阿里千问QwQ-32B推理模型开源,比肩671B满血DeepSeek-R1!笔记本就能跑
阿里千问QwQ-32B推理模型开源,比肩671B满血DeepSeek-R1!笔记本就能跑仅用32B,就击败o1-mini追平671B满血版DeepSeek-R1!阿里深夜重磅发布的QwQ-32B,再次让全球开发者陷入狂欢:消费级显卡就能跑,还一下子干到推理模型天花板!
来自主题: AI技术研报
7407 点击 2025-03-07 10:28
 搜索
搜索
仅用32B,就击败o1-mini追平671B满血版DeepSeek-R1!阿里深夜重磅发布的QwQ-32B,再次让全球开发者陷入狂欢:消费级显卡就能跑,还一下子干到推理模型天花板!

今夜,Manus发布之后,随之而来赶到战场的,是阿里。
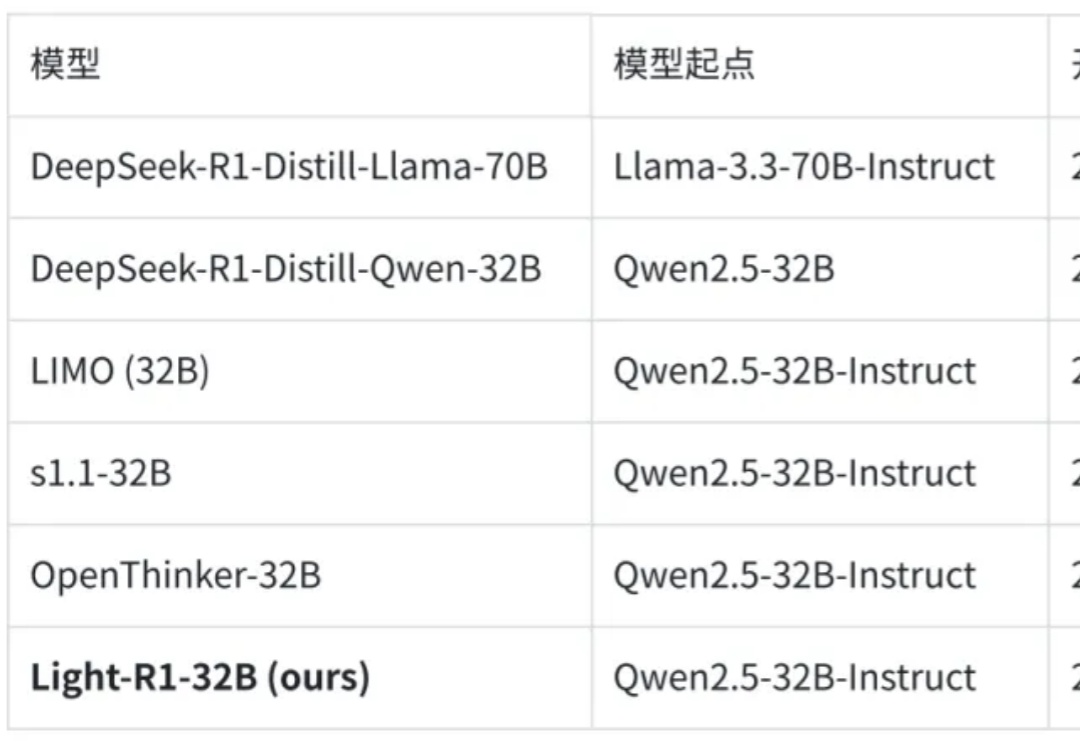
2025 年 3 月 4 日,360 智脑开源了 Light-R1-32B 模型,以及全部训练数据、代码。仅需 12 台 H800 上 6 小时即可训练完成,从没有长思维链的 Qwen2.5-32B-Instruct 出发,仅使用 7 万条数学数据训练,得到 Light-R1-32B
开源模型,还是得看杭州。
美国AI云服务商Together AI宣布完成3.05亿美元B轮融资,估值高达33亿美元!该公司押注开源模型,提供包括DeepSeek-R1在内的200多个模型API服务,并出租GPU算力,年收入已超1亿美元。
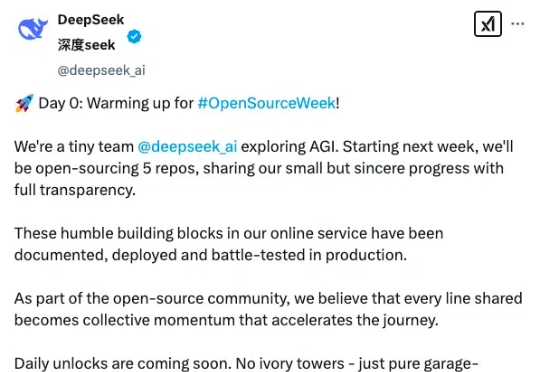
就在刚刚,DeepSeek 在 X 平台发文宣布,将在下周(OpenSourceWeek 开源周)连续五天开源 5 个项目的代码库。

刚刚,阶跃星辰联合吉利汽车集团,开源了两款多模态大模型!新模型共2款:全球范围内参数量最大的开源视频生成模型Step-Video-T2V行业内首款产品级开源语音交互大模型Step-Audio多模态卷王开始开源多模态模型,其中Step-Video-T2V采用的还是最为开放宽松的MIT开源协议,可任意编辑和商业应用。

继昨天决定免费之后,百度刚刚又发布一则重磅消息——下一代文心模型,决定开源!而且官宣内容只有一句话(字少事大的感觉):我们将在未来几个月中陆续推出文心大模型4.5系列,并于6月30日起正式开源。
DeepSeek火了之后,知名科技主播Lex Fridman,找了两位嘉宾,从 DeepSeek 及其开源模型 V3 和 R1 谈到了 AI 发展的地缘政治竞争,特别是中美在 AI 芯⽚与技术出⼝管制上的博弈。5 个小时的对谈,基于「赛博禅心」的翻译版本,我们精选出了5 万字,基本把 DeepSeek 的创新、目前 AI 的算力问题、AI 训练和蒸馏、以及产品落地等都聊透了。建议收藏后仔细阅读。

在柏林工业大学的一场圆桌对话当中,奥特曼再一次谈到了DeepSeek,并大赞开源模型对世界的贡献。对话中,奥特曼还发表了对AGI的最新看法,透露了十足的信心,他认为,虽然会遇到阻碍和挑战,但他相信人类终将实现AGI。