
字节&MAP重塑大模型推理算法优化重点,强化学习重在高效探索助力LLM提升上限
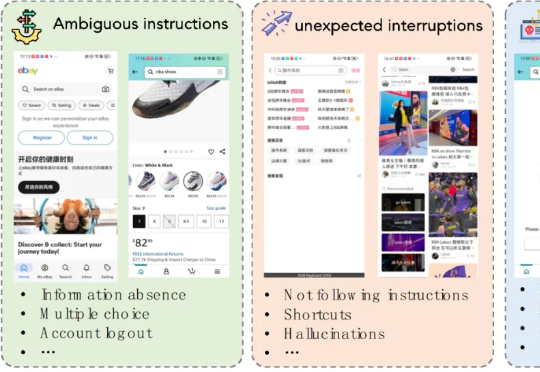
字节&MAP重塑大模型推理算法优化重点,强化学习重在高效探索助力LLM提升上限强化学习(RL)范式虽然显著提升了大语言模型(LLM)在复杂任务中的表现,但其在实际应用中仍面临传统RL框架下固有的探索难题。
来自主题: AI资讯
8302 点击 2025-08-08 11:06
 搜索
搜索
强化学习(RL)范式虽然显著提升了大语言模型(LLM)在复杂任务中的表现,但其在实际应用中仍面临传统RL框架下固有的探索难题。
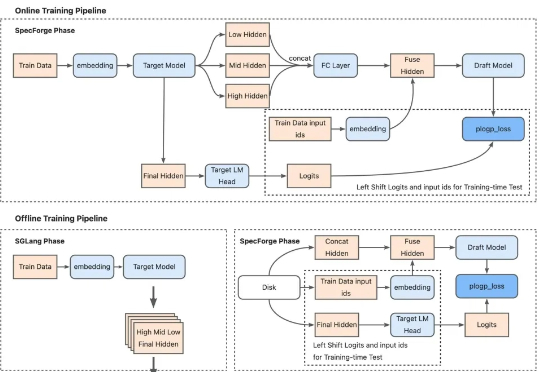
专门适用超大模型、带来2.18倍推理加速,最新投机采样训练框架开源! SGLang团队联合美团搜推平台、Cloudsway.AI开源SpecForge。

如何理解大模型推理能力?现在有来自谷歌DeepMind推理负责人Denny Zhou的分享了。 就是那位和清华姚班马腾宇等人证明了只要思维链足够长,Transformer就能解决任何问题的Google Brain推理团队创建者。 Denny Zhou围绕大模型推理过程和方法,在斯坦福大学CS25上讲了一堂“LLM推理”课。
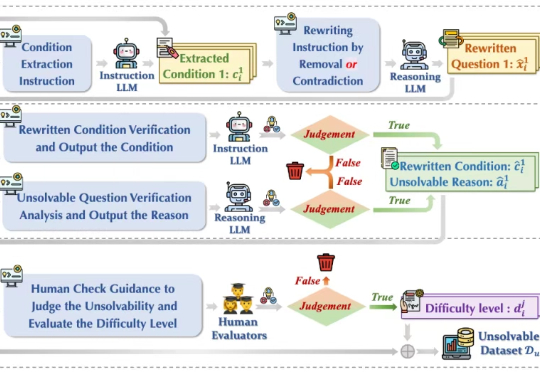
今年初以 DeepSeek-r1 为代表的大模型在推理任务上展现强大的性能,引起广泛的热度。然而在面对一些无法回答或本身无解的问题时,这些模型竟试图去虚构不存在的信息去推理解答,生成了大量的事实错误、无意义思考过程和虚构答案,也被称为模型「幻觉」 问题,如下图(a)所示,造成严重资源浪费且会误导用户,严重损害了模型的可靠性(Reliability)。
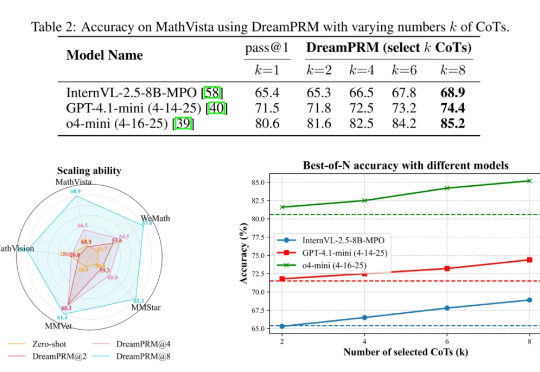
使用过程奖励模型(PRM)强化大语言模型的推理能力已在纯文本任务中取得显著成果,但将过程奖励模型扩展至多模态大语言模型(MLLMs)时,面临两大难题:
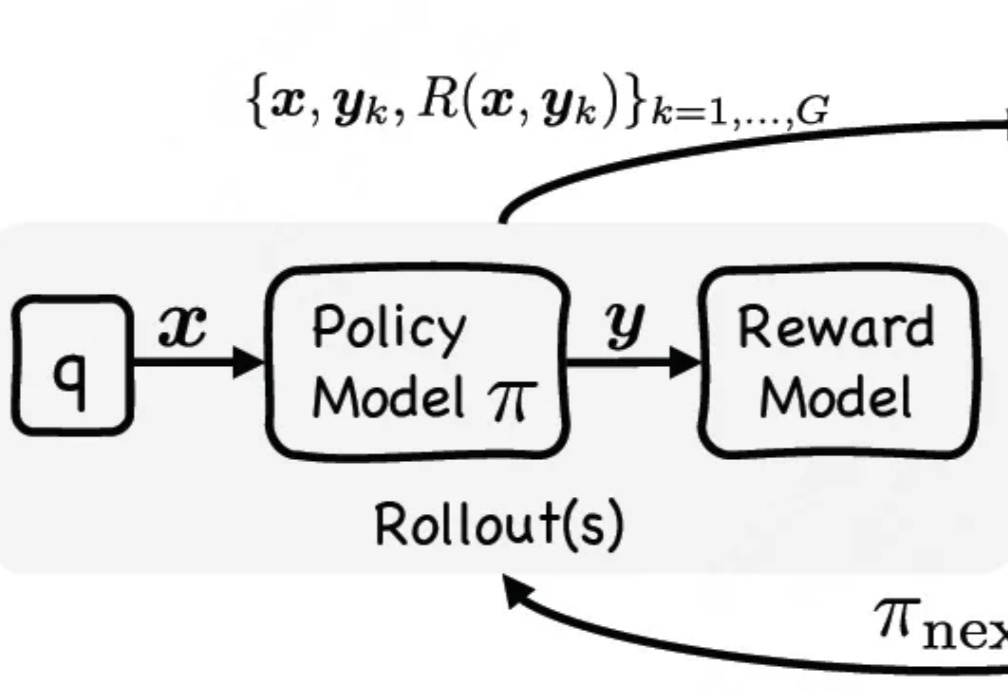
最近,关于大模型推理的测试时间扩展(Test time scaling law )的探索不断涌现出新的范式,包括① 结构化搜索结(如 MCTS),② 过程奖励模型(Process Reward Model )+ PPO,③ 可验证奖励 (Verifiable Reward)+ GRPO(DeepSeek R1)。
本文第一作者是上海交通大学计算机学院三年级博士生程彭洲,研究方向为多模态大模型推理、AI Agent、Agent 安全等。通讯作者为张倬胜助理教授和刘功申教授。
通过单阶段监督微调与强化微调结合,让大模型在训练时能同时利用专家演示和自我探索试错,有效提升大模型推理性能。

本文第一作者为前阿里巴巴达摩院高级技术专家,现一年级博士研究生满远斌,研究方向为高效多模态大模型推理和生成系统。通信作者为第一作者的导师,UTA 计算机系助理教授尹淼。尹淼博士目前带领 7 人的研究团队,主要研究方向为多模态空间智能系统,致力于通过软件和系统的联合优化设计实现空间人工智能的落地。

当前,强化学习(RL)在提升大语言模型(LLM)推理能力方面展现出巨大潜力。DeepSeek R1、Kimi K1.5 和 Qwen 3 等模型充分证明了 RL 在增强 LLM 复杂推理能力方面的有效性。