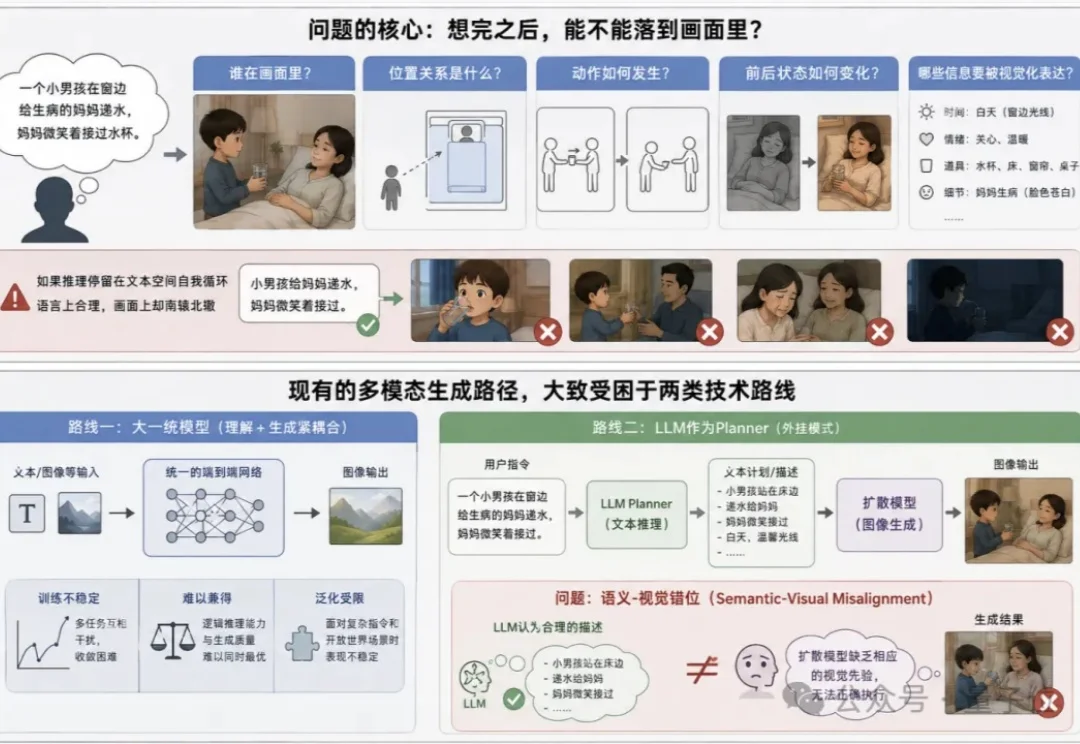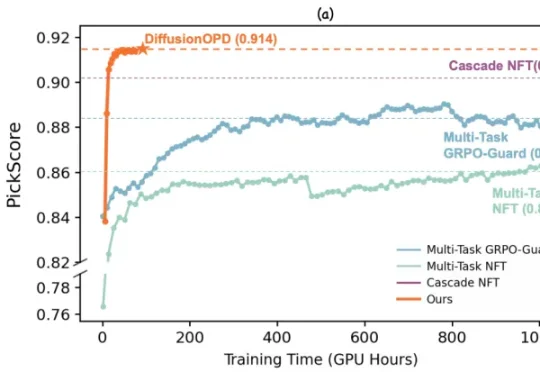
DiffusionOPD:复旦联合通义万相提出扩散模型「在线策略蒸馏」新范式,让学⽣模型同时学会构图、⽂字与美学
DiffusionOPD:复旦联合通义万相提出扩散模型「在线策略蒸馏」新范式,让学⽣模型同时学会构图、⽂字与美学近期,来自复旦大学与阿里巴巴通义万相的研究团队对此提出了新的思考。他们认为,多任务强化学习不应被视为一个统一优化问题,而应该解耦为两个彼此独立的过程:单任务的在线策略探索 & 多任务能力整合。
来自主题: AI技术研报
8664 点击 2026-05-30 10:49