
Ilya错了,预训练没结束!LeCun等反击,「小模型时代」让奥特曼预言成真
Ilya错了,预训练没结束!LeCun等反击,「小模型时代」让奥特曼预言成真Ilya「预训练结束了」言论一出,圈内哗然。谷歌大佬Logan Klipatrick和LeCun站出来反对说:预训练还没结束!Scaling Law真的崩了吗?Epoch AI发布报告称,我们已经进入「小模型」周期,但下一代依然会更大。
来自主题: AI资讯
9189 点击 2024-12-17 10:02
 搜索
搜索
Ilya「预训练结束了」言论一出,圈内哗然。谷歌大佬Logan Klipatrick和LeCun站出来反对说:预训练还没结束!Scaling Law真的崩了吗?Epoch AI发布报告称,我们已经进入「小模型」周期,但下一代依然会更大。
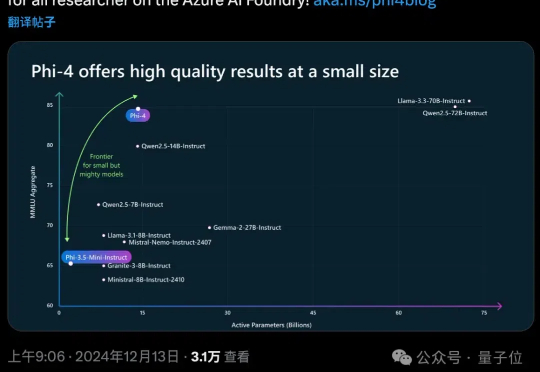
OpenAI谷歌天天刷流量,微软也坐不住了,推出最新小模型Phi-4。 参数量仅14B,MMLU性能就和Llama 3.3/ Qwen2.5等70B级别大模型坐一桌。
大模型未必最优,小模型也有机会 前几天刷B站的时候,碰到了一个很抽象很难评的事情——一个科普up主的视频里,夹带了一个AI产品的广告。

自从 Chatgpt 诞生以来,LLM(大语言模型)的参数量似乎就成为了各个公司的竞赛指标。GPT-1 参数量为 1.17 亿(1.17M),而它的第四代 GPT-4 参数量已经刷新到了 1.8 万亿(1800B)。
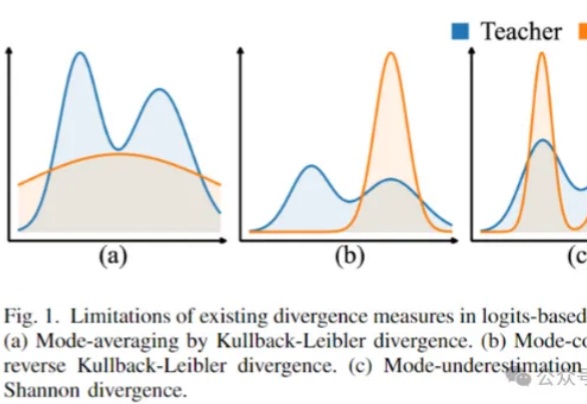
用大模型“蒸馏”小模型,有新招了!
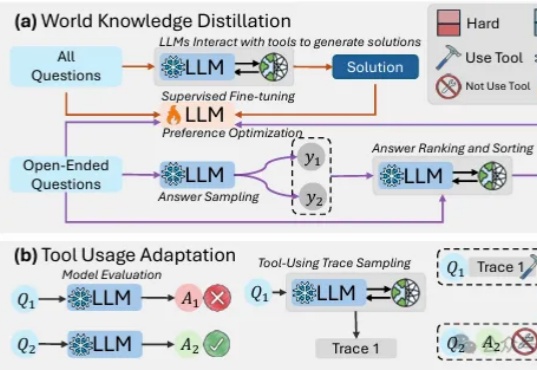
最近,一支来自UCSD和清华的研究团队提出了一种全新的微调方法。经过这种微调后,一个仅80亿参数的小模型,在科学问题上也能和GPT-4o一较高下!或许,单纯地卷AI计算能力并不是唯一的出路。
我们对小型语言模型的增强方法、已存在的小模型、应用、与 LLMs 的协作、以及可信赖性方面进行了详细调查。

生成式人工智能GenAI是否存在泡沫?这个问题日益成为业界热议的焦点。目前,全球对AI基础设施的投资已到了癫狂的成千上万亿美元的规模,然而大模型如何实现盈利却始终没有一个明确的答案。

商汤科技联合创始人、执行董事徐冰出席香港金融科技周活动,并与前福布斯记者Olivia Kinghorst做现场对谈。在近20分钟的对话中,双方讨论了AI云平台市场趋势、投资判断、超级应用、竞争格局等话题。

来自英伟达、CMU、UC伯克利等的全华人团队提出一个全新的人形机器人通用的全身控制器HOVER,仅用一个1.5M参数模型就可以控制人形机器人的身体。人形机器人的运动和操作之前只是外表看起来类人,现在有了HOVER,连底层运动逻辑都可以类人了!