
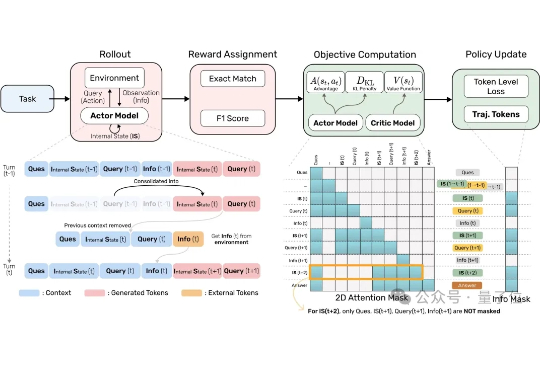
突破Agent长程推理效率瓶颈!MIT&新加坡国立联合推出强化学习新训练方法
突破Agent长程推理效率瓶颈!MIT&新加坡国立联合推出强化学习新训练方法AI Agent正在被要求处理越来越多复杂的任务。 但当它要不停地查资料、跳页面、筛选信息时,显存狂飙、算力吃紧的问题就来了。
来自主题: AI技术研报
6541 点击 2025-08-21 11:33
AI Agent正在被要求处理越来越多复杂的任务。 但当它要不停地查资料、跳页面、筛选信息时,显存狂飙、算力吃紧的问题就来了。
哦豁,OpenAI奥特曼又痛失一员大将。 Kevin Lu,领导4o-mini发布,并参与o1-mini、o3发布,主要研究强化学习、小模型和合成数据。
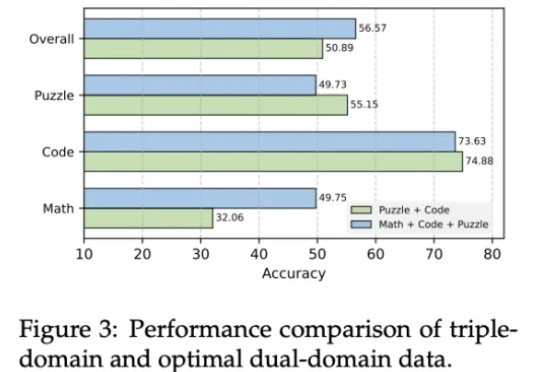
近年来,AI大模型在数学计算、逻辑推理和代码生成领域的推理能力取得了显著突破。特别是DeepSeek-R1等先进模型的出现,可验证强化学习(RLVR)技术展现出强大的性能提升潜力。

首个开源多模态Deep Research Agent来了。整合了网页浏览、图像搜索、代码解释器、内部 OCR 等多种工具,通过全自动流程生成高质量推理轨迹,并用冷启动微调和强化学习优化决策,使模型在任务中能自主选择合适的工具组合和推理路径。
前些天,OpenAI 少见地 Open 了一回,发布了两个推理模型 gpt-oss-120b 和 gpt-oss-20b。

强化学习(RL)是锻造当今顶尖大模型(如 OpenAI o 系列、DeepSeek-R1、Gemini 2.5、Grok 4、GPT-5)推理能力与对齐的核心 “武器”,但它也像一把双刃剑,常常导致模型行为脆弱、风格突变,甚至出现 “欺骗性对齐”、“失控” 等危险倾向。
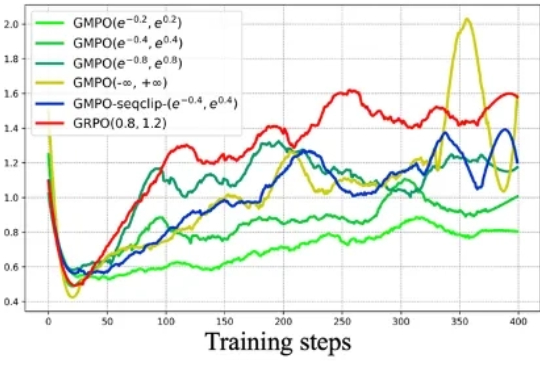
近年来,强化学习(RL)在大型语言模型(LLM)的微调过程中,尤其是在推理能力提升方面,取得了显著的成效。传统的强化学习方法,如近端策略优化(Proximal Policy Optimization,PPO)及其变种,包括组相对策略优化(Group Relative Policy Optimization,GRPO),在处理复杂推理任务时表现出了强大的潜力。
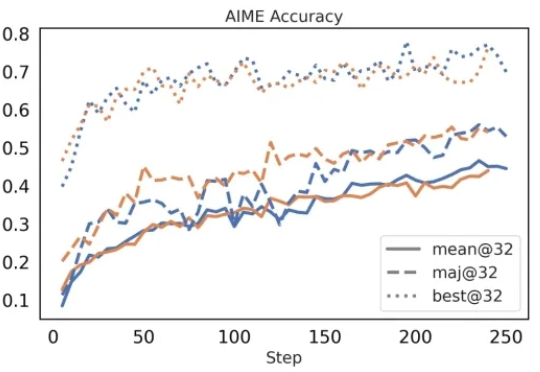
在今年三月份,清华 AIR 和字节联合 SIA Lab 发布了 DAPO,即 Decoupled Clip and Dynamic sAmpling Policy Optimization(解耦剪辑和动态采样策略优化)。
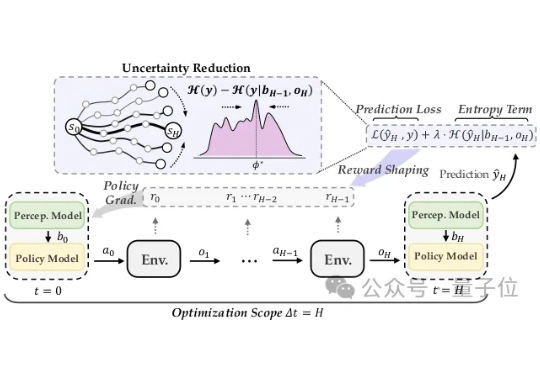
面对对抗攻击,具身智能体除了被动防范,也能主动出击! 在人类视觉系统启发下,清华朱军团队在TPMAI 2025中提出了强化学习驱动的主动防御框架REIN-EAD。

在图像生成领域,自回归(Autoregressive, AR)模型与扩散(Diffusion)模型之间的技术路线之争始终未曾停歇。大语言模型(LLM)凭借其基于「预测下一个词元」的优雅范式,已在文本生成领域奠定了不可撼动的地位。