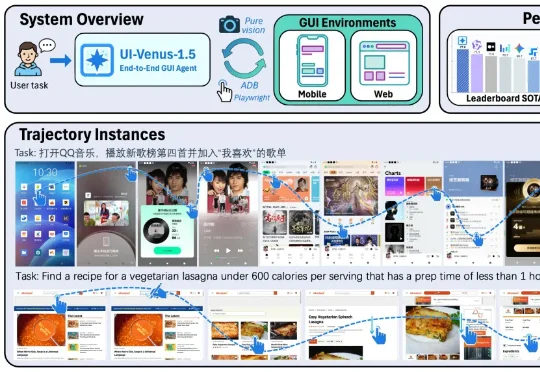
霸榜SOTA,蚂蚁开源UI-Venus-1.5,GUI智能体办事时代加速到来
霸榜SOTA,蚂蚁开源UI-Venus-1.5,GUI智能体办事时代加速到来GUI 智能体最近卷到什么程度了?Claude、OpenAI Agent 及各类开源模型你方唱罢我登场,但若真想让 AI 成为 「能在手机和网页上稳定干活的助手」,仍绕不开三大现实难题:
来自主题: AI技术研报
9431 点击 2026-02-20 13:10
 搜索
搜索
GUI 智能体最近卷到什么程度了?Claude、OpenAI Agent 及各类开源模型你方唱罢我登场,但若真想让 AI 成为 「能在手机和网页上稳定干活的助手」,仍绕不开三大现实难题:
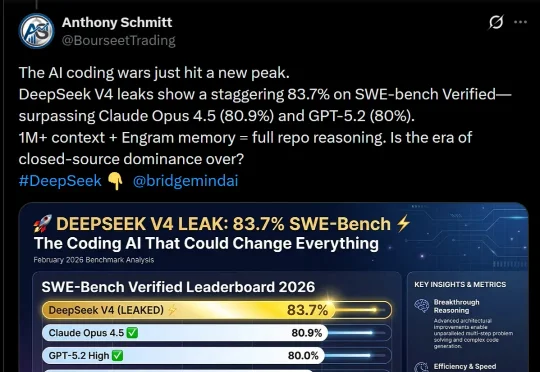
DeepSeek V4,据说明天就要上线了?这是首个匹敌顶尖闭源模型的开源模型,被网友评为「一鲸落万物生」。泄露的基准测试显示,它在SWE-bench Verified上取得了83.7%,已经超越Opus 4.5和GPT-5.2!
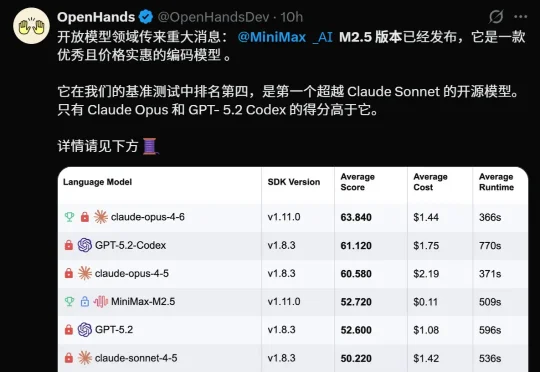
开源模型新王 MiniMax M2.5 震撼降临:M2.5 编码性能逼平 Claude Opus 4.6,价格却只有 1/20;1 美金 / 小时,这种尺寸和性能的模型,才能在算力短缺的时代不降智不卡顿,持续提供最好体验,成为最终王者!
这个国产开源模型,把多模态玩出了“魔法”感。

开源模型同样能承担复杂工程任务。

深夜,GLM-5来了。
最强的大模型,已经把scaling卷到了一个新维度:百万级上下文。
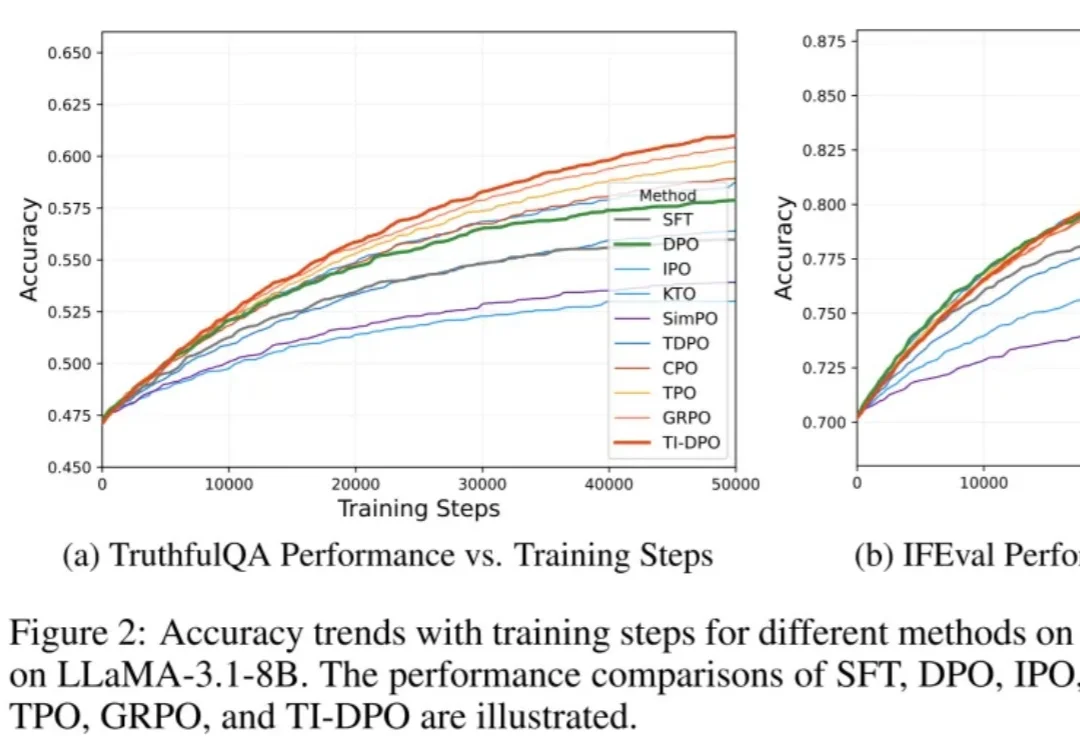
在当今的大模型后训练(Post-training)阶段,DPO(直接偏好优化) 凭借其无需训练独立 Reward Model 的优雅设计和高效性,成功取代 PPO 成为业界的 「版本之子」,被广泛应用于 Llama-3、Mistral 等顶流开源模型的对齐中。

今日,阶跃星辰Step 3.5 Flash开源并上线,该模型在Agent场景和数学任务上能力逼近闭源模型,能够胜任复杂、长链条任务,是阶跃星辰迄今最强的开源基座模型。就在上周,阶跃星辰宣布由旷视科技联合创始人、千里科技董事长印奇正式出任董事长,并完成华勤、腾讯等参投的超50亿元B+轮融资。这也是印奇履新后,阶跃星辰在开源模型领域的首个大动作。
Clawdbot痛失本名改叫Moltbot后,热度丝毫不减。