
5.4万亿!英伟达成AI最大地主,大模型巨头沦为算力佃农
5.4万亿!英伟达成AI最大地主,大模型巨头沦为算力佃农当AI神话被账本照亮,最刺眼的真相终于浮出水面。退潮时刻,狂欢结束。探照灯打过来,谁在裸泳,一目了然。
来自主题: AI资讯
7003 点击 2026-06-22 09:15
 搜索
搜索
当AI神话被账本照亮,最刺眼的真相终于浮出水面。退潮时刻,狂欢结束。探照灯打过来,谁在裸泳,一目了然。

自从AI爆发以来,所有人都在追问同一个问题:AI时代的护城河到底是什么?

每月一两千,把数字员工用到起飞。
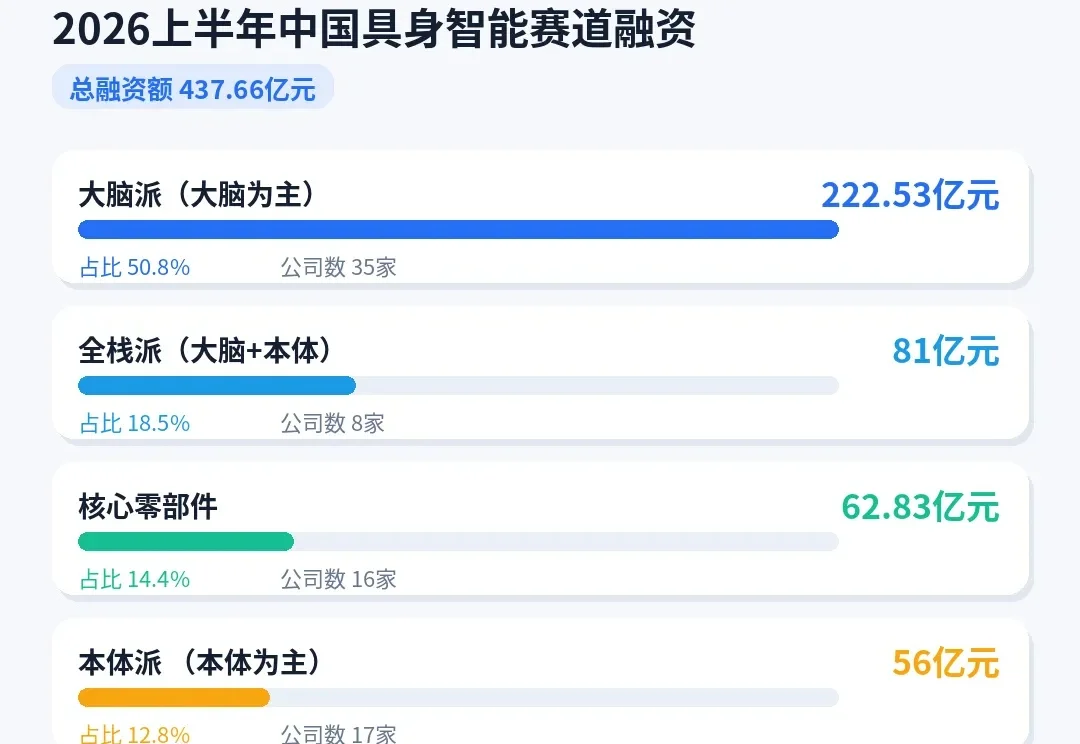
具身智能领域的资本,正在涌向机器人的“大脑”。

就在最近,OpenAI扔出一篇重磅论文。他们发现,只教AI好好看病,它写代码居然也不作弊了。方法简单到离谱:拿5%的训练数据,教模型在回答健康问题时诚实、谨慎、知错能改。

刚刚, OpenAI、Google DeepMind、Anthropic三大AI巨头CEO与G7领导人在法国阿尔卑斯山共进工作午餐,历史首次。上一次这些领导人坐在一起,讨论的是二毛、中东、全球供应链这些问题。现在AI公司的CEO被请到了同一张桌子上。
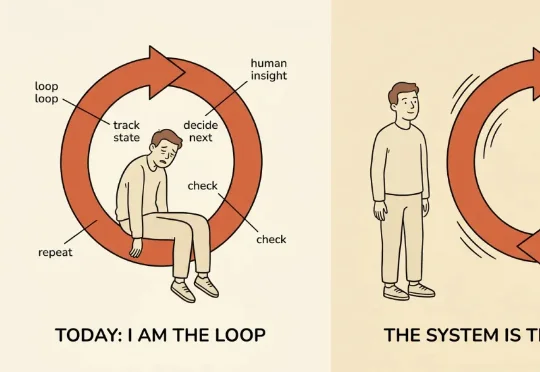
OpenAI 的 tevfik 写了篇关于 loop engineering 的文章,开头那句我读完顿了一下。他说,他和 coding agent 协作,到现在大多还是同一个流程:我解释一个任务,等结果,审一遍,再发下一条指令。代码是 agent 写的,但我在后台还干着另一份活——我记着发生了什么、决定下一步做什么、判断这事到底完成没。
网购的快递被人偷了,联系客服,客服系统显示,预计等待时间 25 分钟。 换作以前,这意味着我们要么盯着聊天窗口发呆,要么开着网页干别的事,同时隔几分钟切回来看看排到没有,不然一不小心退出去又要重新排队

近期,在 LangChain 举办的智能体大会 Interrupt 上,吴恩达与 LangChain 创始人 Harrison Chase 进行了一场关于 AI Agent 的对谈。整场交流的核心并不是简单讨论 Agent 有多强,而是围绕一个更现实的问题展开:当 AI Agent 让软件开发变快之后,真正的瓶颈会转移到哪里?

2026 年 6 月 19 日,John Jumper 在 X 上宣布,自己将离开工作近九年的 Google DeepMind,在短暂休整后加入 Anthropic。随后,DeepMind CEO Demis Hassabis 也公开回复,感谢 Jumper 对 AlphaFold 和 AI for Science 的贡献。