
LLM距离AGI只差一层:斯坦福研究颠覆「模式匹配」观点
LLM距离AGI只差一层:斯坦福研究颠覆「模式匹配」观点有关大语言模型的理论基础,可能要出现一些改变了。
来自主题: AI技术研报
10677 点击 2025-12-11 10:10
 搜索
搜索
有关大语言模型的理论基础,可能要出现一些改变了。
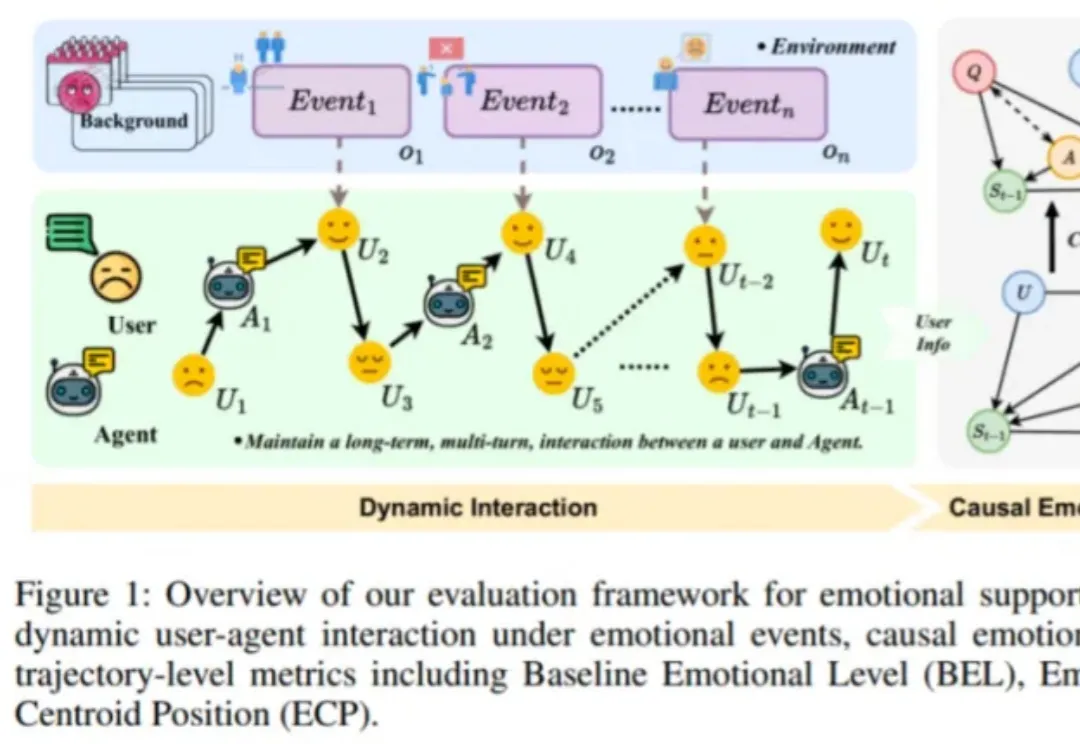
近日,由趣丸科技与北京大学软件工程国家工程研究中心共同发表的《Detecting Emotional Dynamic Trajectories: An Evaluation Framework for Emotional Support in Language Models(检测情感动态轨迹:大语言模型情感支持的评估框架)》论文,获 AAAI 2026 录用。
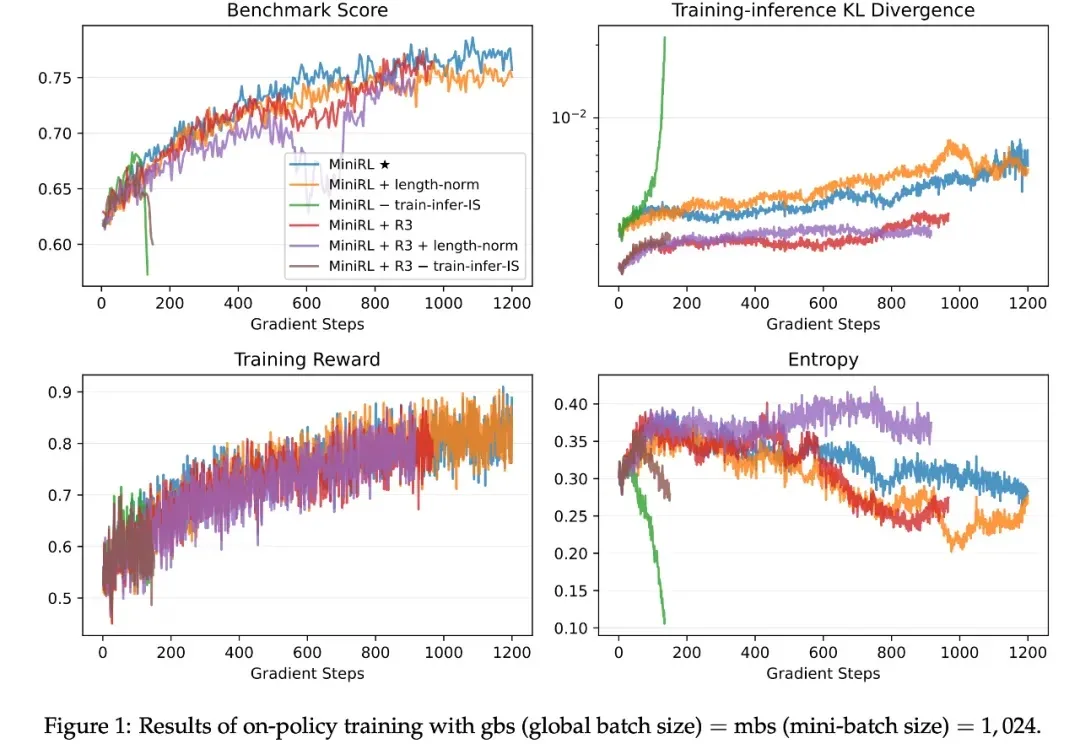
如今,强化学习(RL)已成为提升大语言模型(LLM)复杂推理与解题能力的关键技术范式,而稳定的训练过程对于成功扩展 RL 至关重要。由于语言具有强烈的上下文属性,LLM 的 RL 通常依赖序列级奖励 —— 即根据完整生成序列给一个标量分数。
关于如何避免让大语言模型产生幻觉,一直以来的相关研究都非常多。

2025 年 12 月,硅谷风险投资机构 Andreessen Horowitz(简称 a16z)与 AI 推理服务平台 OpenRouter 联合发布了一份名为《State of AI》的研究报告。这份报告基于 OpenRouter 平台上超过 100 万亿 token 的真实用户交互数据,试图呈现过去一年间大语言模型在实际应用中的真实状态。

在人工智能快速发展的今天,大语言模型已经深入到我们工作和生活的方方面面。然而,如何让AI生成的内容更加可信、可追溯, 一直是学术界和工业界关注的焦点问题。想象一下,当你向ChatGPT提问时,它不仅给出答案,还能像学术论文一样标注每句话的信息来源——这就是"溯源大语言模型"要解决的核心问题。

斯坦福和MIT的研究团队推出了一种新的AI智能体推理框架ReCAP,在长上下文任务中全面超越了现有的主流框架ReAct,性能提升显著。ReCAP通过独特的递归树结构和三大机制,解决了大语言模型在复杂任务中常见的目标漂移、上下文断层和成本爆炸等问题。

随着大语言模型(LLM)的商业价值快速提升,其昂贵的训练成本使得模型版权保护(IP Protection)成为业界关注的焦点。然而,现有模型版权验证手段(如模型指纹)往往忽略一个关键威胁:攻击者一旦直接窃取模型权重,即拥有对模型的完全控制权,能够逆向指纹 / 水印,或通过修改输出内容绕过指纹验证。

随着大语言模型与开发工具链的深度融合,命令行终端正被重塑为开发者的AI协作界面。本文以 Google gemini-cli 为范本,通过源码解构,系统性分析其 Agent 内核、ReAct 工作流、工具调用与上下文管理等核心模块的实现原理。为希望构建终端 Agent 的开发者,提供工程实现的系统化参考。

在大语言模型(LLM)的研究浪潮中,绝大多数工作都聚焦于优化模型的输出分布 —— 扩大模型规模、强化分布学习、优化奖励信号…… 然而,如何将这些输出分布真正转化为高质量的生成结果 —— 即解码(decoding)阶段,却没有得到足够的重视。