ICLR 2026|早于DeepSeek Engram,STEM已重构Transformer「记忆」
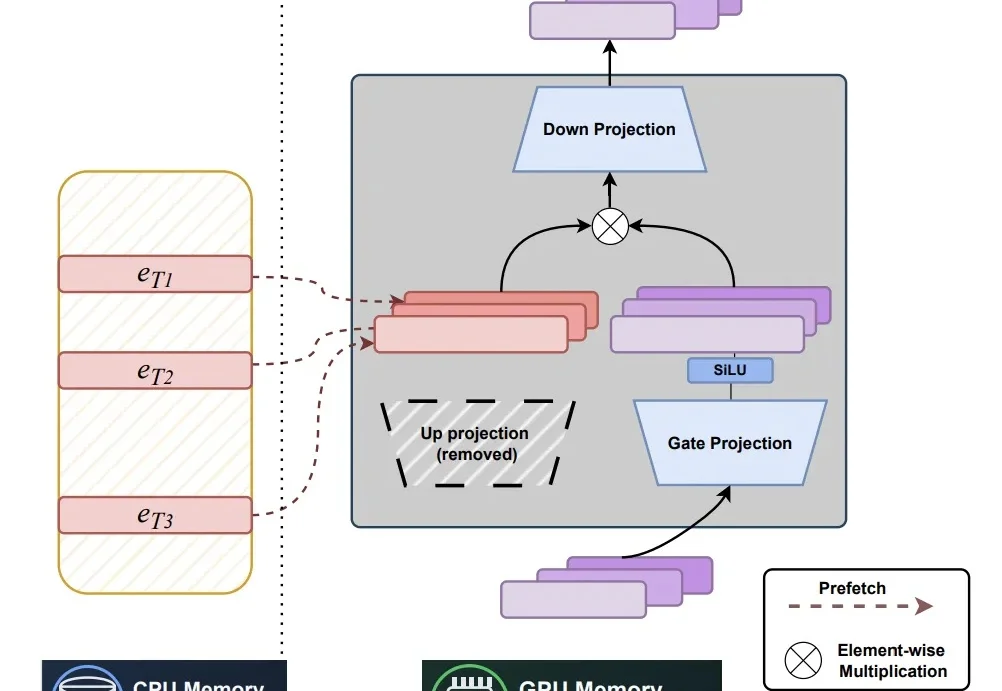
ICLR 2026|早于DeepSeek Engram,STEM已重构Transformer「记忆」近年来,随着大语言模型规模与知识密度不断提升,研究者开始重新思考一个更本质的问题:模型中的参数应如何被组织,才能更高效地充当「记忆」。
来自主题: AI技术研报
9022 点击 2026-03-10 09:31
 搜索
搜索
近年来,随着大语言模型规模与知识密度不断提升,研究者开始重新思考一个更本质的问题:模型中的参数应如何被组织,才能更高效地充当「记忆」。
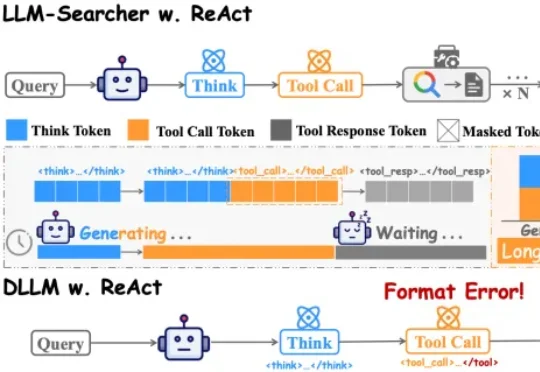
中国人民大学团队在论文DLLM-Searcher中,第一次让扩散大语言模型(dLLM)学会了这种“一心二用”的本事。目前主流的搜索Agent,不管是Search-R1还是R1Searcher,用的都是ReAct框架。这个框架的执行流程是严格串行的:
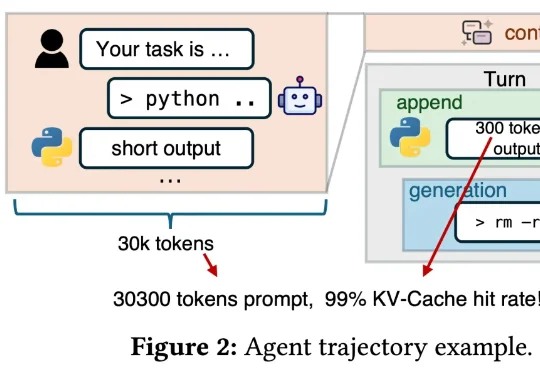
「DeepSeek V4 来了!」这样的消息是不是已经听烦了?总结来说,这篇新论文介绍了一个名为「DualPath」的创新推理系统,专门针对智能体工作负载下的大语言模型(LLM)推理性能进行优化。具体来讲,通过引入「双路径 KV-Cache 加载」机制,解决了在预填充 - 解码(PD)分离架构下,KV-Cache 读取负载不平衡的问题。

近期发表于 TMLR 的论文《Large Language Model Reasoning Failures》对这一问题进行了系统性梳理。该研究并未围绕 “模型是否真正理解” 展开哲学层面的争论,而是采取更加务实的路径 —— 通过整理现有文献中的失败现象,构建统一框架,系统分析大语言模型的推理短板。

没有让我们等待多久,阿里刚刚正式发布并开源了 Qwen3.5 系列模型,页面显示有两款模型,分别为最新大语言模型的 Qwen3.5-Plus,以及定位为开源系列旗舰的 Qwen3.5-397B-A17B。两者均支持文本处理与多模态任务。

以DeepSeek R1为代表的一系列基于强化学习(RLVR)微调的工作,显著提升了大语言模型的推理能力。但在这股浪潮背后,强化微调的代价却高得惊人。
来自上海交通大学、清华大学、微软研究院、麻省理工学院(MIT)、上海 AI Lab、小红书、阿里巴巴、港科大(广州)等机构的研究团队,系统梳理了近年来大语言模型在数据准备流程中的角色变化,试图回答一个业界关心的问题:LLM 能否成为下一代数据管道的「智能语义中枢」,彻底重构数据准备的范式?
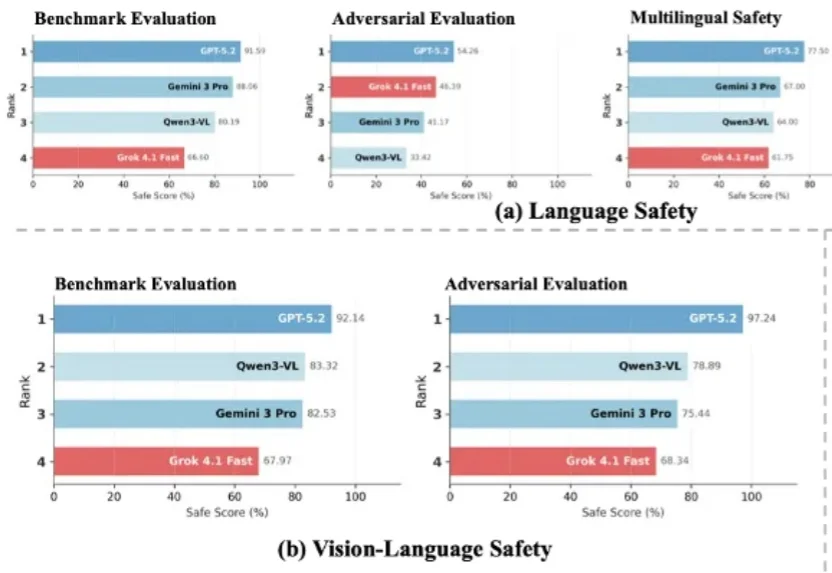
随着大语言模型加速迈向多模态与智能体形态,传统以单一维度为主的安全评估体系已难以覆盖真实世界中的复杂风险图景。在模型能力持续跃升的 2026 年,开发者与用户也愈发关注一个核心问题:前沿大模型的安全性,到底如何?
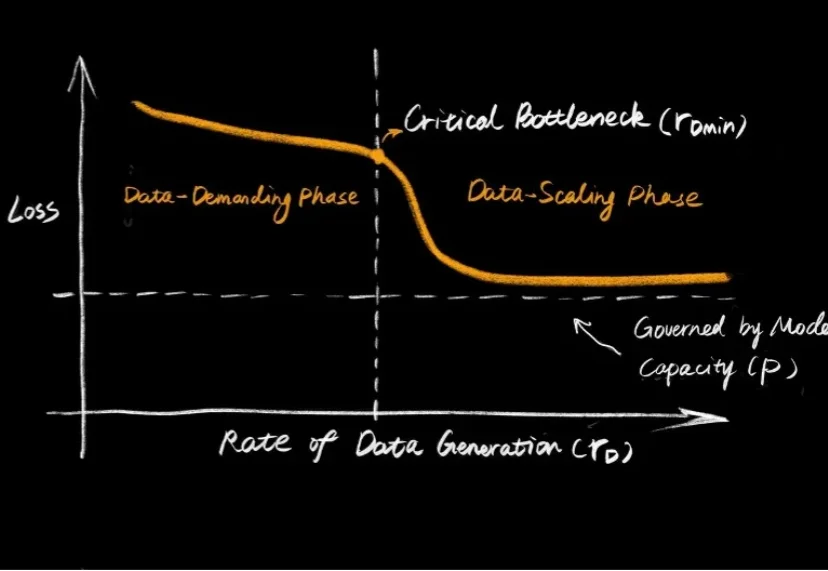
大语言模型的爆发,让大家见证了 Scaling Law 的威力:只要数据够多、算力够猛,智能似乎就会自动涌现。但在机器人领域,这个公式似乎失效了。

刚刚,AI医疗新突破,来自谷歌!这一次,他们直接瞄准了真实临床环境的痛点。为此,谷歌祭出了最新模型MedGemma 1.5,找到了破局答案。相较于此前的MedGemma 1.5,MedGemma 1.5在多模态应用上实现重大突破,融合了: