“太令”司法大模型,提供罪名预测及量刑建议
“太令”司法大模型,提供罪名预测及量刑建议大连理工大学信息检索研究室在始智AI wisemodel.cn开源社区发布了司法大模型--太令(TaiLing)1.0版,“太令”是专门为司法领域定制的大语言模型,其训练基础是庞大的通用中文语料库,并结合了裁判文书、合同、司法考试材料以及司法问答等专业司法数据进行深度训练。
来自主题: AI资讯
10575 点击 2024-03-28 11:17
 搜索
搜索
大连理工大学信息检索研究室在始智AI wisemodel.cn开源社区发布了司法大模型--太令(TaiLing)1.0版,“太令”是专门为司法领域定制的大语言模型,其训练基础是庞大的通用中文语料库,并结合了裁判文书、合同、司法考试材料以及司法问答等专业司法数据进行深度训练。

图是组织信息的一种有用方式,但LLMs主要是在常规文本上训练的。谷歌团队找到一种将图转换为LLMs可以理解的格式的方法,显著提高LLMs在图形问题上超过60%的准确性。

特斯拉创始人埃隆·马斯克推出了开源大语言模型Grok-1,该模型参数量高达3140亿,是迄今为止参数量最大的开源大模型。
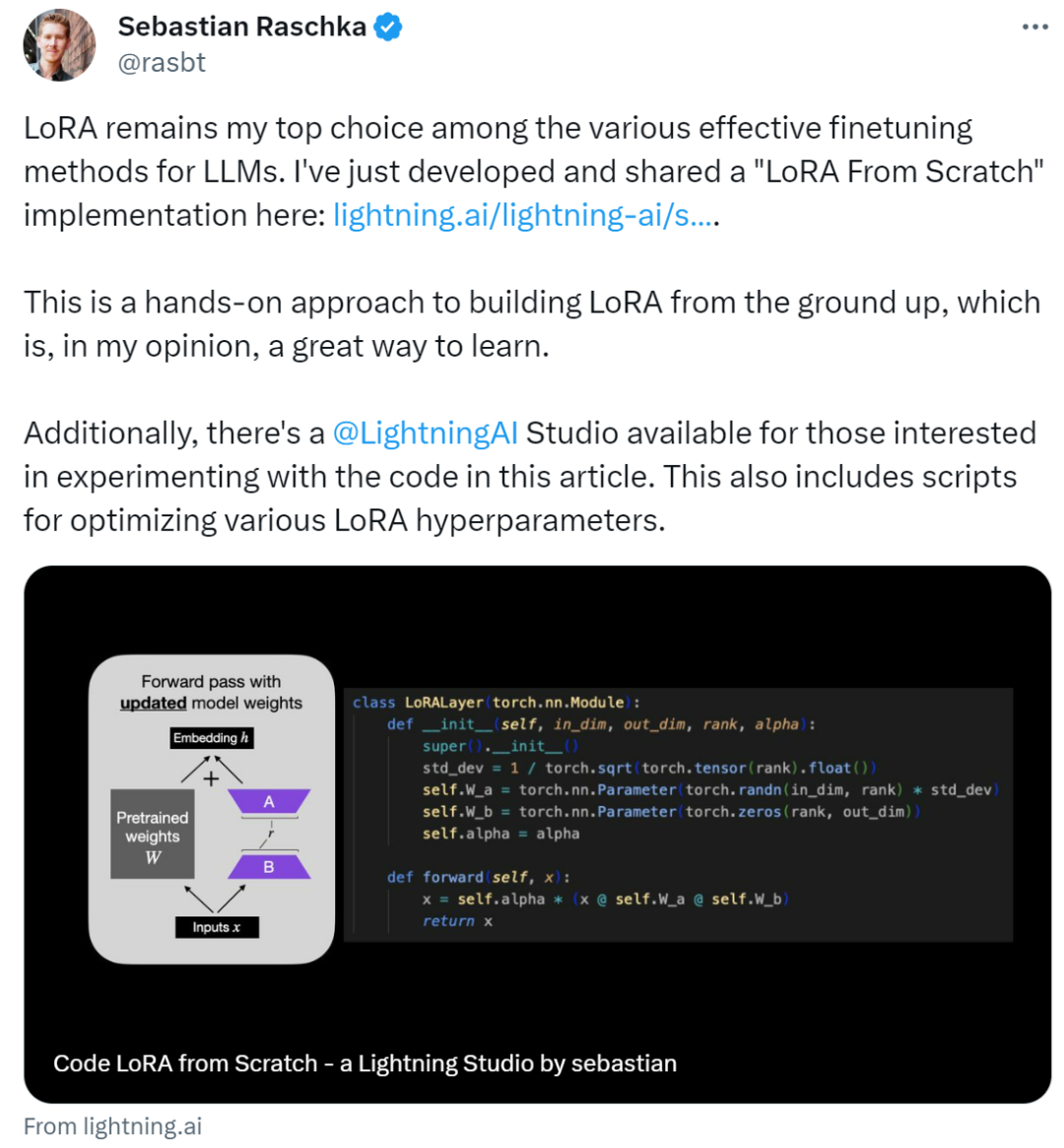
作者表示:在各种有效的 LLM 微调方法中,LoRA 仍然是他的首选。LoRA(Low-Rank Adaptation)作为一种用于微调 LLM(大语言模型)的流行技术,最初由来自微软的研究人员在论文《 LORA: LOW-RANK ADAPTATION OF LARGE LANGUAGE MODELS 》中提出。

早在 2020 年,陶大程团队就发布了《Knowledge Distillation: A Survey》,详细介绍了知识蒸馏在深度学习中的应用,主要用于模型压缩和加速。随着大语言模型的出现,知识蒸馏的作用范围不断扩大,逐渐扩展到了用于提升小模型的性能以及模型的自我提升。

随着大语言模型(LLM)的发展,很多研究发现LLM能够展现出稳定的人格特质,模仿人类细微的情绪与认知模式,还能辅助各种各样的社会科学仿真实验,为教育心理学、社会心理学、文化心理学、临床心理学、心理咨询等诸多心理学研究领域,提供了新的研究思路。

开源大语言模型宇宙又来了一个强劲对手。Transformer 作者参与创立的 Cohere 公司推出的大模型 Command-R 在可扩展、RAG和工具使用三个方面具有显著的优势。

近年来,大语言模型(LLMs)由于其通用的问题处理能力而引起了大量的关注。现有研究表明,适当的提示设计(prompt enginerring),例如思维链(Chain-of-Thoughts),可以解锁 LLM 在不同领域的强大能力。

本周四,美国 AI 创业公司 Inflection AI 正式发布新一代大语言模型 Inflection-2.5。仅用 40% 计算量,实现与 GPT-4 相媲美性能。
本周四,美国 AI 创业公司 Inflection AI 正式发布新一代大语言模型 Inflection-2.5。