
不要自回归!扩散模型作者创业,首个商业级扩散LLM来了,编程秒出结果
不要自回归!扩散模型作者创业,首个商业级扩散LLM来了,编程秒出结果当前的 AI 领域,可以说 Transformer 与扩散模型是最热门的模型架构。也因此,有不少研究团队都在尝试将这两种架构融合到一起,以两者之长探索新一代的模型范式,比如我们之前报道过的 LLaDA。不过,之前这些成果都还只是研究探索,并未真正实现大规模应用。
来自主题: AI技术研报
11848 点击 2025-02-27 14:40
 搜索
搜索
当前的 AI 领域,可以说 Transformer 与扩散模型是最热门的模型架构。也因此,有不少研究团队都在尝试将这两种架构融合到一起,以两者之长探索新一代的模型范式,比如我们之前报道过的 LLaDA。不过,之前这些成果都还只是研究探索,并未真正实现大规模应用。

进入到 2025 年,视频生成(尤其是基于扩散模型)领域还在不断地「推陈出新」,各种文生视频、图生视频模型展现出了酷炫的效果。其中,长视频生成一直是现有视频扩散的痛点。

最近,扩散模型在生成模型领域异军突起,凭借其独特的生成机制在图像生成方面大放异彩,尤其在处理高维复杂数据时优势明显。然而,尽管扩散模型在图像生成任务中表现优异,但在图像目标移除任务中仍然面临诸多挑战。现有方法在移除前景目标后,可能会留下残影或伪影,难以实现与背景的自然融合。
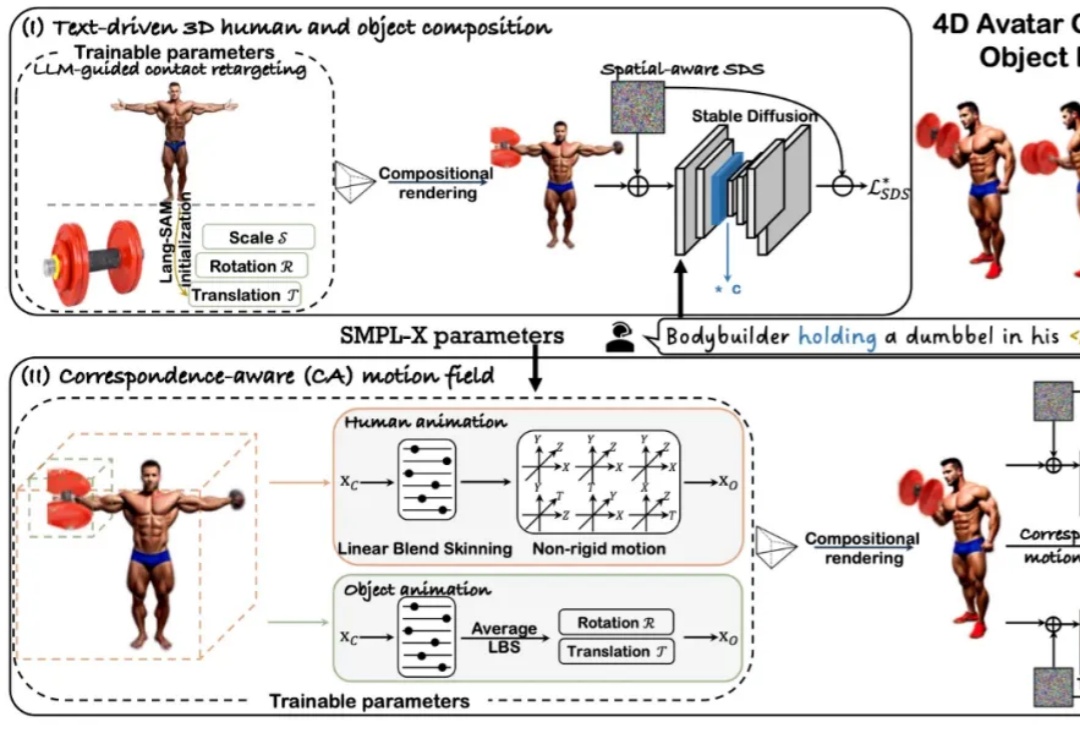
近年来,随着扩散模型和 Transformer 技术的快速发展,4D 人体 - 物体交互(HOI)的生成与驱动效果取得了显著进展。然而,当前主流方法仍依赖 SMPL [1] 这一人体先验模型来生成动作。

把扩散模型的生成能力与 MCTS 的自适应搜索能力相结合,会是什么结果?

视频扩散模型新综述来了,覆盖300+文献的那种。

过去一年,3D 生成技术迎来爆发式增长。在大场景生成领域,涌现出一批 “静态大场景生成” 工作,如 SemCity [1]、PDD [2]、XCube [3] 等。这些研究推动了 AI 利用扩散模型的强大学习能力来解构和创造物理世界的趋势。
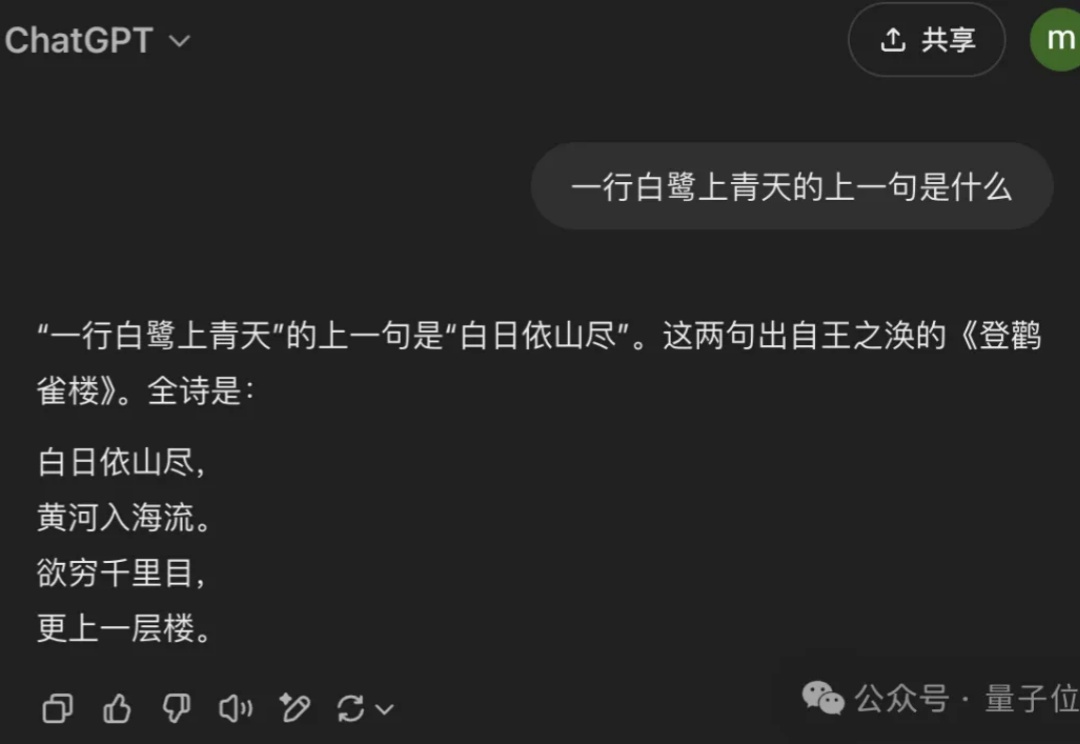
用扩散模型替代自回归,大模型的逆诅咒有解了!

SANA 1.5是一种高效可扩展的线性扩散Transformer,针对文本生成图像任务进行了三项创新:高效的模型增长策略、深度剪枝和推理时扩展策略。这些创新不仅大幅降低了训练和推理成本,还在生成质量上达到了最先进的水平。
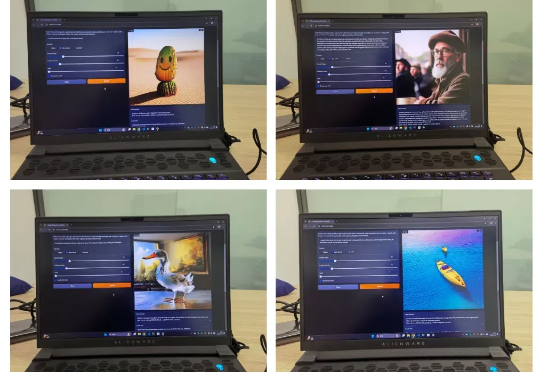
香港大学联合上海人工智能实验室,华为诺亚方舟实验室提出高效扩散模型 LiT:探索了扩散模型中极简线性注意力的架构设计和训练策略。LiT-0.6B 可以在断网状态,离线部署在 Windows 笔记本电脑上,遵循用户指令快速生成 1K 分辨率逼真图片。