
「9 块 9」AI 复活亲人,科技奇迹还是「情感幻觉」?
「9 块 9」AI 复活亲人,科技奇迹还是「情感幻觉」?清明节到了,在过去上百年里,人们扫墓、烧纸、磕头、摆上供品、再对着墓碑诉说,希望借节日的仪式感,让思念跨越阴阳。
来自主题: AI资讯
8566 点击 2025-04-05 14:26
 搜索
搜索
清明节到了,在过去上百年里,人们扫墓、烧纸、磕头、摆上供品、再对着墓碑诉说,希望借节日的仪式感,让思念跨越阴阳。

幻觉(Hallucination),即生成事实错误或不一致的信息,已成为视觉-语言模型 (VLMs)可靠性面临的核心挑战。随着VLMs在自动驾驶、医疗诊断等关键领域的广泛应用,幻觉问题因其潜在的重大后果而备受关注。

这个春天,数以万计的散户正在经历一场魔幻的AI炒股实验:他们对着DeepSeek等AI工具虔诚叩问财富密码,却在K线图的剧烈波动中落入“裤衩亏没”的荒诞境地。
相比让Alexa重新焕发生机,AI可能会产生的幻觉或只是个小问题。

2025 年 3 月 5 日,佳士得拍卖行 “增强智能(Augmented Intelligence)”落下帷幕。这场聚焦 AI 艺术的专场拍卖以728,784 美元总成交额收官,34 件拍品中 28 件成交,成交率达 82%。其中,土耳其裔美国艺术家 Refik Anadol 的《机器幻觉 —— 国际空间站之梦 ——A》以27.7 万美元成为全场最高价拍品。

人类实现AGI之前,在技术、商业、治理方面仍然存在诸多问题——“人与AI能否共处” “算力叙事是否依然奏效” “开源有多大商业价值”等,腾讯科技策划《AGI之路》系列直播,联合合作伙伴,特邀专家、学者直播解读相关议题,对齐AGI共识,探寻AGI可行之路。

2025年2月,如果不是长期从事人口研究的中国人民大学教授李婷的公开辟谣,很多人都真诚地相信了一组数据——“中国80后累计死亡率为5.20%”。

只有卖课的赚了。

近些日子,老詹突然“爱”上了DeepSeeK,简直有点相见恨晚的感觉!几乎每天都摆弄这玩意儿。然而,处着处着,我发现,这家伙有点靠不住!最大的问题是,说假话!
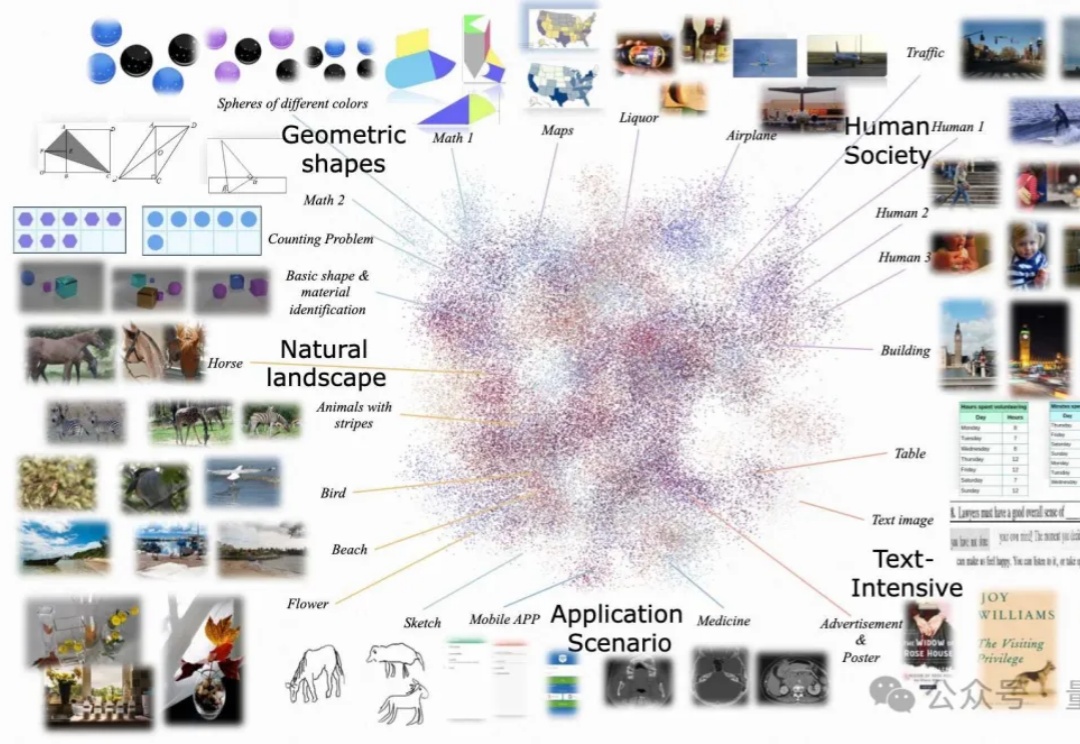
尽管多模态大语言模型(MLLMs)取得了显著的进展,但现有的先进模型仍然缺乏与人类偏好的充分对齐。这一差距的存在主要是因为现有的对齐研究多集中于某些特定领域(例如减少幻觉问题),是否与人类偏好对齐可以全面提升MLLM的各种能力仍是一个未知数。