
一手实测豆包新发布的视觉理解大模型,他们真的卷起飞了。
一手实测豆包新发布的视觉理解大模型,他们真的卷起飞了。人在字节火山发布会现场。 眼睁睁看着他们发了一大堆的模型升级,眼花缭乱,有一种要一股脑把字节系的AI底牌往桌上亮的感觉。 有语音的,有音乐的,有大语言模型的,有文生图的,有3D生成。
来自主题: AI资讯
9234 点击 2024-12-18 14:17
 搜索
搜索
人在字节火山发布会现场。 眼睁睁看着他们发了一大堆的模型升级,眼花缭乱,有一种要一股脑把字节系的AI底牌往桌上亮的感觉。 有语音的,有音乐的,有大语言模型的,有文生图的,有3D生成。

现如今,以 GPT 为代表的大语言模型正深刻影响人们的生产与生活,但在处理很多专业性和复杂程度较高的问题时仍然面临挑战。在诸如药物发现、自动驾驶等复杂场景中,AI 的自主决策能力是解决问题的关键,而如何进行决策大模型的高效训练目前仍然是开放性的难题。
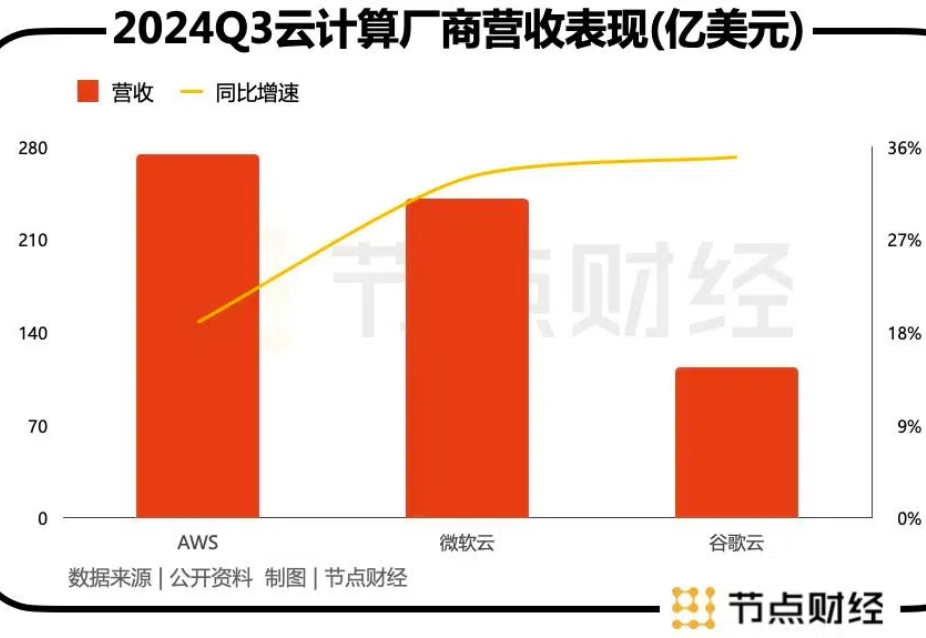
继微软云(Azure )和谷歌云(Google Cloud)之后,亚马逊旗下AWS也在近期发布了自己的基础大语言模型Nova。

在当前大语言模型(LLM)的应用生态中,函数调用能力(Function Calling)已经成为一项不可或缺的核心能力。
在人工智能快速发展的今天,大语言模型(LLM)已经成为改变世界的重要力量。然而,如何高效地编写、管理和维护提示词(Prompt)仍然是一个巨大的挑战。

大语言模型(LLMs)通过更多的推理展现出了更强的能力和可靠性,从思维链提示发展到了 OpenAI-o1 这样具有较强推理能力的模型。

一家日本初创公司Orange正在使用Anthropic公司的旗舰大语言模型Claude帮助将漫画翻译成英文,使该公司能够在短短几天内为西方受众推出一部新作,而不是人工团队需要两到三个月的时间。

随着ChatGPT等大语言模型的问世,人工智能进入了一个全新的时代。在这股浪潮中,多模态AI技术成为业界竞相追逐的目标,OpenAI的Sora更是将这股热情推向高潮。

目前大语言模型(Large Language Models, LLMs)的推理能力备受关注。从思维链(Chain of Thought,CoT)技术提出,到以 o1 为代表的长思考模型发布,大模型正在展现出接近人类甚至领域专家的水平,其中数学推理是一个典型任务。

大语言模型(LLMs)在推理任务上展现出了令人瞩目的能力,但其推理思维方式的单一性一直是制约性能提升的关键瓶颈。目前的研究主要关注如何通过思维链(Chain-of-Thought)等方法来提升推理的质量,却忽视了一个重要维度——推理类型的多样性。