
把 Kimi 接进 Codex ,小白用 Agent 的最好选择
把 Kimi 接进 Codex ,小白用 Agent 的最好选择如果是小白第一次上手,我会更建议从 Kimi 开始。Kimi 的中文理解、长文本处理、Coding、多模态综合能力都很强,是最适合 Codex 的国产模型。今天这篇内容,手把手教大家如何将第三方大模型接入 Codex 搞定日常任务。
来自主题: AI资讯
9965 点击 2026-07-05 11:05
 搜索
搜索
如果是小白第一次上手,我会更建议从 Kimi 开始。Kimi 的中文理解、长文本处理、Coding、多模态综合能力都很强,是最适合 Codex 的国产模型。今天这篇内容,手把手教大家如何将第三方大模型接入 Codex 搞定日常任务。
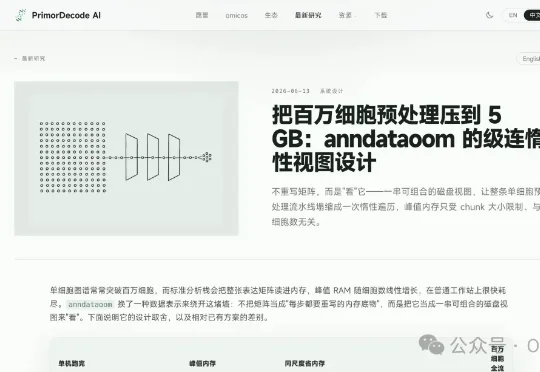
今天,我们将面向任何用户推出OmicOS Science正式版(https://omicos.cn/),无论您处于世界上的任何区域,无论您使用的是任何模型,都可以享受AI时代的红利!我们深知,科学研究最关键的一环是可审计与可复现性。在OmicOS Science中,点击生成的每一张图,你都能看见这张图绘制的代码

AI新云赛道再现巨额融资。成立于2022年的AI新云(Neocloud)公司Together AI,于7月1日正式宣布完成8亿美元C轮融资,投后估值达到83亿美元。Together AI的核心业务是出租NVIDIA GPU集群及其他AI专用基础设施,为企业提供运行开源大模型的云平台。

2026 年,风向掉头了。几个最受关注的年轻 AI 人才,开始走进大厂。罗福莉,四川宜宾乡村出身,北大硕士,DeepSeek-V2 作者之一。被雷军点名后,“天才少女”四个字在热搜上挂了很久。她去了小米,负责大模型 MiMo。
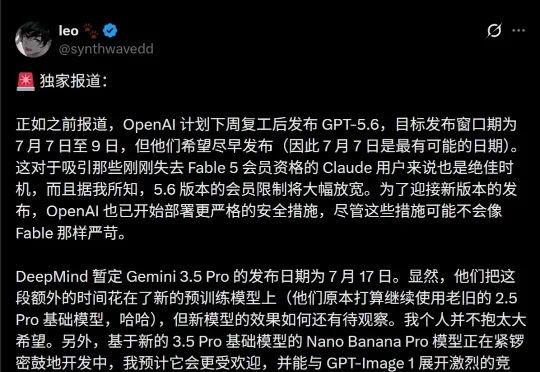
就在昨天,网友们激动发现:Codex应用的底层代码中惊现GPT-5.6 Sol、Terra和Luna三大子模型标识。更令人期待的是,一个全新的「速度拨盘」功能也出现在代码中。根据爆料,OpenAI已经在内部定下了死命令:GPT-5.6发布的目标窗口直指下周二(7月7日)至7月9日。
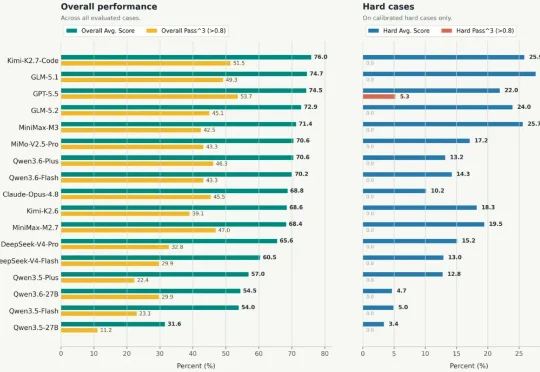
三星大模型团队联合北京大学、香港城市大学、香港科技大学等科研机构,共同发布了面向 AI Agent 的基准测试 LiveClawBench。它关注的并不是「谁的 Agent 更强」,而是一个更基础、也更关键的问题:为什么同一个 AI Agent,在一些任务中已经接近可用,而在另一些任务中却会突然失稳?
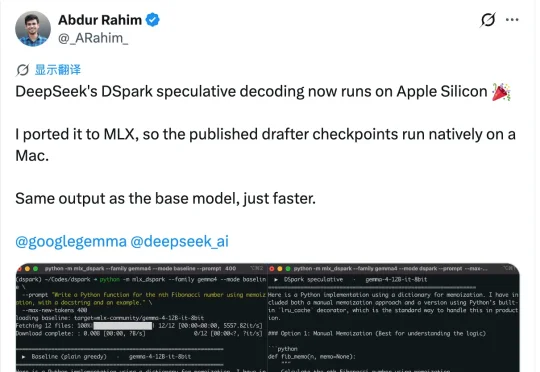
DSpark刚开源一周,就被搬进了苹果电脑。移植版本叫mlx-dspark,跑的是Gemma-4 12B和Qwen3-4B这两个模型。装上之后,这两个模型在Mac上的生成速度分别提了1.6倍和1.4倍。

7月2日,据大厂日爆消息,美团内部开始限制使用豆包大模型。消息称,美团向所有涉及到豆包大模型的业务部门下发通知,要求自查并规划迁移至LongCat、DeepSeek等模型,若无法迁移,需单独走审批流程。对此消息,截至发稿,美团暂无官方回应。据媒体报道,这并非美团首次收紧外部大模型的使用。今年4月,美团对内部大模型使用做出调整,不再推荐业务使用阿里云提供的Qwen模型。若业务仍需使用,需上报审批。

做大模型RL微调,你是不是也踩过这些坑?
当大模型应用进入深水区,决定一个 Agent 体验上限的,早已不只是 "答得对不对", 而是 "能不能持续记住同一个人"。