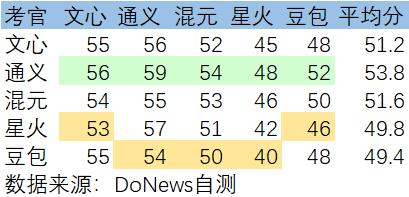
国产大模型互评高考作文,真“学霸”竟然是它?
国产大模型互评高考作文,真“学霸”竟然是它?令厂商可能有点尴尬的是,AI比人坦诚
来自主题: AI资讯
10738 点击 2024-06-10 14:07
 搜索
搜索
令厂商可能有点尴尬的是,AI比人坦诚
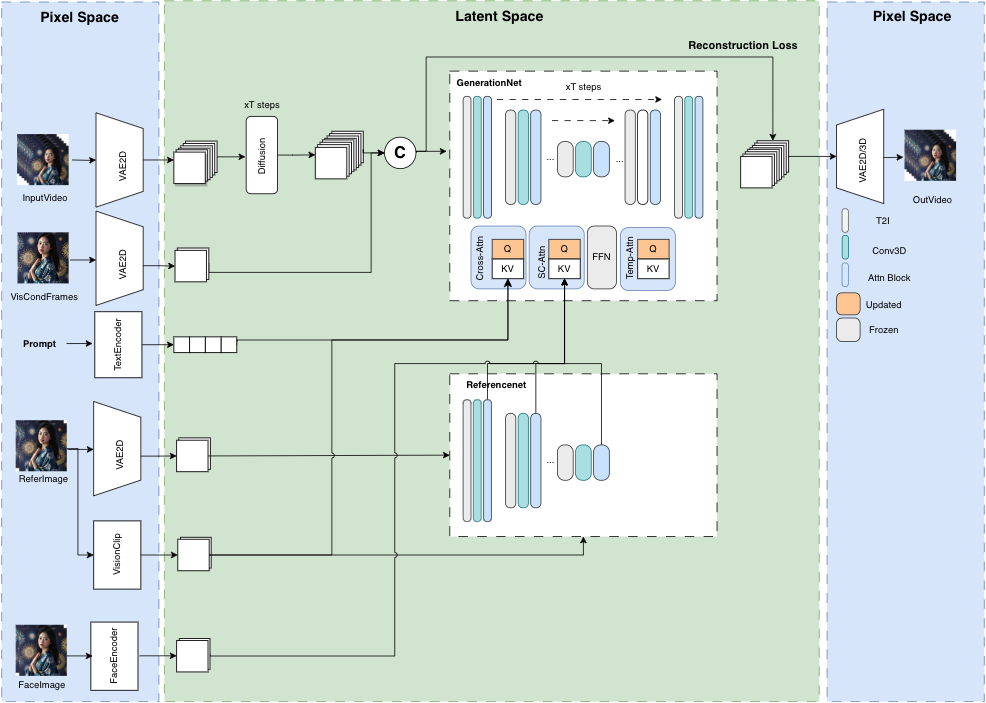
由腾讯音乐娱乐的Lyra Lab团队开发的Muse 开源系列项目,它的最后一个模块终于来了——MusePose !发布后却真诚致谢阿里的项目?
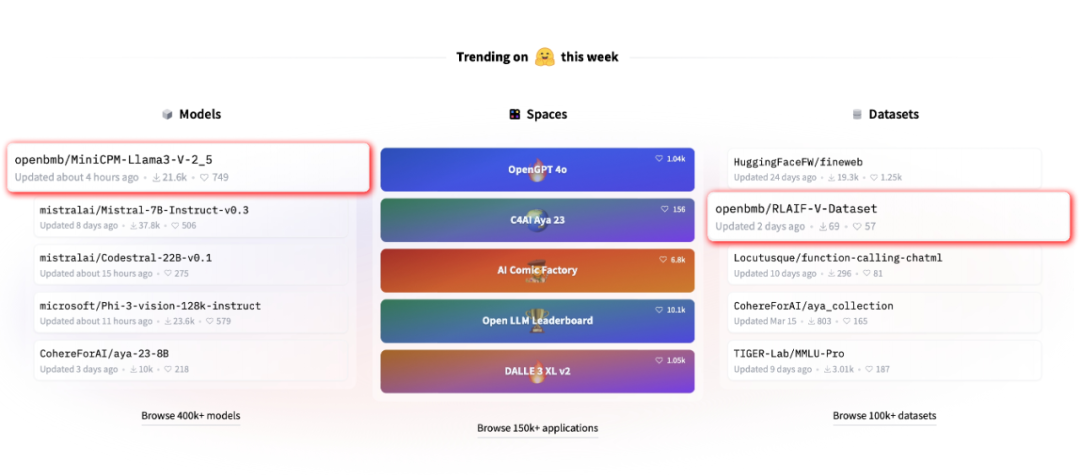
近期,由清华大学自然语言处理实验室联合面壁智能推出的全新开源多模态大模型 MiniCPM-Llama3-V 2.5 引起了广泛关注
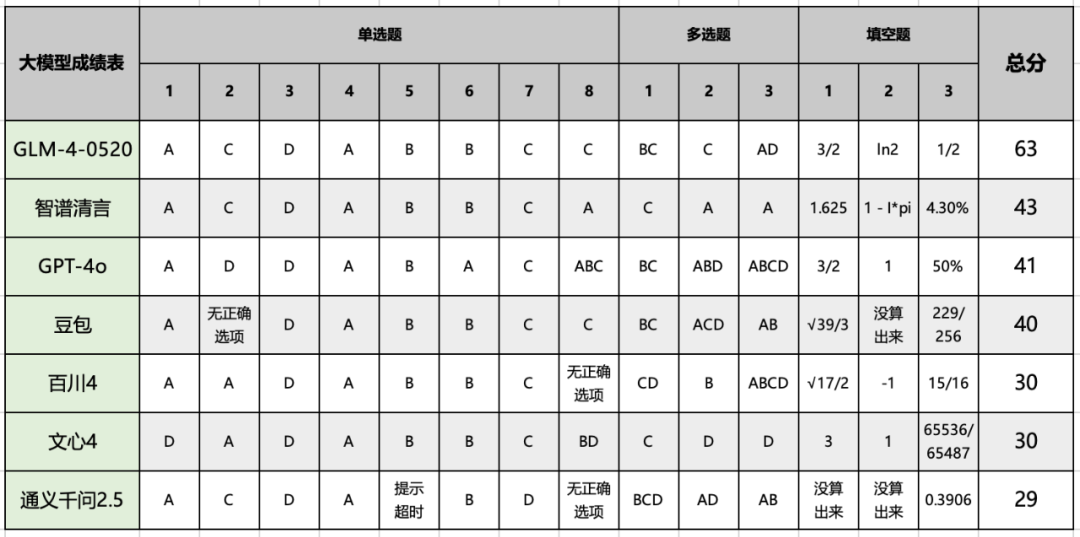
让考生头皮发麻的高考数学,可难倒了顶尖 AI 大模型。
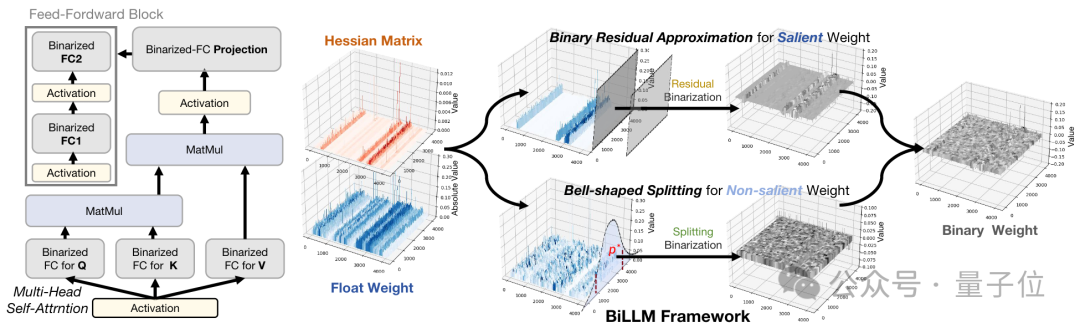
极限量化,把每个参数占用空间压缩到1.1bit!

使用大模型合成的数据,就能显著提升3D生成能力?
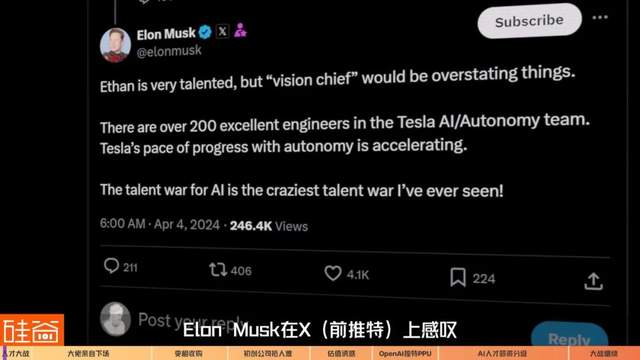
AI人才争夺战激烈,顶尖人才薪资激增。
阿里云发布最强开源大模型Qwen2,干翻Llama 3,比闭源模型还强。

神译局是36氪旗下编译团队,关注科技、商业、职场、生活等领域,重点介绍国外的新技术、新观点、新风向。

近日,由重庆市人力资源和社会保障局、重庆市人力资源开发服务中心开展的“AI工具与现代化办公”专题系列培训在中国·重庆人力资源服务产业园举行,培训旨在助推日常工作与AI工具有效融合,满足广大干部职工在新时代下现代化办公的实际需求,共有来自全市各级机关、企事业单位的200余名学员参加培训。