拿下全球最大临床数据库,微软甩出王炸模型!CEO放话:医疗才是AI最重要的赛道
拿下全球最大临床数据库,微软甩出王炸模型!CEO放话:医疗才是AI最重要的赛道官宣全球顶尖医院,微软要为AI医疗定制一款大模型!
来自主题: AI资讯
10411 点击 2026-06-05 09:55
 搜索
搜索
官宣全球顶尖医院,微软要为AI医疗定制一款大模型!
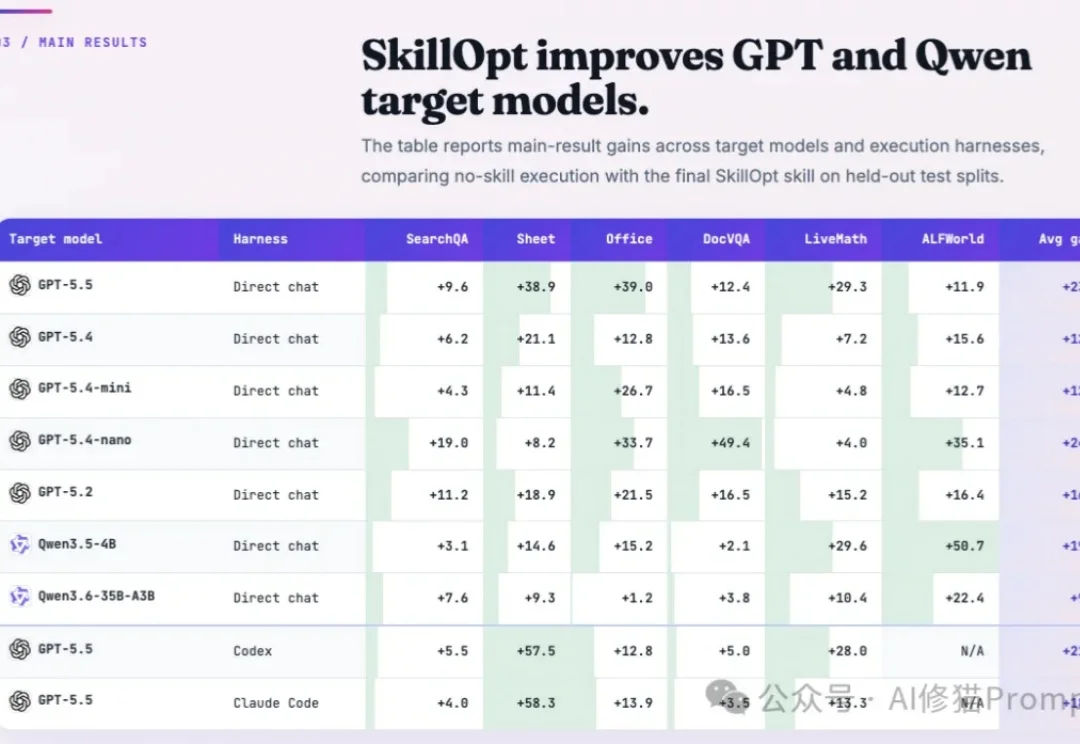
训练大模型时,工程师绝对不会指望网络做一次前向传播就能收敛。它需要数据喂养、Batch切分、学习率控制、验证集筛选以及优化器状态的迭代试错。
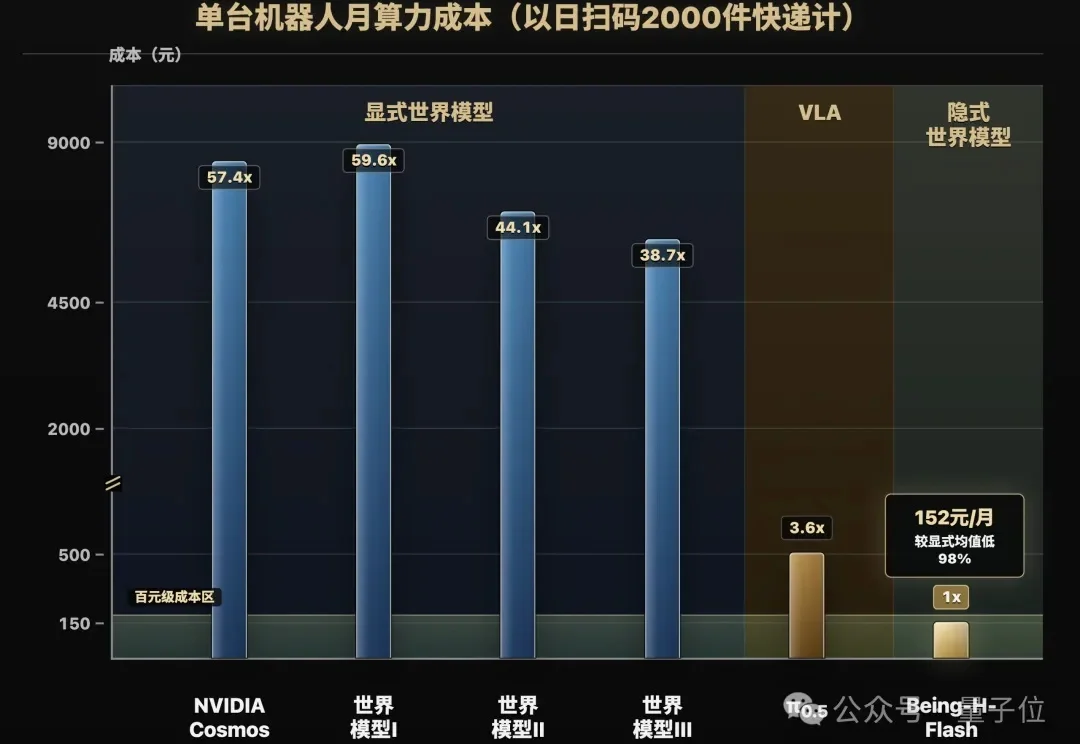
真没想到啊!物理AI的账单,有一天竟然能和大模型一个价。
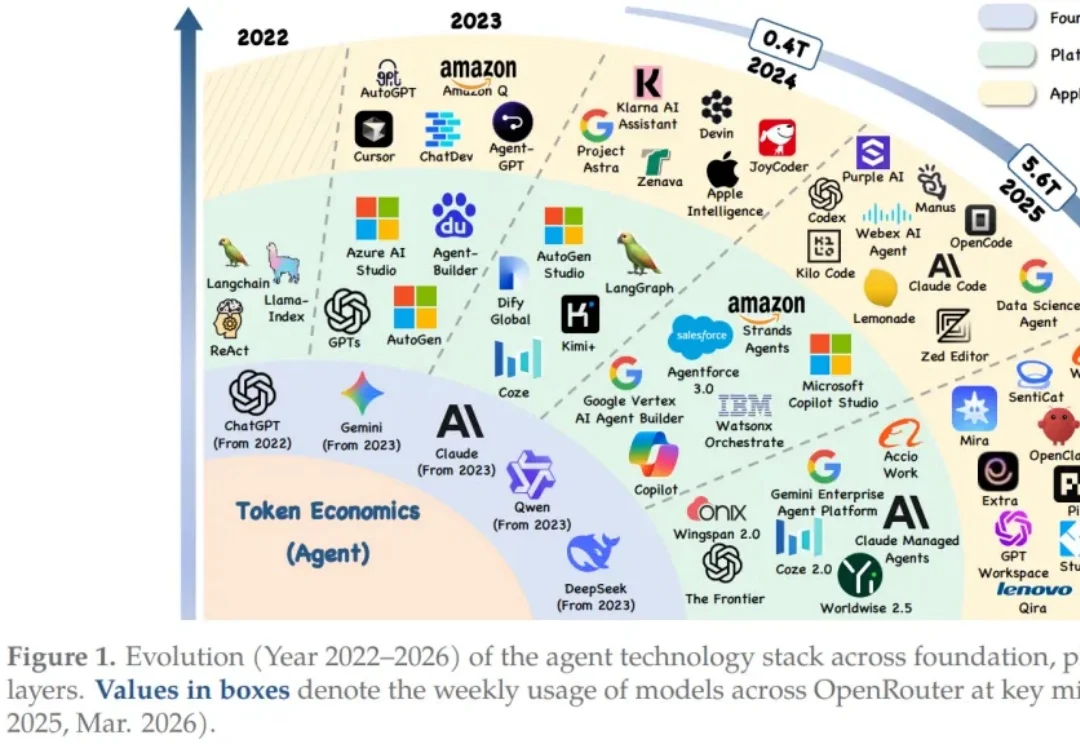
当大模型 Agent 从实验室加速走向金融、医疗、代码开发等高价值场景,一个隐秘却致命的瓶颈正在浮现:Token 的指数级消耗正引发算力、协作与安全的系统性危机。传统 “堆算力、加参数” 的线性优化已触及天花板,我们该如何在 “输出质量” 与 “经济成本” 之间找到可持续的最优解?

为解决科研中对单篇文献深度解析的需求,佐治亚大学团队提出IntrAgent,专注单篇内容,避免大模型幻觉。通过段落排序与迭代阅读机制,精准提取实验细节与元数据。
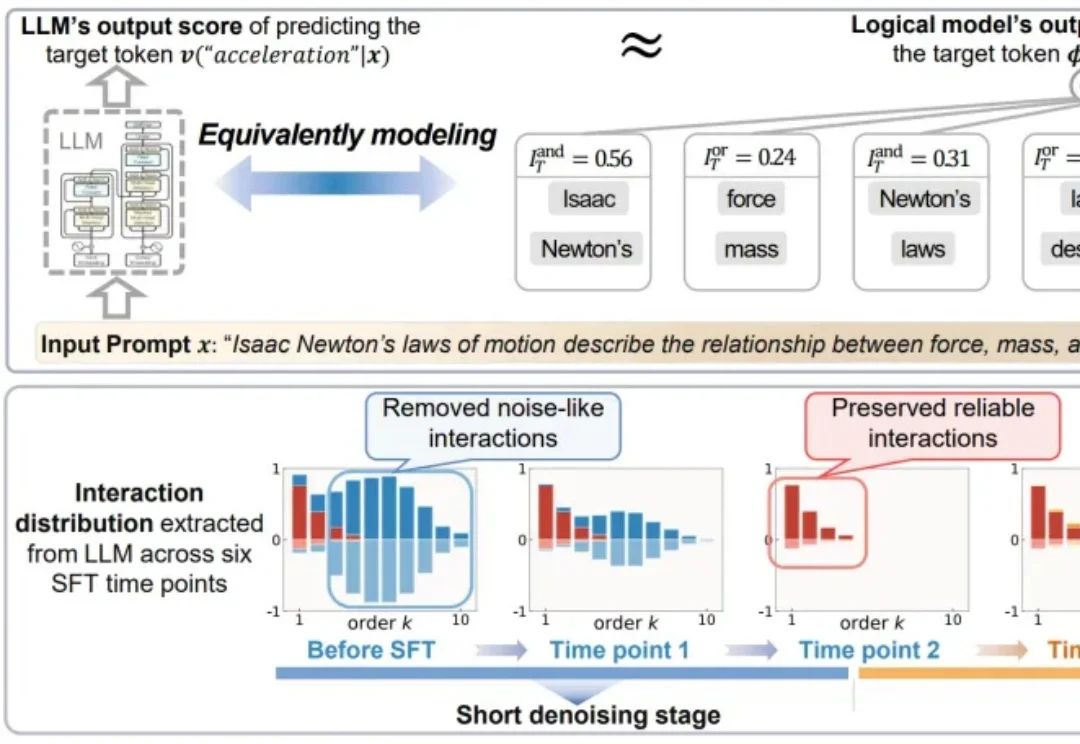
长期以来,监督微调(Supervised Fine-Tuning,SFT)一直是深度神经网络中最常用的模型适配手段。在中小规模的传统神经网络中,SFT 通常能够稳定提升下游任务表现。

由格灵深瞳灵感实验室主导研发的 LLaVA-OneVision-2.0,是一款面向下一代感知智能的视觉语言大模型。团队充分利用视频 Codec 流和自研 OneVision-Encoder,实现跨帧、跨事件的增量观测和连续证据流建模。本文将详细介绍模型架构、训练方法与能力验证,展示该技术在视频理解、空间推理和目标追踪等任务中的应用潜力。

随着大模型智能体深入渗透真实操作系统,一种全新的安全威胁悄然成型:行为越狱(Behavior Jailbreak)。现有安全基准只盯着模型「说了什么」,却对「做了什么」视而不见。新基准LITMUS是首个同时覆盖真实OS环境行为越狱、语义-物理双层验证与多攻击范式的完整评测体系,并首次系统量化了「执行幻觉」这一被整个评测社区忽视的致命盲区。

Windows 从传统 PC 操作系统转型为原生 Agent 智能体运行系统,围绕系统安全底座、Copilot 一体化超级 AI、7 款自研全栈大模型、本地端侧 AI 硬件、新型智能硬件五大板块落地 AI 新功能

近日,「智能知识」(Human Intelligence)完成天使轮融资,由耀途资本、锦秋基金联合投资。本轮融资资金将用于两个方向:前沿数据品类扩张:深耕 Coding、Enterprise Office(GDPVal)、Agentic Tool Use 等高价值数据,并积极探索 AI4Math、AI4Science、AutoResearch 等新场景;