
Prompt的尽头,居然是MBTI。
Prompt的尽头,居然是MBTI。论文的标题很学术,叫《心理学增强AI智能体》但是大白话翻译一下就是,想要让大模型更好地完成任务,你们可能不需要那些动辄几百上千字的复杂Prompt,不需要什么思维链、思维图谱,甚至不需要那些精巧的指令。
来自主题: AI技术研报
8617 点击 2025-09-23 10:08
 搜索
搜索
论文的标题很学术,叫《心理学增强AI智能体》但是大白话翻译一下就是,想要让大模型更好地完成任务,你们可能不需要那些动辄几百上千字的复杂Prompt,不需要什么思维链、思维图谱,甚至不需要那些精巧的指令。

近年来,大语言模型(LLMs)在复杂推理任务上的能力突飞猛进,这在很大程度上得益于深度思考的策略,即通过增加测试时(test-time)的计算量,让模型生成更长的思维链(Chain-of-Thought)。

国产自研开源模型,让模型不用在快思考和慢思考间二选一了!

您对“思维链”(Chain-of-Thought)肯定不陌生,从最早的GPT-o1到后来震惊世界的Deepseek-R1,它通过让模型输出详细的思考步骤,确实解决了许多复杂的推理问题。但您肯定也为它那冗长的输出、高昂的API费用和感人的延迟头疼过,这些在产品落地时都是实实在在的阻碍。
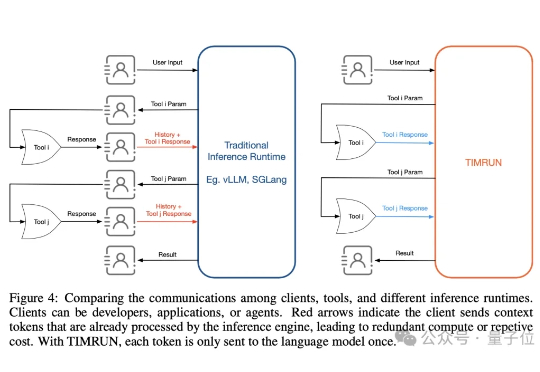
大模型的记忆墙,被MIT撬开了一道口子。 MIT等机构最新提出了一种新架构,让推理大模型的思考长度突破物理限制,理论上可以无限延伸。 这个新架构名叫Thread Inference Model,简称TIM。
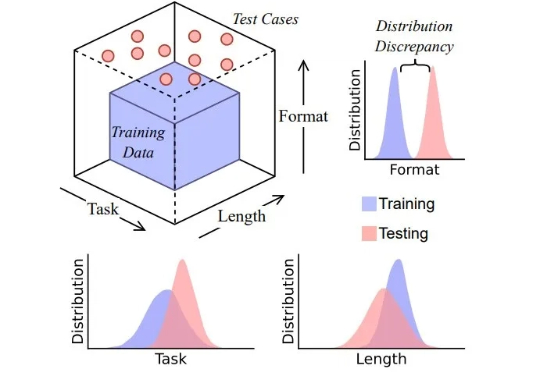
思维链 (CoT) 提示技术常被认为是让大模型分步思考的关键手段,通过在输入中加入「Let’s think step by step」等提示,模型会生成类似人类的中间推理步骤,显著提升复杂任务的表现。然而,这些流畅的推理链条是否真的反映了模型的推理能力?
随着推理大模型和思维链的出现与普及,大模型具备了「深度思考」的能力,不同任务的泛用性得到了很大的提高。
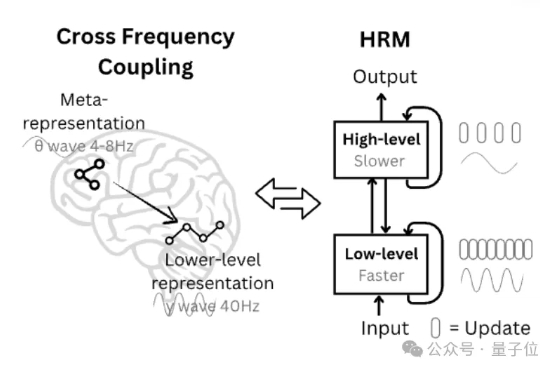
27M小模型超越o3-mini-high和DeepSeek-R1!推理还不靠思维链。 开发者是那位拒绝了马斯克、还要挑战Transformer的00后清华校友,Sapient Intelligence的创始人王冠。

在语言模型领域,长思维链监督微调(Long-CoT SFT)与强化学习(RL)的组合堪称黄金搭档 —— 先让模型学习思考模式,再用奖励机制优化输出,性能通常能实现叠加提升。

近期,随着OpenAI-o1/o3和Deepseek-R1的成功,基于强化学习的微调方法(R1-Style)在AI领域引起广泛关注。这些方法在数学推理和代码智能方面展现出色表现,但在通用多模态数据上的应用研究仍有待深入。