Pika 2.0横扫Sora惊艳全网,一键颠覆广告业!上传自拍秒变好莱坞大片,和明星同框不是梦
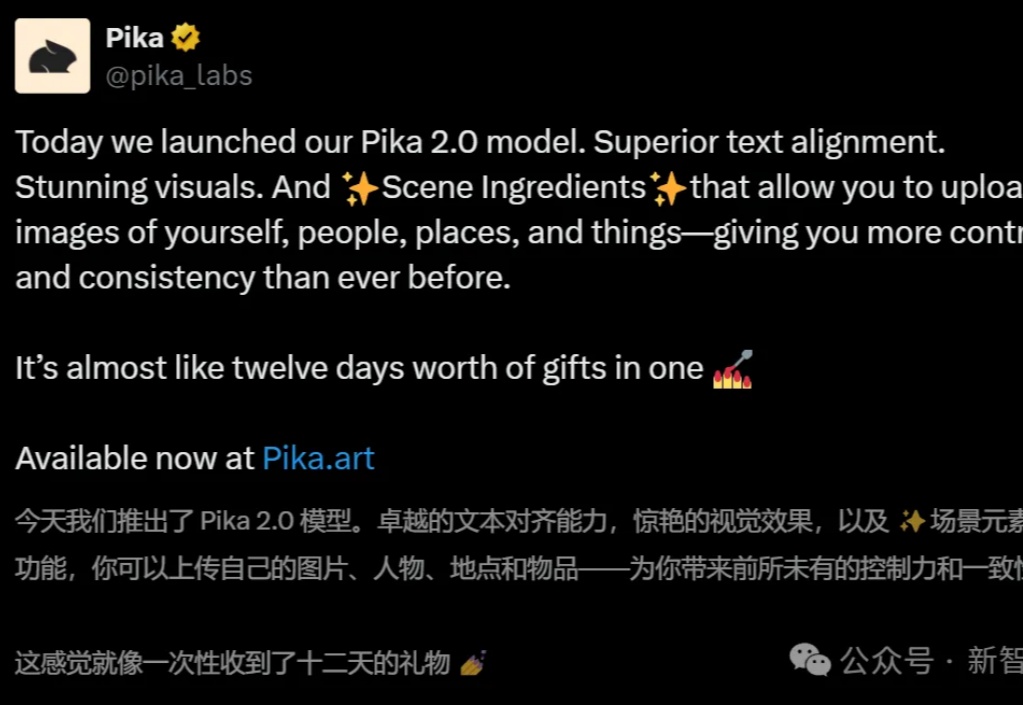
Pika 2.0横扫Sora惊艳全网,一键颠覆广告业!上传自拍秒变好莱坞大片,和明星同框不是梦斯坦福天才少女,让AI视频的格局再次颠覆!Pika 2.0上线不久即引发全网狂潮,强大场景元素功能、超强文本对齐、深刻物理学理解,让它在AI视频大混战中脱颖而出,效果不输谷歌Veo 2.0。网友们疯狂实测,人手一部广告大片。
来自主题: AI资讯
7677 点击 2024-12-18 20:32