

长视频让大模型集体失明?谢赛宁、杨立昆、李飞飞等提出空间超感知范式,用“预测未来”代替“暴力记忆”
长视频让大模型集体失明?谢赛宁、杨立昆、李飞飞等提出空间超感知范式,用“预测未来”代替“暴力记忆”去年,谢赛宁(Saining Xie)团队发布了 Cambrian-1,一次对图像多模态模型的开放式探索。但团队没有按惯例继续推出 Cambrian-2、Cambrian-3,而是停下来思考:真正的多
来自主题: AI技术研报
8288 点击 2025-11-09 10:38
去年,谢赛宁(Saining Xie)团队发布了 Cambrian-1,一次对图像多模态模型的开放式探索。但团队没有按惯例继续推出 Cambrian-2、Cambrian-3,而是停下来思考:真正的多

前段时间Trae下架了Claude,标志着但凡跟中国沾边AI工具都禁止使用 Claude 但我一点都不慌,因为已经很久没用 Claude 了 尤其在编程赛道上,国产大模型已经通过内部互卷站起来了。
这说明o1不仅能够使用语言,还能够思考语言,具备元语言能力(metalinguistic capacity )。由于语言模型只是在预测句子中的下一个单词,人对语言的深层理解在质上有所不同。因此,一些语言学家表示,大模型实际上并没有在处理语言。

这是一个人类 AI 群星闪耀时的时刻——黄仁勋、李飞飞、杰弗里·辛顿(Geoffrey Hinton)、约书亚·本吉奥(Yoshua Bengio)、杨立昆(Yann LeCun)、比尔·戴利(Bill Dally),罕见同台参与同一个圆桌讨论 AI。之所以能聚在一起,是因为他们六人获得了 2025 年伊丽莎白女王工程奖。
OmniVinci是英伟达推出的全模态大模型,能精准解析视频和音频,尤其擅长视觉和听觉信号的时序对齐。它以90亿参数规模,性能超越同级别甚至更高级别模型,训练数据效率是对手的6倍,大幅降低成本。在视频内容理解、语音转录、机器人导航等场景中,OmniVinci能提供高效支持,展现出卓越的多模态应用能力。

今年是 AI 大模型的落地关键年。大模型技术在快速进步,但行业落地仍面临三大痛点:开发门槛高、场景碎片化、端侧能力有限。结合 AI 能力与云计算,在 CGC2025 大会上,华为云提出的 Versatile 智能体平台与 CloudDevice 云终端协同,正致力于破解这些难题。
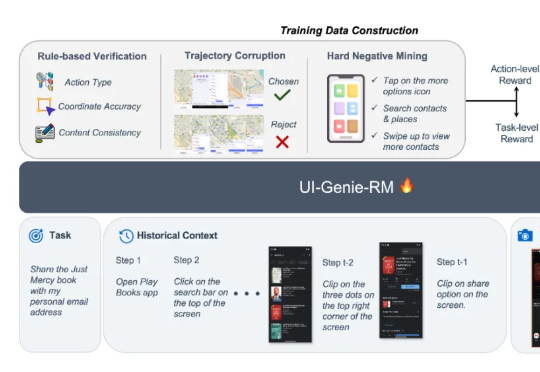
本文来自于香港中文大学 MMLab 和 vivo AI Lab,其中论文第一作者肖涵,主要研究方向为多模态大模型和智能体学习,合作作者王国志,研究方向为多模态大模型和 Agent 强化学习。项目 le
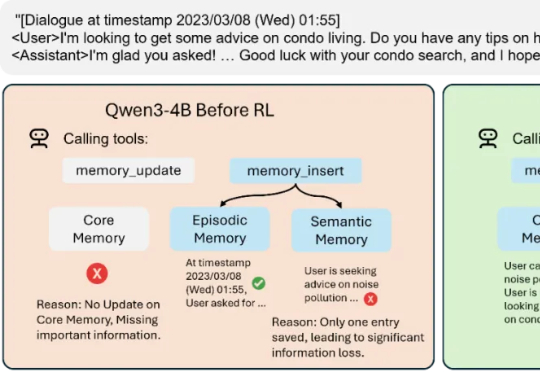
Mem-α 的出现,正是为了解决这一困境。由加州大学圣地亚哥分校的 Yu Wang 在 Anuttacon 实习期间完成,这项工作是首次将强化学习引入大模型的记忆管理体系,让模型能够自主学习如何使用工具去存储、更新和组织记忆。

正好上周(10月27日),MiniMax 公司发布了[2] M2 模型,代表了国产大模型的最新水平。我就想,可以测测它的实战效果,跟智谱公司的 GLM 4.6 和 Anthropic 公司的 Claude Sonnet 4.5 对比一下。毕竟它们都属于目前最先进的编程大模型,跟我们开发者切身相关。

杨红霞,是中国大模型领域一个无法绕开的名字。人们从 M6 模型(阿里达摩院发布的万亿参数 AI 大模型)开始熟知她,而她又在最近走出创业隐匿模式,正式向世界宣告自己已经是一名创业者,并希望能够做出下一