
52页PPT,谷歌Gemini预训练负责人首次揭秘!扩展定律最优解
52页PPT,谷歌Gemini预训练负责人首次揭秘!扩展定律最优解大模型之战烽火正酣,谷歌Gemini 2.5 Pro却强势逆袭!Gemini Flash预训练负责人亲自揭秘,深挖Gemini预训练的关键技术,看谷歌如何在模型大小、算力、数据和推理成本间找到最优解。
来自主题: AI技术研报
9720 点击 2025-04-29 09:43
 搜索
搜索
大模型之战烽火正酣,谷歌Gemini 2.5 Pro却强势逆袭!Gemini Flash预训练负责人亲自揭秘,深挖Gemini预训练的关键技术,看谷歌如何在模型大小、算力、数据和推理成本间找到最优解。

“2月16日那一周,感觉全中国的政府企业都在上Deepseek,甚至很多单位原来一张卡都没有,突然就有了DeepSeek满血版。”金山办公Office产研事业部副总经理刘丹说道,“那段时间我认识的大部分领导也都在问,‘你们到底什么时候接,怎么样的节奏’,整个行业都特别火热。”

4月27日,字节跳动正式启动2026届Top Seed大模型顶尖人才校招计划,开放招募30位顶尖应届博士。大约一个月前,字节跳动开始推进一项名为“节节高”的招聘计划吸引年轻人,计划对毕业不到3年的人才进行大面积扩招,如果内推的社招候选人工作年限≤3年,将有额外奖金。

阿里Qwen3凌晨开源,正式登顶全球开源大模型王座!它的性能全面超越DeepSeek-R1和OpenAI o1,采用MoE架构,总参数235B,横扫各大基准。这次开源的Qwen3家族,8款混合推理模型全部开源,免费商用。
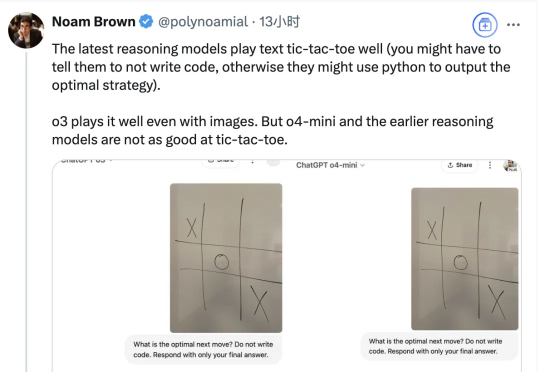
宝可梦之后,让大模型玩井字棋又成了一个新的热门挑战。
多模态大模型几何解题哪家强?

大模型技术加速向产业渗透,如何直击业务痛点、带来真实增效?
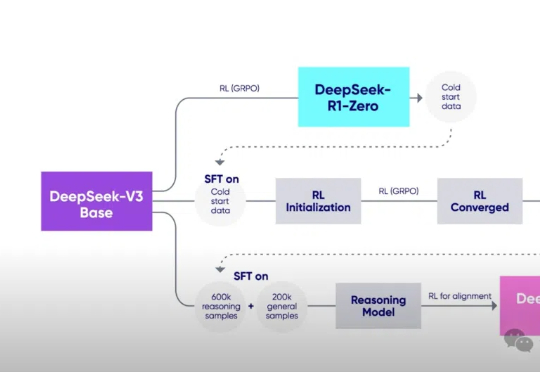
一项来自清华大学和上海交通大学的研究颠覆了对可验证奖励强化学习(RLVR)的认知。RLVR被认为是打造自我进化大模型的关键,但实验表明,它可能只是提高了采样效率,而非真正赋予模型全新推理能力。

最近在看 Agent 方向的论文和产品,已经被各种进展看花了眼。但我发现,真正能超越 demo,能在 B 端场景扎实落地的却寥寥无几。
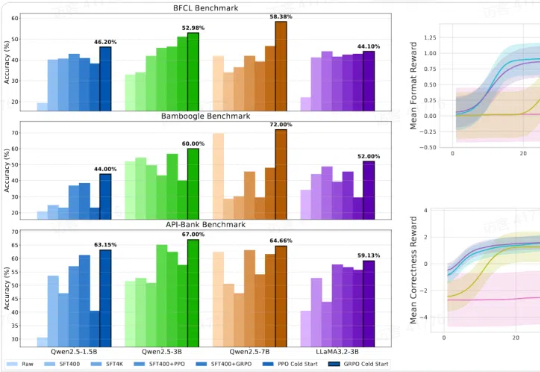
「工欲善其事,必先利其器。」 如今,人工智能正以前所未有的速度革新人类认知的边界,而工具的高效应用已成为衡量人工智能真正智慧的关键标准。