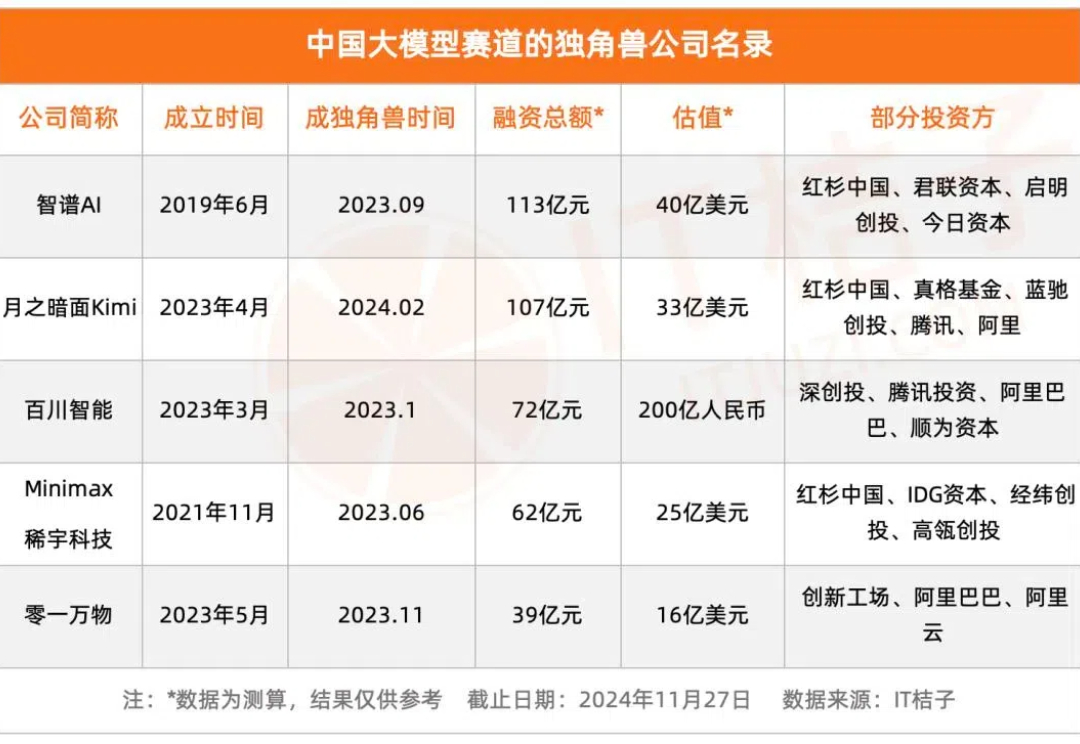
被投资人们热捧的大模型创业者,都是啥背景?
被投资人们热捧的大模型创业者,都是啥背景?大模型赛道是这两年才在国内兴起的,当下已成为人工智能领域的重要分支,并迅速吸引了大量创业者和资本的关注。
来自主题: AI资讯
9710 点击 2024-12-25 09:11
 搜索
搜索
大模型赛道是这两年才在国内兴起的,当下已成为人工智能领域的重要分支,并迅速吸引了大量创业者和资本的关注。

都说国产大模型“通义千问”能打,到底是真强还是智商税?今天就带你看看,这个国产“AI猛将”凭什么火出圈! 2023年4月,阿里巴巴推出通义千问,选择了“全开源”的策略,成为全球开发者关注的焦点。而在2024年的云栖大会上,阿里云进一步发布了Qwen2.5系列,包括多个尺寸的大语言模型、多模态模型、数学模型和代码模型,涵盖从0.5B到72B的完整规模

在智能驾驶行业激烈的“端到端”竞赛中,蔚来汽车计划提升“端到端”高阶智驾方案的交付节奏。

Hippocratic AI 的使命是打造首个以安全性为核心的医疗领域大语言模型(LLM)。
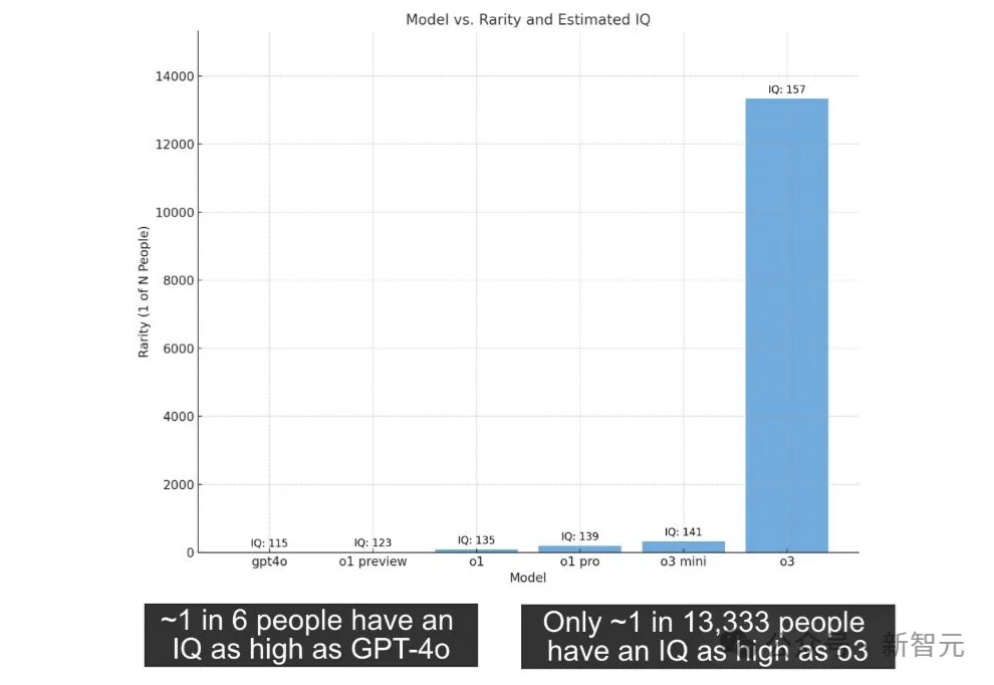
OpenAI o3的智商,竟然已经高达157,碾压99%的人类?这张OpenAI模型智商图全网疯转。甚至有人大胆预测:达到陶哲轩智商(225-230)的大模型,应该会很快出现了。
从开源与闭源的竞争,到多模态AI与自监督学习,再到能效优化和AI伦理的深入探讨,AI技术的演进将继续带来前所未有的创新机会。

最新消息,AI 大模型独角兽阶跃星辰已于近日完成 B 轮融资,总融资金额达数亿美元。投资方包括上海国有资本、腾讯投资、五源资本、启明创投等。

2024年,大模型进展不断。从年初的Sora到最新的o3,更新更好的模型不断被推出,“内卷”到底有没有发生?

老iPhone又能再战一年。

从AI芯片到AI用户这个端到端的产业链中, 贡献价值最高的“那个人”拿走最大的利润。