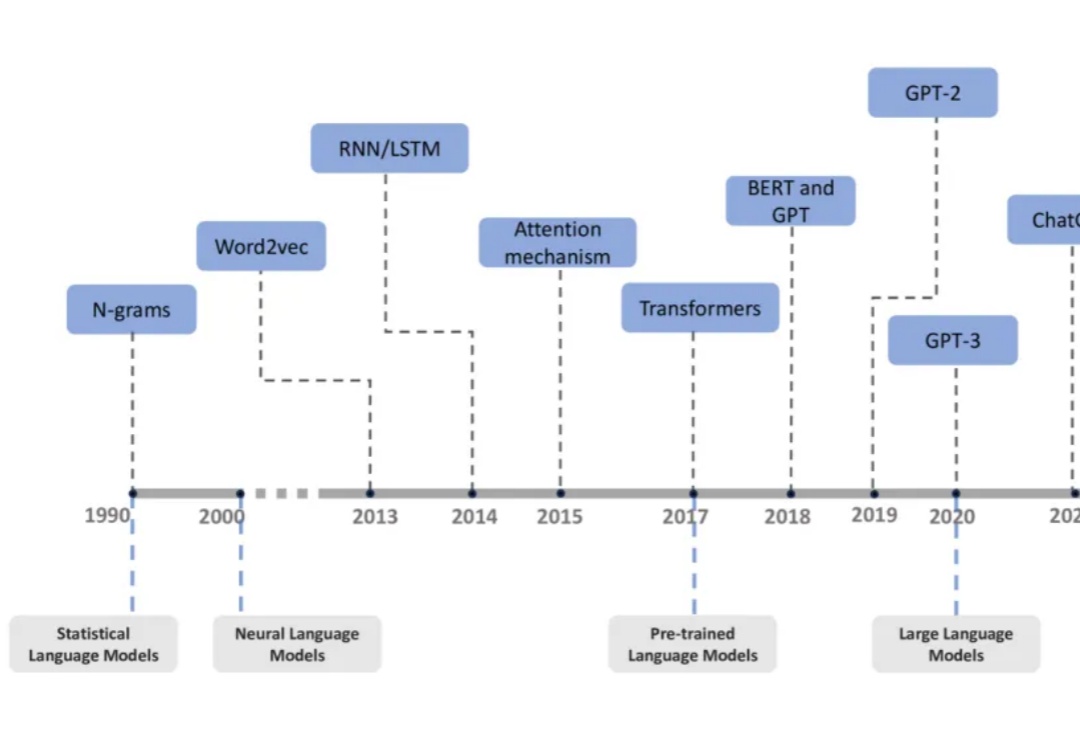
过去十年,自然语言处理领域经历了从统计语言模型到大型语言模型(LLMs)的飞速发展。
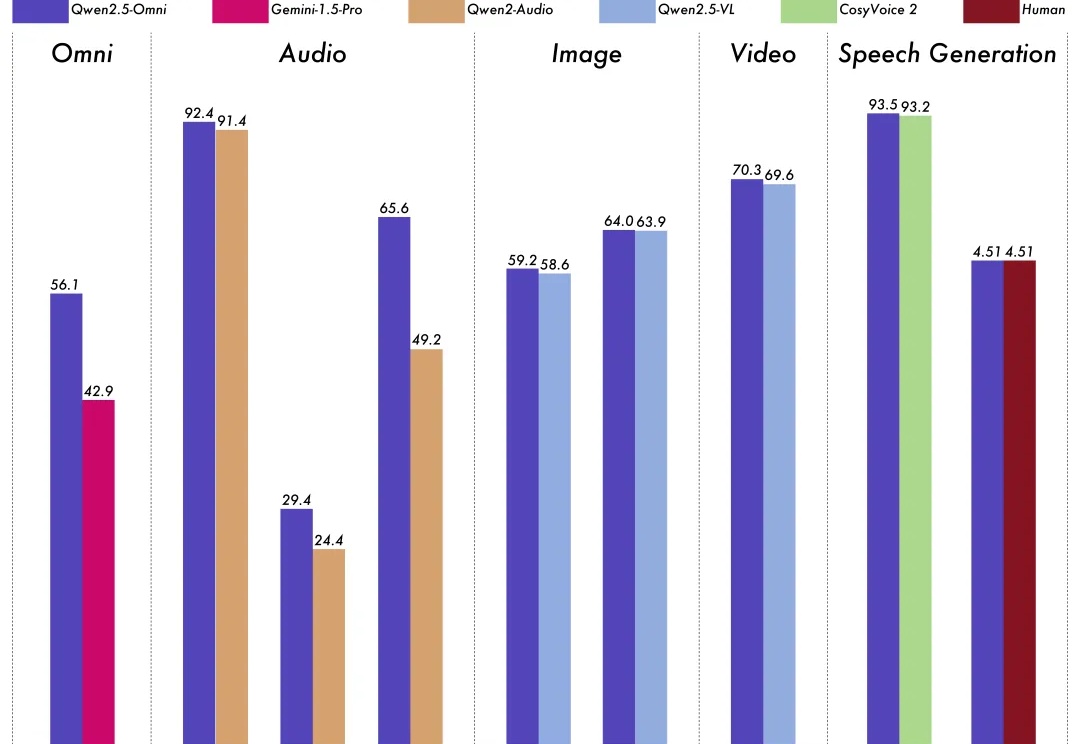
深夜重磅!阿里发布并开源首个端到端全模态大模型——

前英特尔CEO、科技行业大佬帕特·基辛格(Pat Gelsinger)再次出山,加入风投企业Playground Global,重点投入硬科技,包括半导体、垂类AI、量子计算等。现在,正是用技术造福人类的时刻!
时下,AI 爬虫把各种网站折腾得不轻,不是让其崩了就是卡了,导致运行也变得极为不稳定,哪怕更改了用于规定搜索引擎抓取工具可以访问网站上哪些网址的 robots.txt 文件、屏蔽已知的爬虫标识(User-Agent)、甚至过滤可疑流量,它们还是能绕过封锁,伪造身份、用住宅 IP 代理,怎么都拦不住......
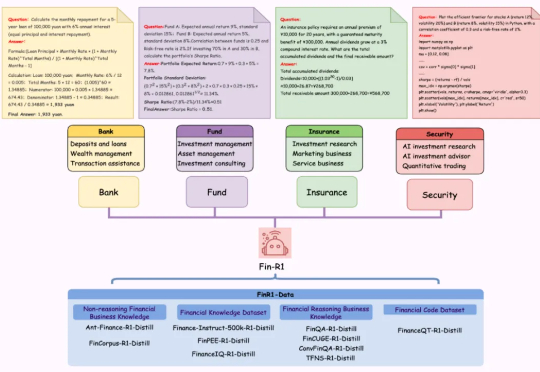
近日,上海财经大学统计与数据科学学院张立文教授与其领衔的金融大语言模型课题组(SUFE-AIFLM-Lab)联合数据科学和统计研究院、财跃星辰、滴水湖高级金融学院正式发布首款 DeepSeek-R1 类推理型人工智能金融大模型:Fin-R1,以仅 7B 的轻量化参数规模展现出卓越性能,全面超越参评的同规模模型并以 75 的平均得
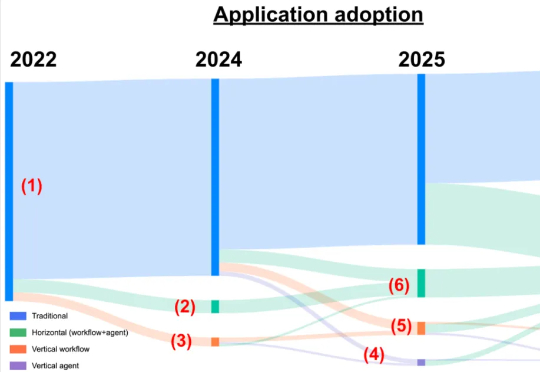
「70 年的 AI 研究历史告诉我们一个最重要的道理:依靠纯粹算力的通用方法,最终总能以压倒性优势胜出。」如今,似乎可以重新再聊下这个话题。比如前两天我们发的 Agent 文章里的观点:未来 AI 智能体的发展方向还得是模型本身,而不是工作流(Work Flow)。
2025 年第一款现象级的 AI 音乐爆品,就这么华丽丽地来了!3 月 26 日,国内「All in AGI 与 AIGC」的科技公司 —— 昆仑万维,发布了最新音乐大模型 Mureka V6 和 O1,给全球音乐圈带来了不小的震撼。