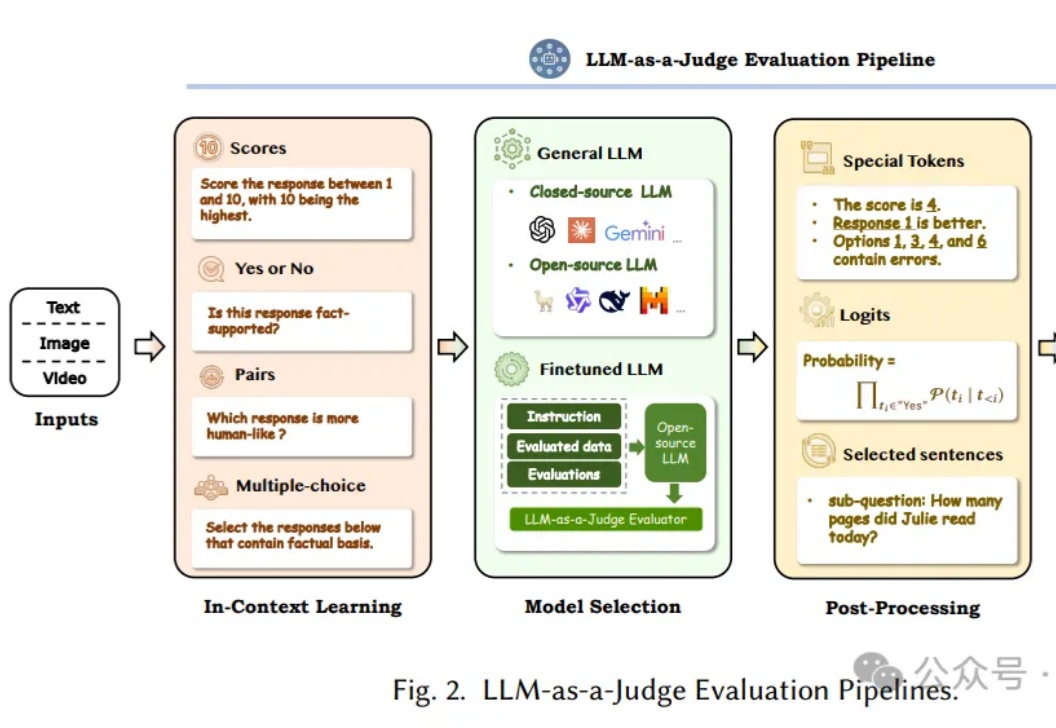
最新综述:LLM作为法官,用AI评判AI
最新综述:LLM作为法官,用AI评判AI让AI来评判AI,即利用大语言模型(LLM)作为评判者,已经成为近半年的Prompt热点领域。这个方向不仅代表了AI评估领域的重要突破,更为正在开发AI产品的工程师们提供了一个全新的思路。
来自主题: AI技术研报
11760 点击 2024-11-29 09:11
 搜索
搜索
让AI来评判AI,即利用大语言模型(LLM)作为评判者,已经成为近半年的Prompt热点领域。这个方向不仅代表了AI评估领域的重要突破,更为正在开发AI产品的工程师们提供了一个全新的思路。
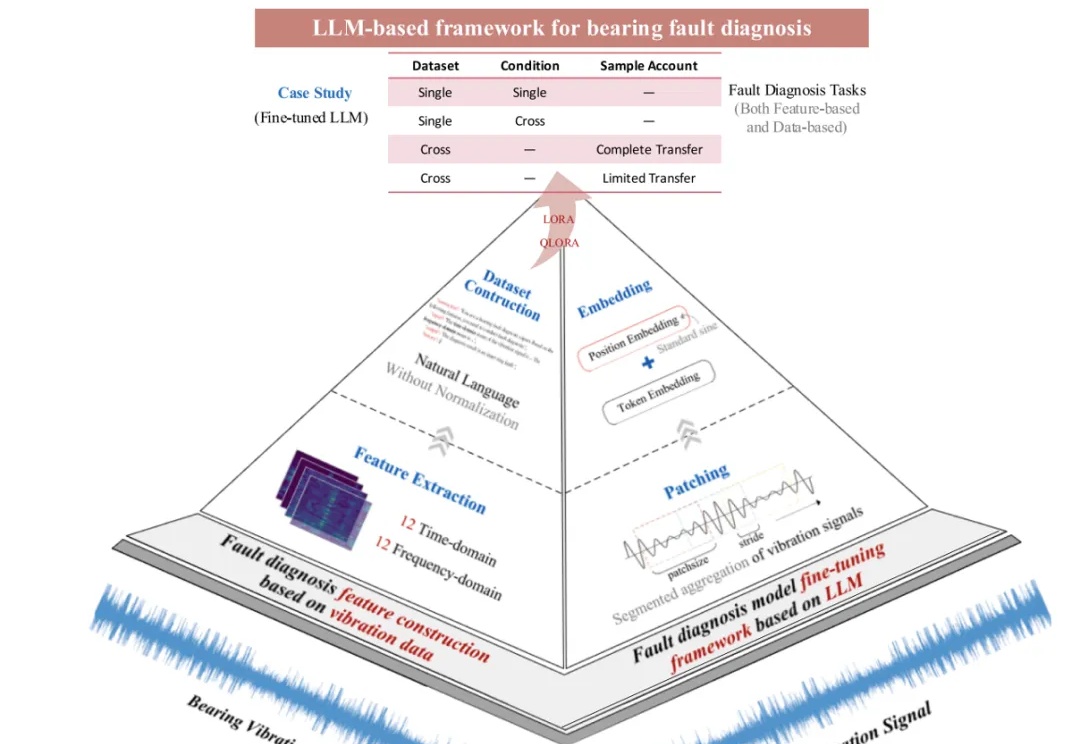
近日,《Mechanical System and Signal Processing》(MSSP)在线发表刊登北航 PHM 团队最新研究成果:基于大语言模型的轴承故障诊断框架(LLM-based Framework for Bearing Fault Diagnosis)。
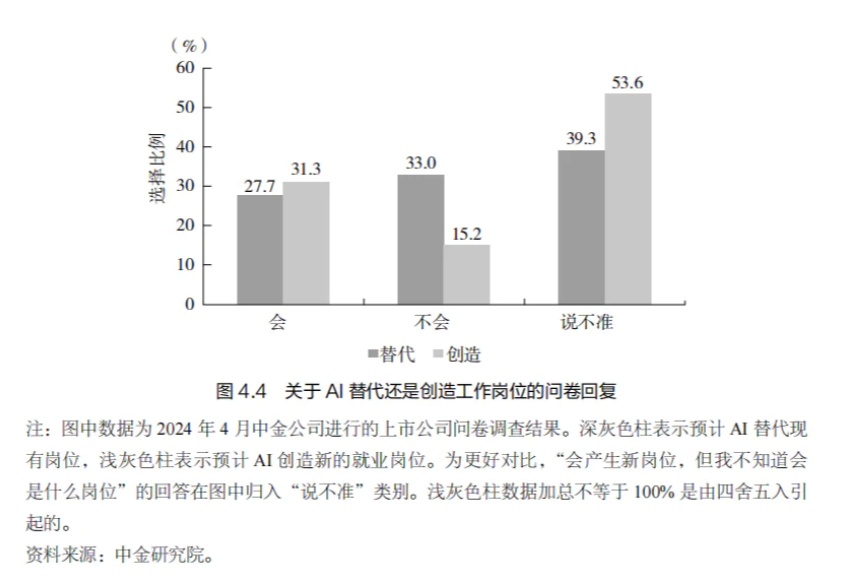
2022 年,以ChatGPT 大语言模型(LLM)的发布为标志, AI 神经网络的类人学习能力取得了里程碑式的进展,在全球范围内掀起了一股 AI 热潮。
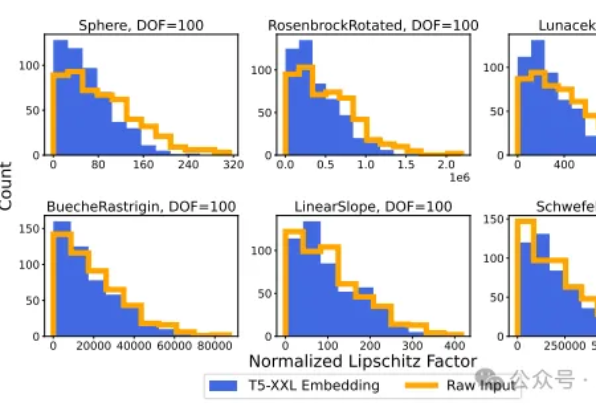
在人工智能领域,大语言模型(LLM)的向量嵌入能力一直被视为处理文本数据的利器。然而,斯坦福大学和Google DeepMind的研究团队带来了一个颠覆性发现:LLM的向量嵌入能力可以有效应用于回归任务。
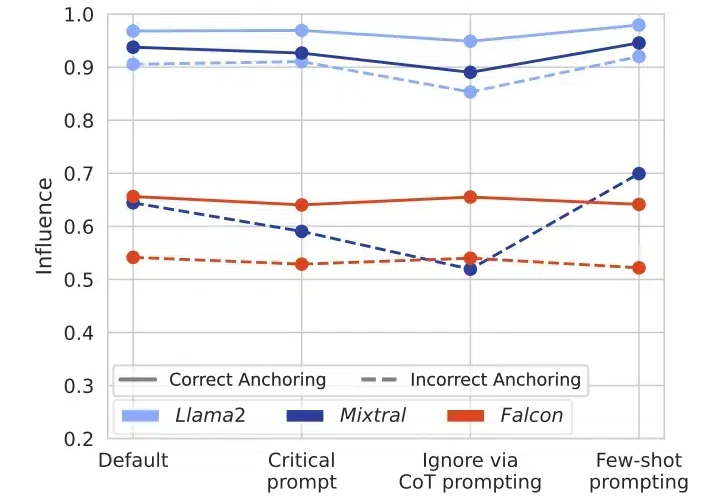
在当今人工智能迅猛发展的时代,大语言模型(LLMs)已成为众多AI应用的核心引擎。然而,来自ETH Zurich和Google DeepMind的一项最新研究揭示了一个令人深思的现象:这些看似强大的模型存在着严重的“盲从效应”。
近日,DeepMind 团队将水印技术和投机采样(speculative sampling)结合,在为大语言模型加入水印的同时,提升其推理效率,降低推理成本,因此适合用于大规模生产环境。
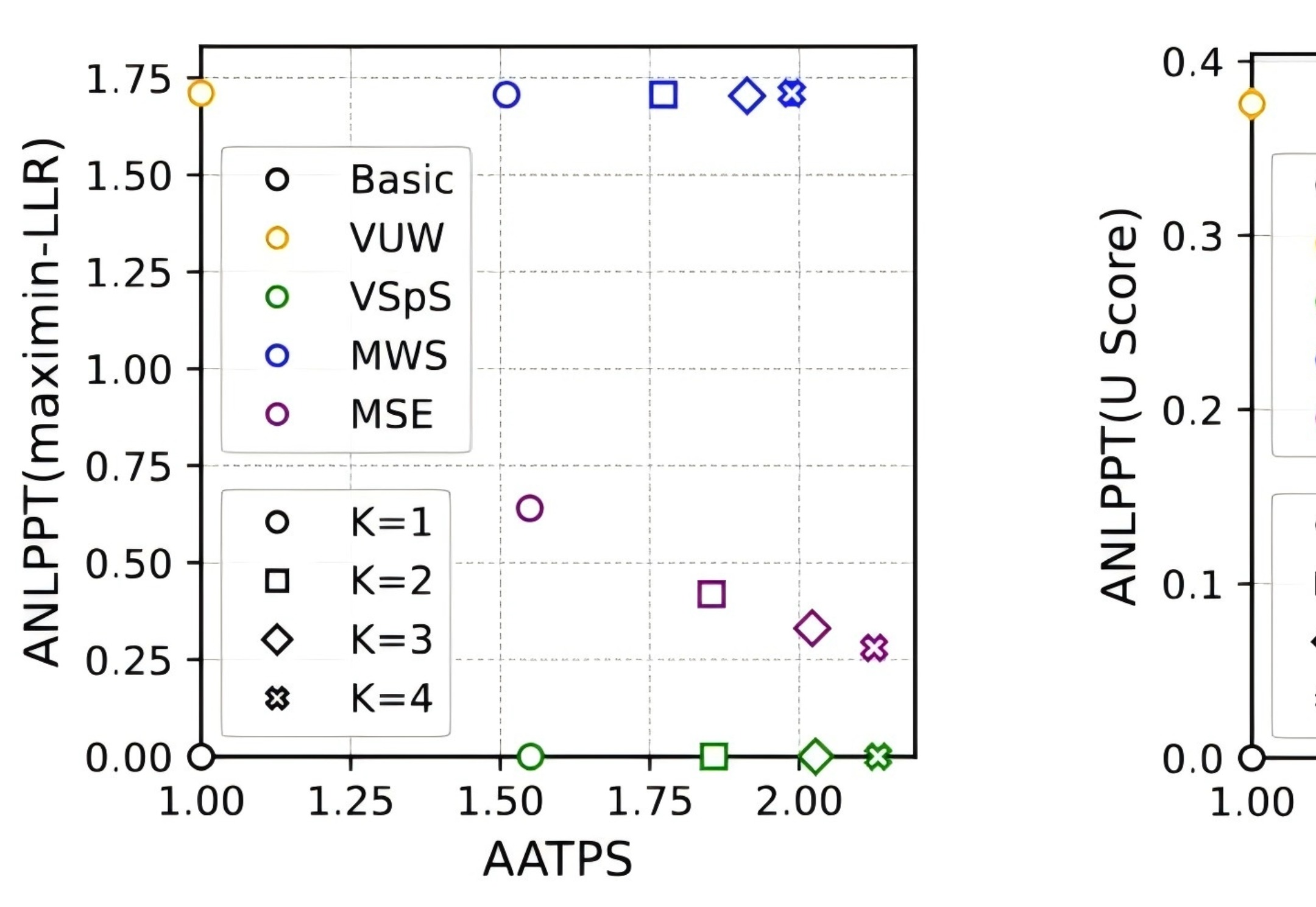
新的大语言模型(LLM)评估基准对于跟上大语言模型的快速发展至关重要。

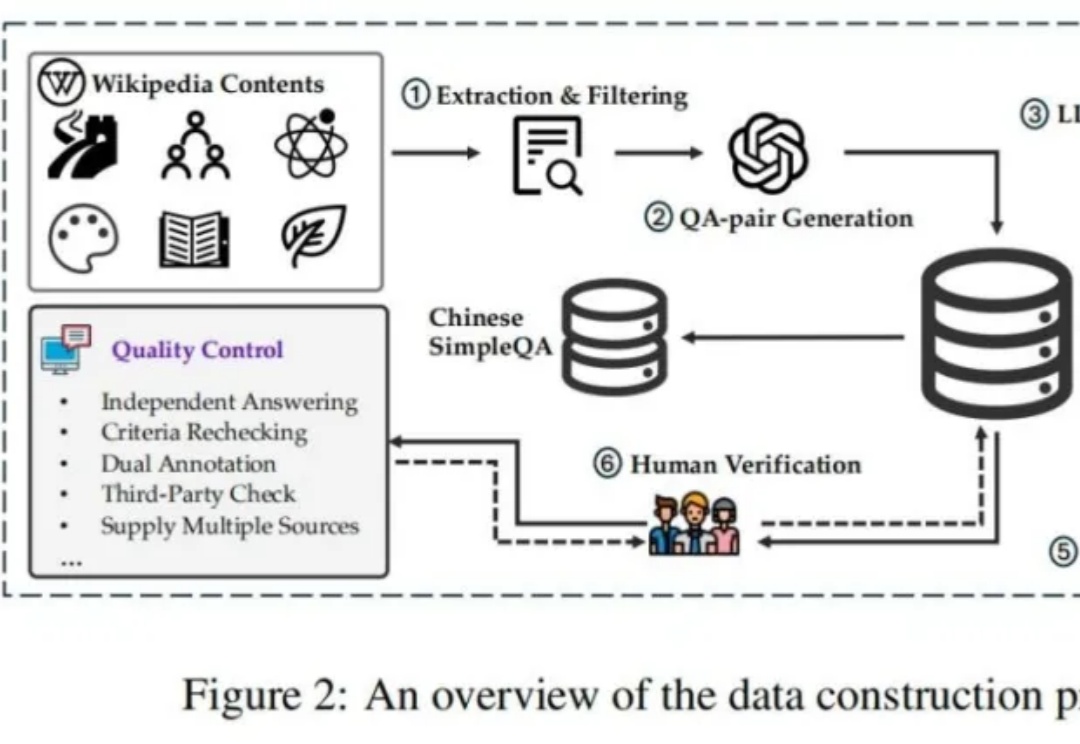
随着大语言模型(LLMs)在处理复杂任务中的广泛应用,高质量数据的获取变得尤为关键。为了确保模型能够准确理解并执行用户指令,模型必须依赖大量真实且多样化的数据进行后训练。然而,获取此类数据往往伴随着高昂的成本和数据稀缺性。因此,如何有效生成能够反映现实需求的高质量合成数据,成为了当前亟需解决的核心挑战。
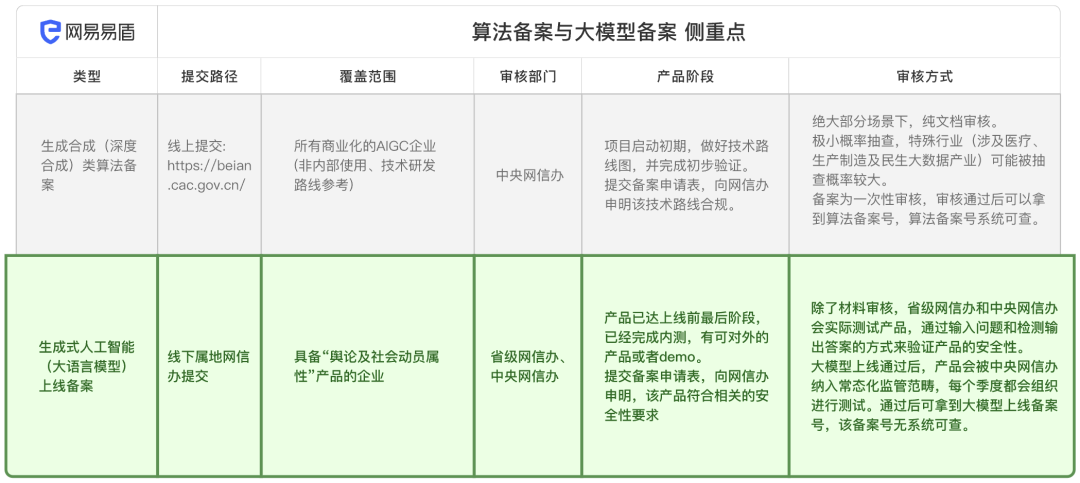
算法备案是所有AI从业者不得不迈过的门槛。这篇内容深入解读了中国《生成式人工智能服务安全基本要求》以及“生成式人工智能(大语言模型)上线备案”流程。

Infactory.ai作为一款专注于事实审查的AI搜索引擎,旨在通过使用大语言模型理解搜索意图,而非直接生成搜索结果,以此来提供准确、透明的搜索结果,从根本上避免了搜索结果的幻觉问题,同时依然能提高用户使用搜索工具的效率。