港科提出新算法革新大模型推理范式:随机策略估值竟成LLM数学推理「神操作」
港科提出新算法革新大模型推理范式:随机策略估值竟成LLM数学推理「神操作」论文第一作者何浩然是香港科技大学博士生,研究方向包括强化学习和基础模型等,研究目标是通过经验和奖励激发超级智能。共同第一作者叶语霄是香港科技大学一年级博士。通讯作者为香港科技大学电子及计算机工程系、计
来自主题: AI技术研报
9149 点击 2025-11-01 09:24
 搜索
搜索
论文第一作者何浩然是香港科技大学博士生,研究方向包括强化学习和基础模型等,研究目标是通过经验和奖励激发超级智能。共同第一作者叶语霄是香港科技大学一年级博士。通讯作者为香港科技大学电子及计算机工程系、计
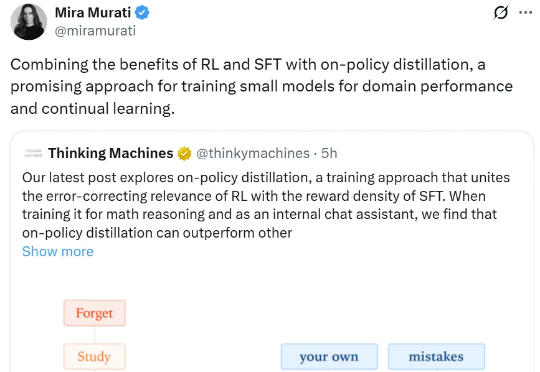
刚刚,不发论文、爱发博客的 Thinking Machines Lab (以下简称 TML)再次更新,发布了一篇题为《在策略蒸馏》的博客。在策略蒸馏(on-policy distillation)是一种将强化学习 (RL) 的纠错相关性与 SFT 的奖励密度相结合的训练方法。在将其用于数学推理和内部聊天助手时,TML 发现在策略蒸馏可以极低的成本超越其他方法。

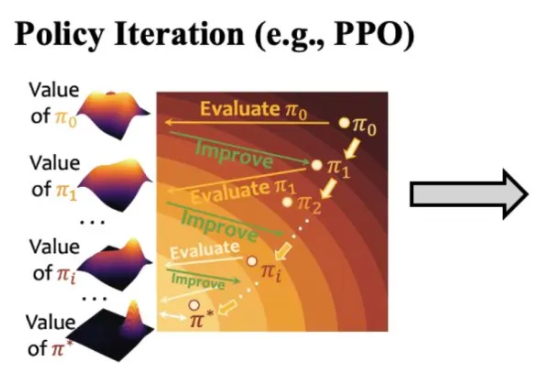
年初的 DeepSeek-R1,带来了大模型强化学习(RL)的火爆。无论是数学推理、工具调用,还是多智能体协作,GRPO(Group Relative Policy Optimization)都成了最常见的 RL 算法。
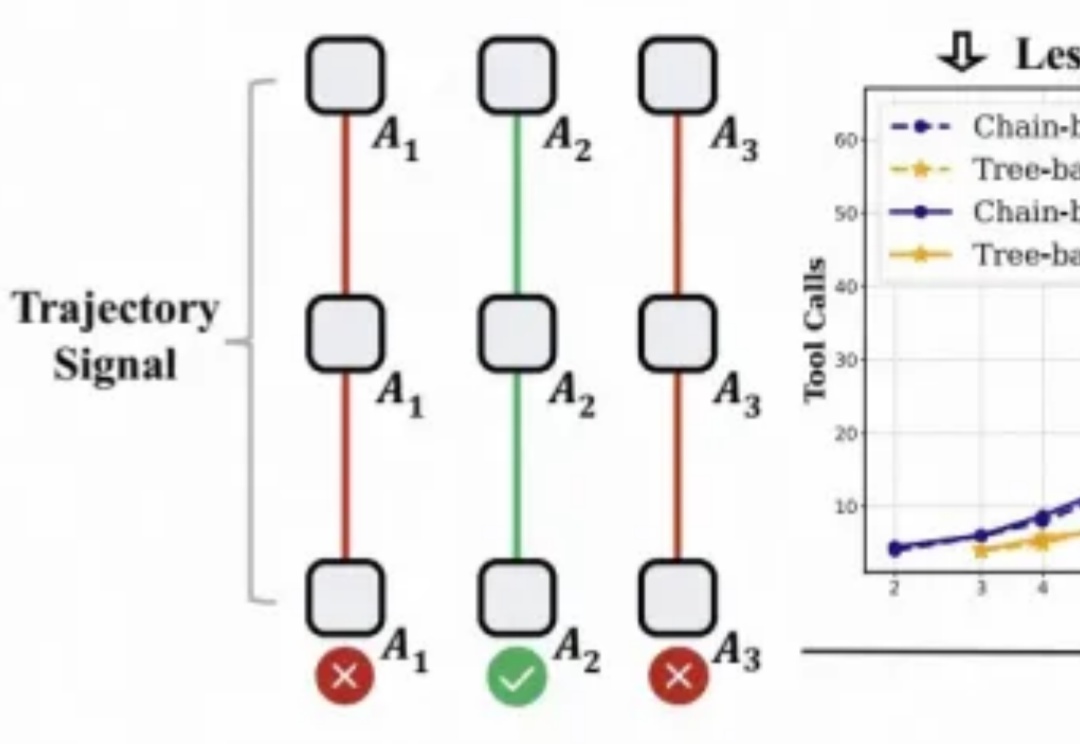
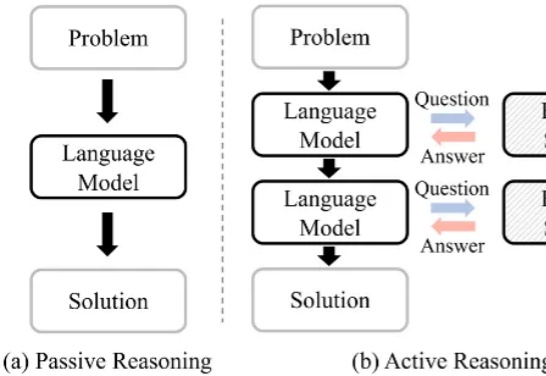
对于大模型的强化学习已在数学推理、代码生成等静态任务中展现出不俗实力,而在需要与开放世界交互的智能体任务中,仍面临「两朵乌云」:高昂的 Rollout 预算(成千上万的 Token 与高成本的工具调用)和极其稀疏的「只看结果」的奖励信号。
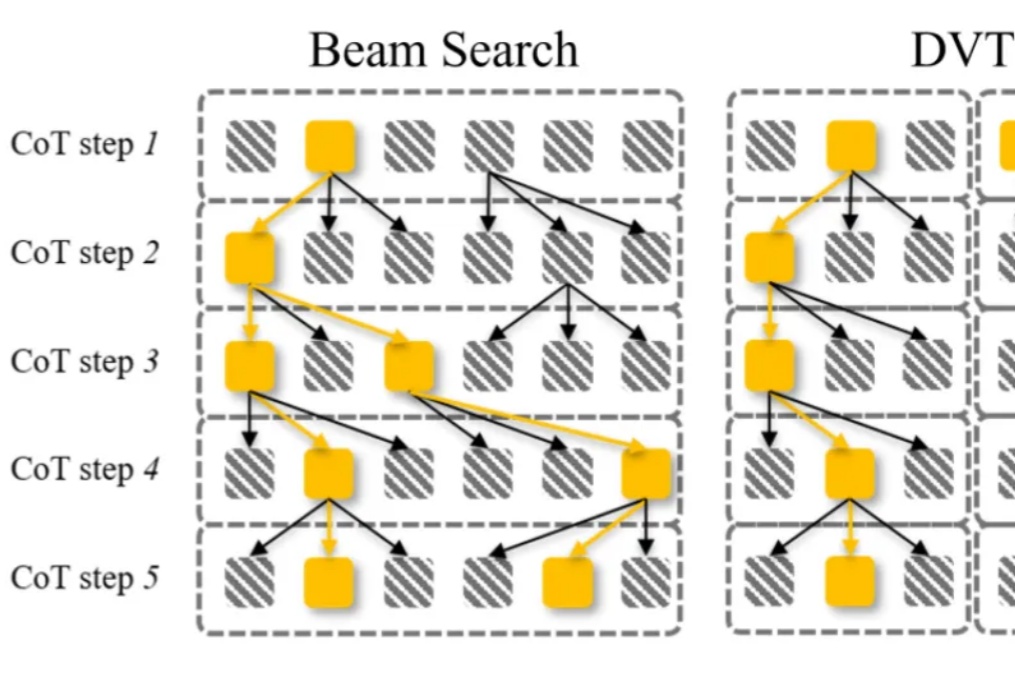
大语言模型通过 CoT 已具备强大的数学推理能力,而 Beam Search、DVTS 等测试时扩展(Test-Time Scaling, TTS)方法可通过分配额外计算资源进一步提升准确性。然而,现有方法存在两大关键缺陷:路径同质化(推理路径趋同)和中间结果利用不足(大量高质量推理分支被丢弃)。
近期,多模态大模型在图像问答与视觉理解等任务中进展迅速。随着 Vision-R1 、MM-Eureka 等工作将强化学习引入多模态推理,数学推理也得到了一定提升。
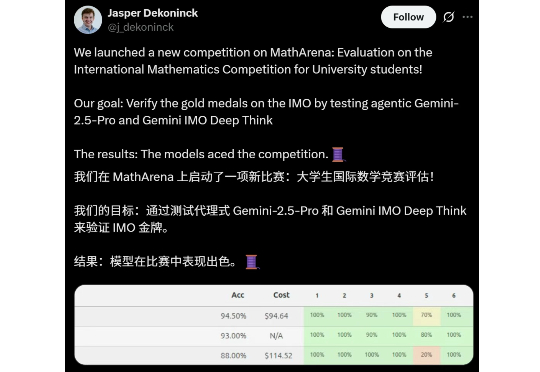
Gemini奥数金牌,实至名归!ETH Zurich博士在大学生国际数学竞赛(IMC)中,测试了Gemini的三种模式,表现远高于前8%的金牌门槛,远超普通大学生。

近期,随着OpenAI-o1/o3和Deepseek-R1的成功,基于强化学习的微调方法(R1-Style)在AI领域引起广泛关注。这些方法在数学推理和代码智能方面展现出色表现,但在通用多模态数据上的应用研究仍有待深入。
大语言模型(Large Language Model, LLM)在复杂推理任务中表现卓越。借助链式思维(Chain-of-Thought, CoT),LLM 能够将复杂问题分解为简单步骤,充分探索解题思路并得出正确答案。LLM 已在多个基准上展现出优异的推理能力,尤其是数学推理和代码生成。
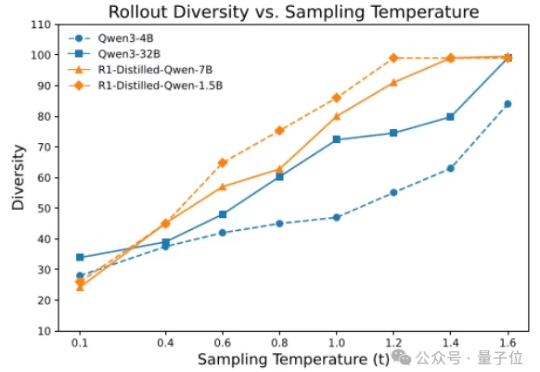
香港大学NLP团队联合字节跳动Seed、复旦大学发布名为Polaris的强化学习训练配方:通过Scaling RL,Polaris让4B模型的数学推理能力(AIME25上取得79.4,AIME24上取得81.2)超越了一众商业大模型,如Seed-1.5-thinking、Claude-4-Opus和o3-mini-high(25/01/31)。