

推理模型其实无需「思考」?伯克利发现有时跳过思考过程会更快、更准确
推理模型其实无需「思考」?伯克利发现有时跳过思考过程会更快、更准确当 DeepSeek-R1、OpenAI o1 这样的大型推理模型还在通过增加推理时的计算量提升性能时,加州大学伯克利分校与艾伦人工智能研究所突然扔出了一颗深水炸弹:别再卷 token 了,无需显式思维链,推理模型也能实现高效且准确的推理。
来自主题: AI技术研报
8548 点击 2025-04-19 14:39
当 DeepSeek-R1、OpenAI o1 这样的大型推理模型还在通过增加推理时的计算量提升性能时,加州大学伯克利分校与艾伦人工智能研究所突然扔出了一颗深水炸弹:别再卷 token 了,无需显式思维链,推理模型也能实现高效且准确的推理。
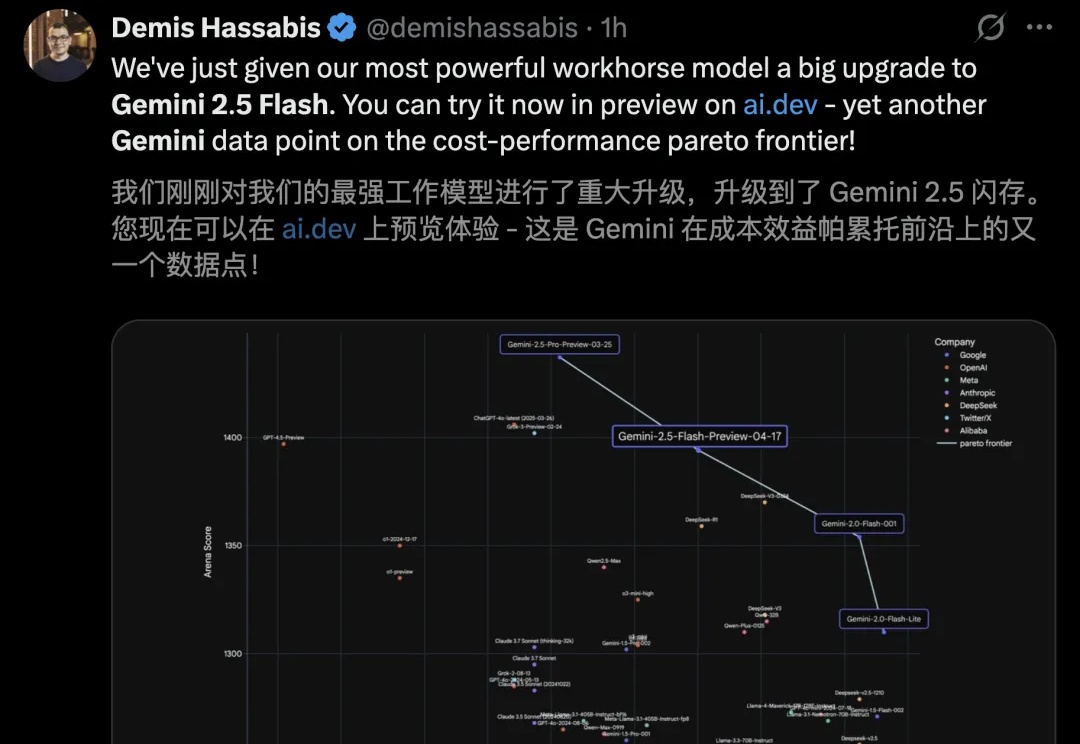
谷歌发布首款混合推理模型Gemini 2.5 Flash,引入了革命性「思考预算」,可灵活控制推理深度,性能一举击败Claude 3.7,比肩o4-mini。而且,关闭思考模式成本直降600%。
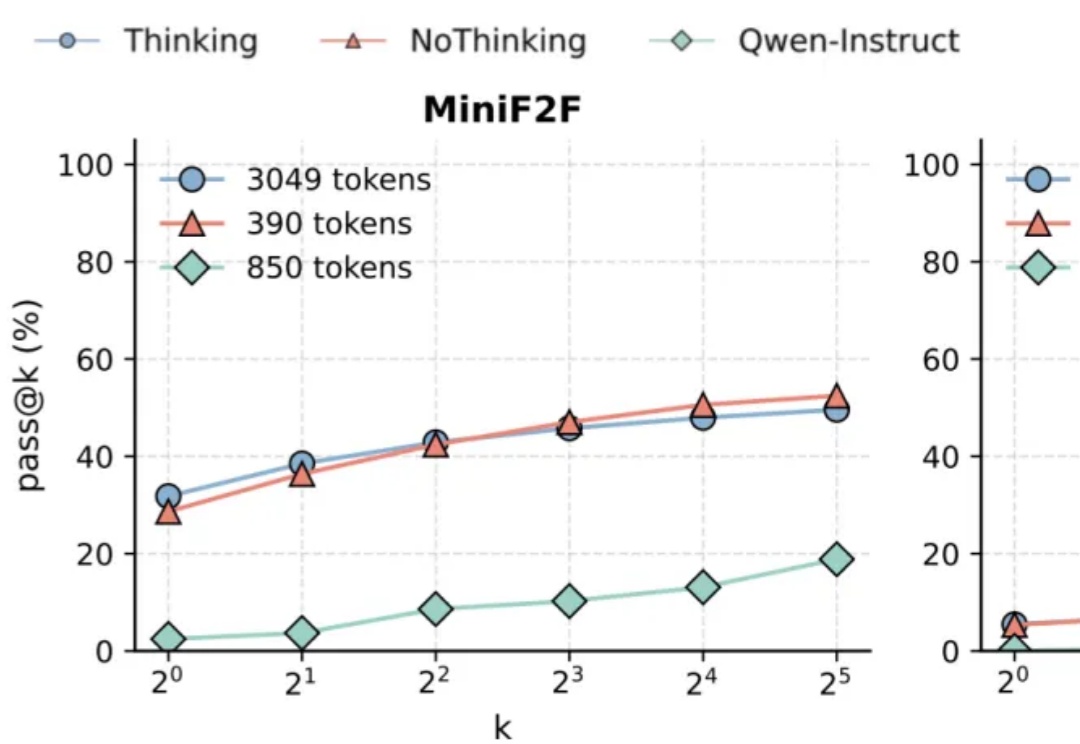
让推理模型不要思考,得到的结果反而更准确?

这是一份142页的研究论文,本文深入解析了大型推理模型DeepSeek-R1如何通过"思考"解决问题。研究揭示了模型思维的结构化过程,以及每个问题都存在甜蜜点"最佳推理区间"的惊人发现。这标志着"思维学"这一新兴领域的诞生,为我们理解和优化AI推理能力提供了宝贵框架。

就在刚刚,智谱一口气上线并开源了三大类最新的GLM模型:沉思模型GLM-Z1-Rumination 推理模型GLM-Z1-Air 基座模型GLM-4-Air-0414
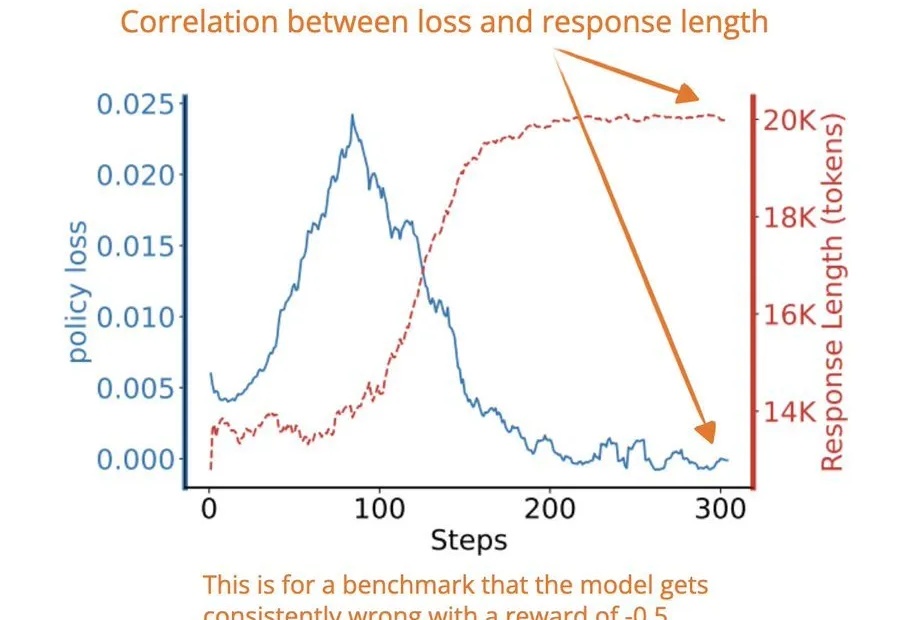
今天早些时候,著名研究者和技术作家 Sebastian Raschka 发布了一条推文,解读了一篇来自 Wand AI 的强化学习研究,其中分析了推理模型生成较长响应的原因。

研究发现,推理模型(如DeepSeek-R1、o1)遇到「缺失前提」(MiP)的问题时,这些模型往往表现失常:回答长度激增、计算资源浪费。本文基于马里兰大学和利哈伊大学的最新研究,深入剖析推理模型在MiP问题上的「过度思考」现象,揭示其背后的行为模式,带你一窥当前AI推理能力的真实边界。
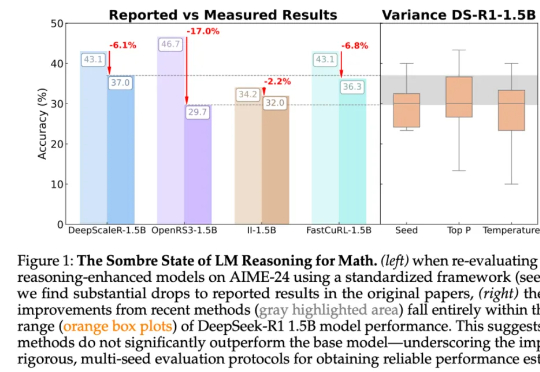
尽管这些论文的结论统统指向了强化学习带来的显著性能提升,但来自图宾根大学和剑桥大学的研究者发现,强化学习导致的许多「改进」可能只是噪音。「受推理领域越来越多不一致的经验说法的推动,我们对推理基准的现状进行了严格的调查,特别关注了数学推理领域评估算法进展最广泛使用的测试平台之一 HuggingFaceH4,2024;AI - MO。」

Qwen 3还未发布,但已发布的Qwen系列含金量还在上升。2个月前,李飞飞团队基于Qwen2.5-32B-Instruct 模型,以不到50美元的成本训练出新模型 S1-32B,取得了与 OpenAI 的 o1 和 DeepSeek 的 R1 等尖端推理模型数学及编码能力相当的效果。如今,他们的视线再次投向了这个国产模型。

字节跳动豆包团队今天发布了自家新推理模型 Seed-Thinking-v1.5 的技术报告。从报告中可以看到,这是一个拥有 200B 总参数的 MoE 模型,每次工作时会激活其中 20B 参数。其表现非常惊艳,在各个领域的基准上都超过了拥有 671B 总参数的 DeepSeek-R1。有人猜测,这就是字节豆包目前正在使用的深度思考模型。