AI模仿人类看漫画,视频大模型时序定位能力新SOTA
AI模仿人类看漫画,视频大模型时序定位能力新SOTA用看漫画的方式,大幅提升视频大模型时序定位能力!
来自主题: AI技术研报
8329 点击 2024-11-23 16:55
 搜索
搜索
用看漫画的方式,大幅提升视频大模型时序定位能力!
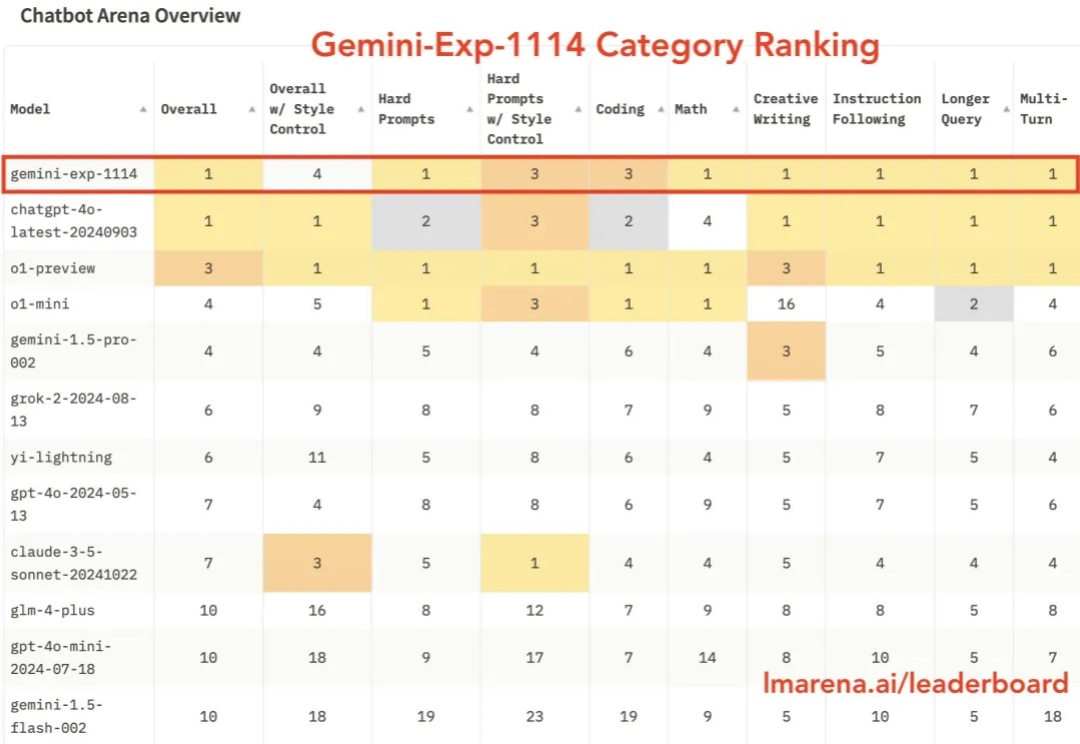
Claude 3.5 Sonnet 应该是目前公认综合能力最好的基础模型。

今年11月,文心的日均调用量达到15亿次,比三个月前的2倍还要多,API调用量的显著增长,更加给了李彦宏、给了百度信心。 在财报电话会议上,李彦宏主动爆料了新进展: 预计明年初,推出新版本的文心大模型。
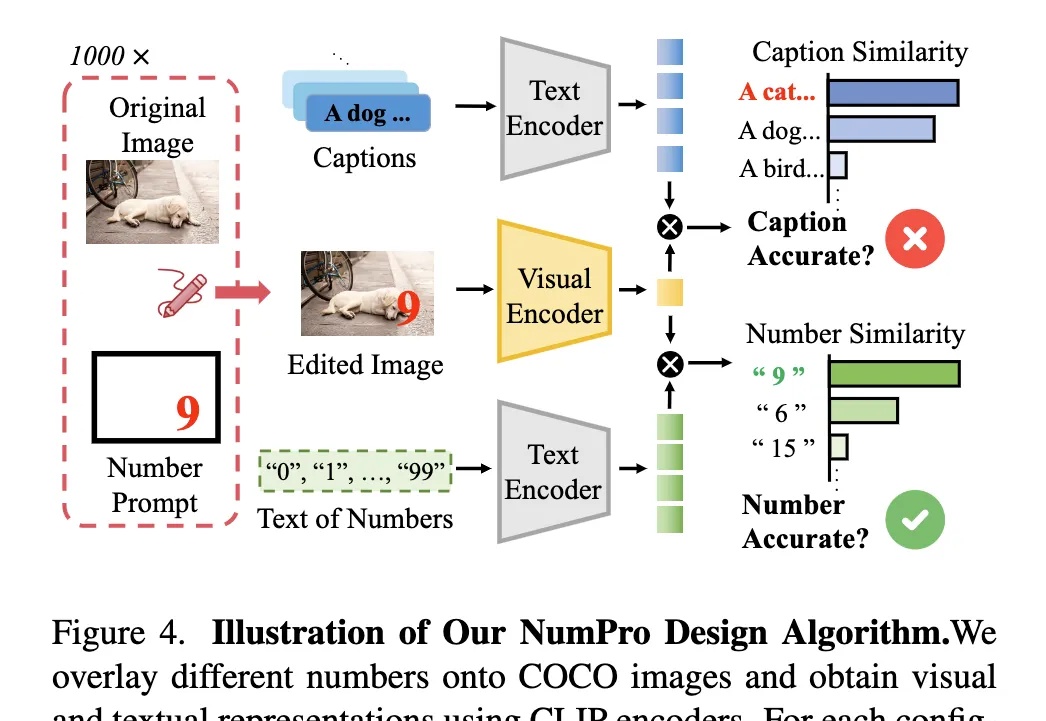
内嵌腾讯混元大模型技术

自2023年以来,国资委多次对中央企业发展人工智能提出要求。其中,在2024年2月的中央企业人工智能专题推进会上,提出中央企业要“开展AI+专项行动”。会上就有10家央企签署倡议书,表示将主动向社会开放人工智能应用场景
太卷了,大模型迭代开始以「周」为单位了吗?
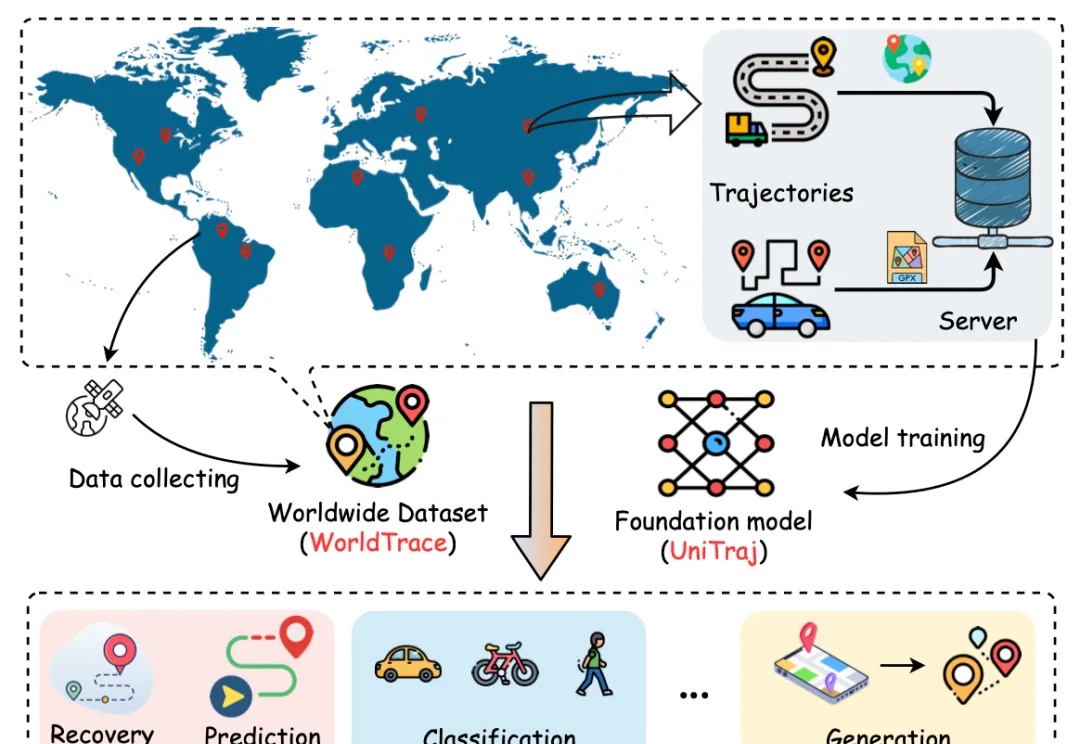
在智慧城市和大数据时代背景下,人类轨迹数据的分析对于交通优化、城市管理、物流配送等关键领域具有重要意义。然而,现有的轨迹相关模型往往受限于特定任务、区域依赖、轨迹数据规模和多样性困乏等问题,限制了模型的泛化能力和实际应用范围。
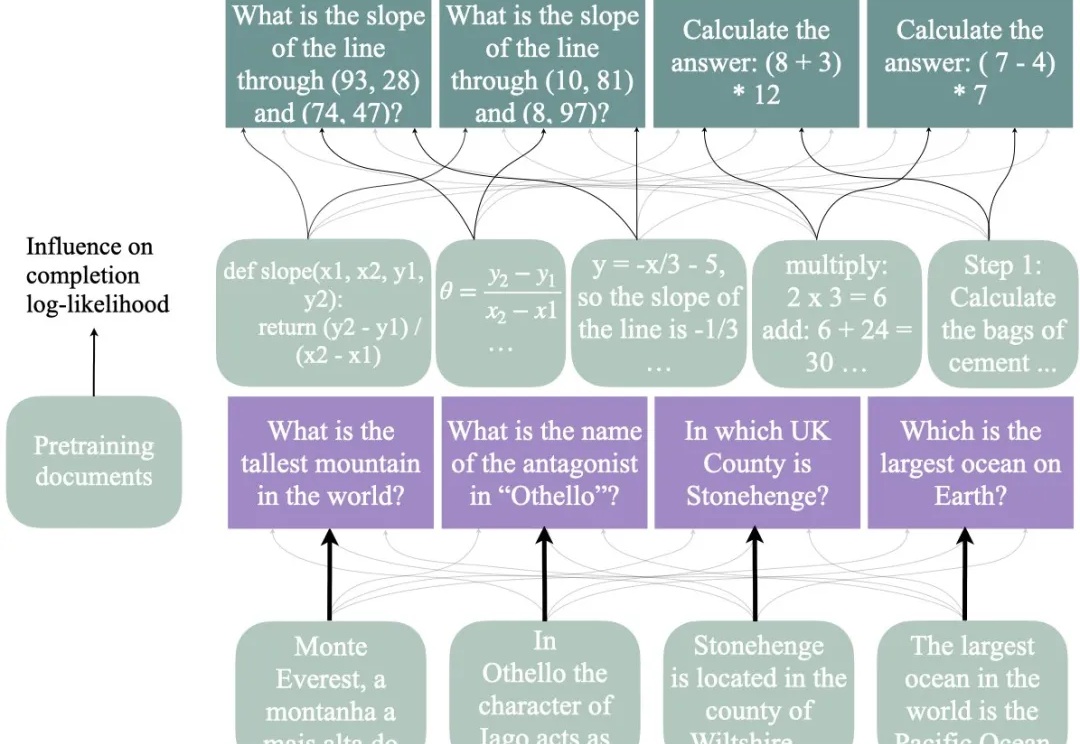
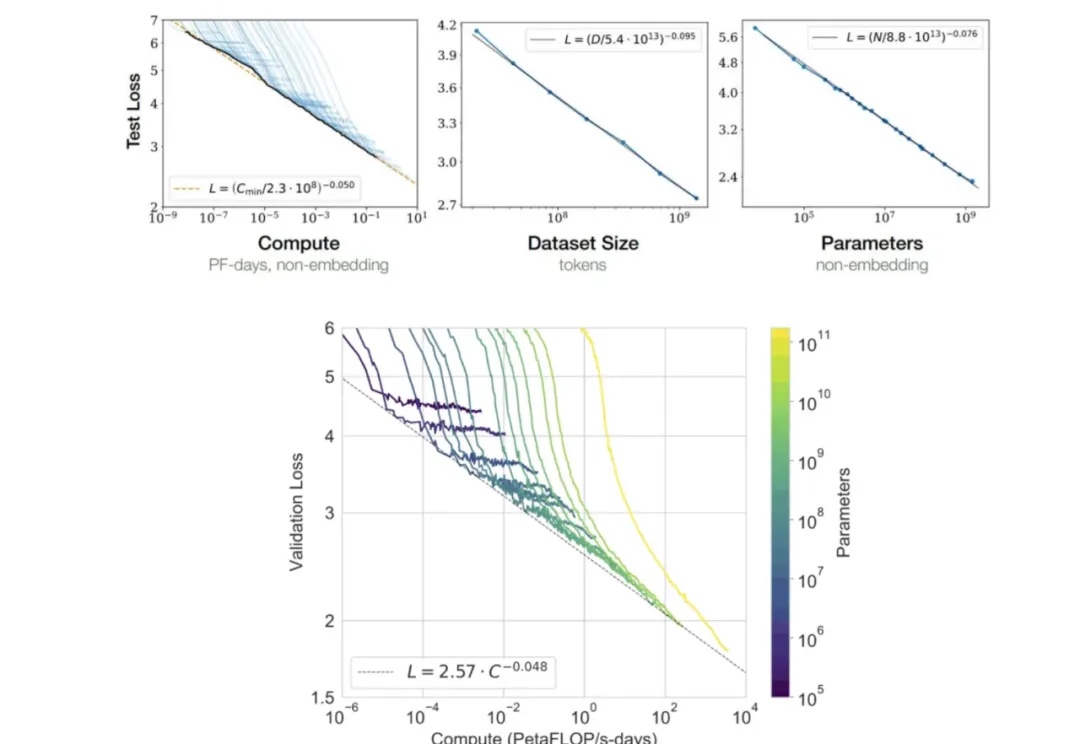
大模型不会照搬训练数据中的数学推理,回答事实问题和推理问题的「思路」也不一样。
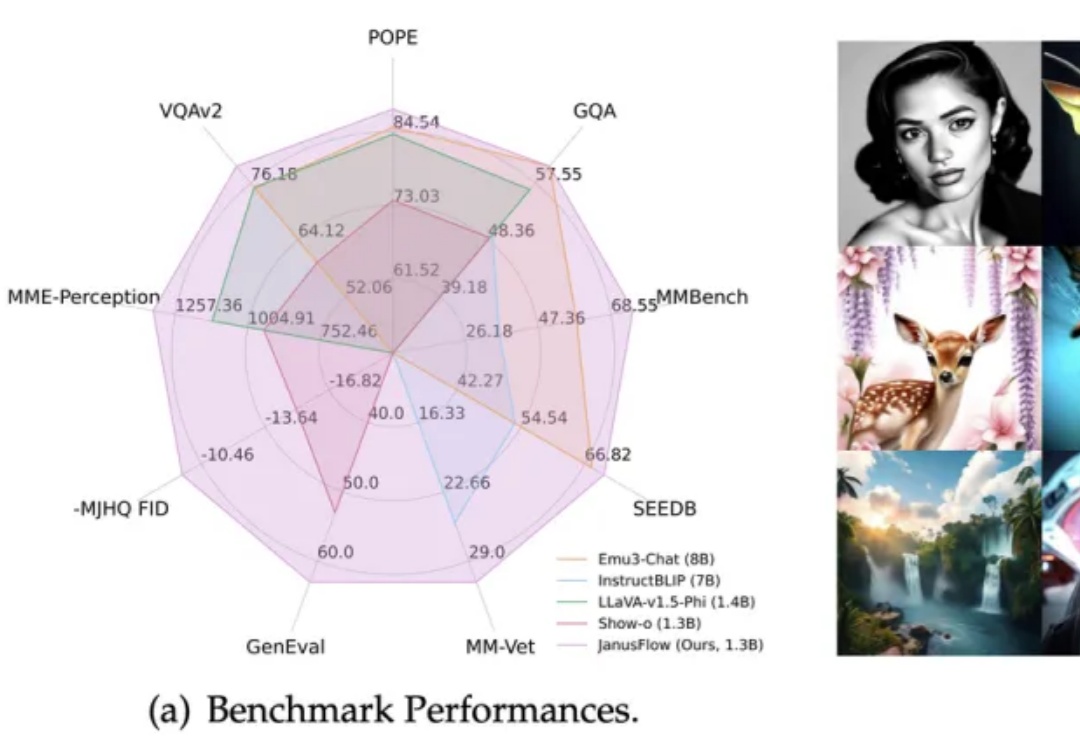
在多模态AI领域,基于预训练视觉编码器与MLLM的方法(如LLaVA系列)在视觉理解任务上展现出卓越性能。
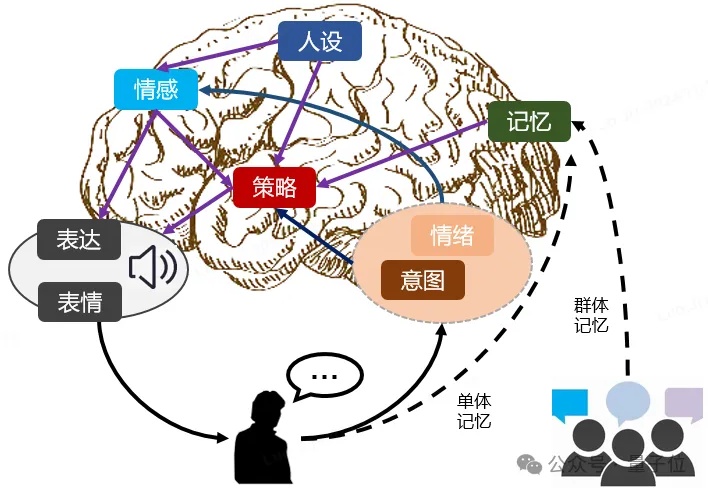
今天,如果你身边有这样一个对话大模型,它就像你身边的一个朋友,快言快语,风趣幽默,既会比喻,又会自嘲,偶尔跟你唱反调,你跟它的聊天欲望会不会更强一些呢?