NP难问题接近被AI破解!南航牛津爆改DeepSeek-R1推理,碾压人类27年研究
NP难问题接近被AI破解!南航牛津爆改DeepSeek-R1推理,碾压人类27年研究给DeepSeek-R1推理指导,它的数学推理能力就开始暴涨。更令人吃惊是,Qwen2.5-14B居然给出了此前从未见过的希尔伯特问题的反例!而人类为此耗费了27年。研究者预言:LLM离破解NP-hard问题,已经又近了一步。
来自主题: AI技术研报
10267 点击 2025-03-04 16:20
 搜索
搜索
给DeepSeek-R1推理指导,它的数学推理能力就开始暴涨。更令人吃惊是,Qwen2.5-14B居然给出了此前从未见过的希尔伯特问题的反例!而人类为此耗费了27年。研究者预言:LLM离破解NP-hard问题,已经又近了一步。

自动形式化数学定理证明,是人工智能在数学推理领域的重要应用方向。此类任务需要将数学命题和证明步骤转化为计算机可验证的代码,这不仅能确保推理过程的绝对严谨性,还能构建可复用的数学知识库,为科学研究提供坚实基础。
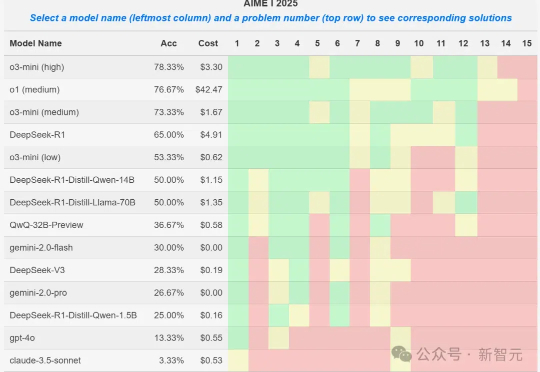
就在刚刚,AIME 2025 I数学竞赛的大模型参赛结果出炉,o3-mini取得78%的最好成绩,DeepSeek R1拿到了65%,取得第四名。然而一位教授却发现,某些1.5B小模型竟也能拿到50%,莫非真的存在数据集污染?
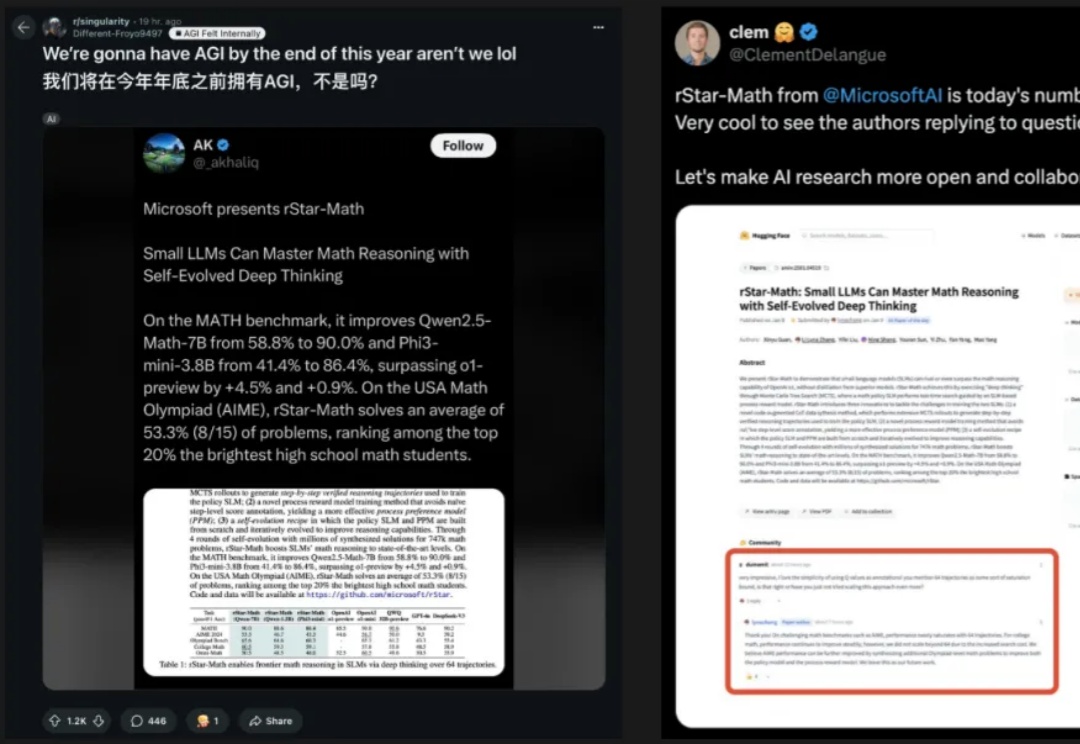
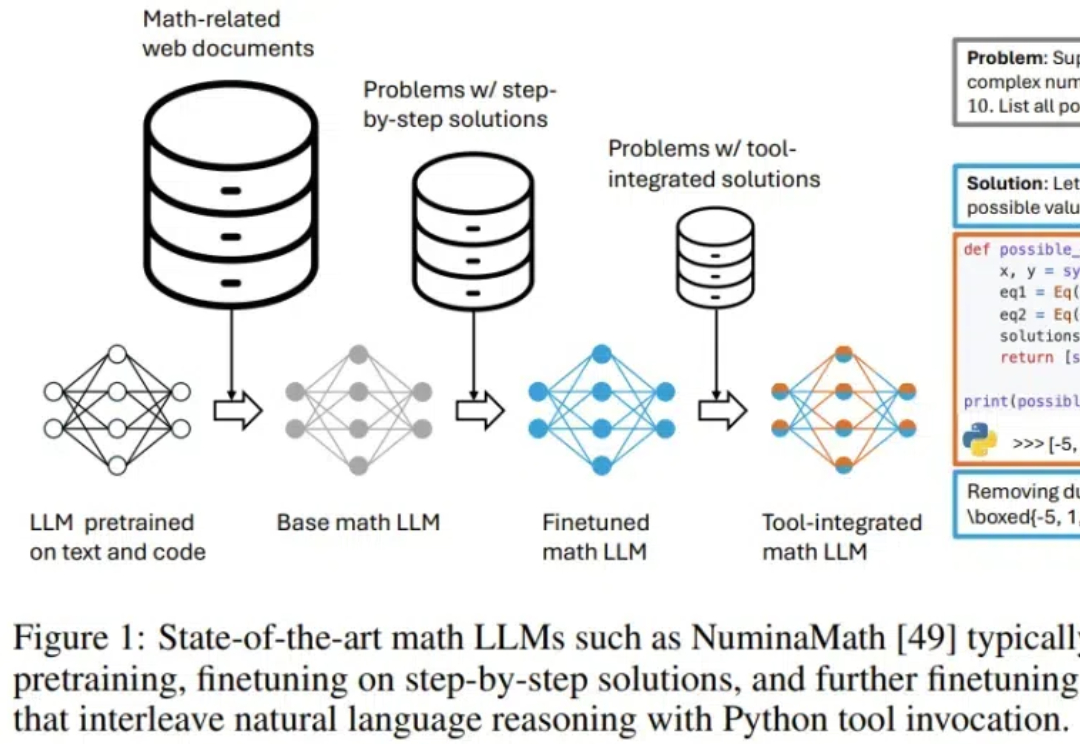
小模型也能击败o1?微软全华人团队提出rStar-Math算法,三大革命性技术突破,不仅让SLM在数学推理能力上刷新SOTA,更是挤进了全美20%顶尖高中生榜单。
对 AI 研究者来说,数学既是一类难题,也是一个标杆,能够成为衡量 AI 技术的发展重要尺度。近段时间,随着 AI 推理能力的提升,使用 AI 来证明数学问题已经成为一个重要的研究探索方向。
近期,OpenAI 号称最强推理模型的推出,引发了社区的热议,无论是性能还是价格,都产生了不少话题。最近,我们对 o1 新发布的 o1 满血版、o1 pro mode 模型进行了高难度数学测试,旨在深入探究其在数学推理方面的能力表现。

OpenAI o1的数学推理能力是否真的那么强?近日,来自港大的研究人员对模型进行了严格的AB测试,在非公开的国家队奥数题面前,o1证明了自己的实力。

目前大语言模型(Large Language Models, LLMs)的推理能力备受关注。从思维链(Chain of Thought,CoT)技术提出,到以 o1 为代表的长思考模型发布,大模型正在展现出接近人类甚至领域专家的水平,其中数学推理是一个典型任务。
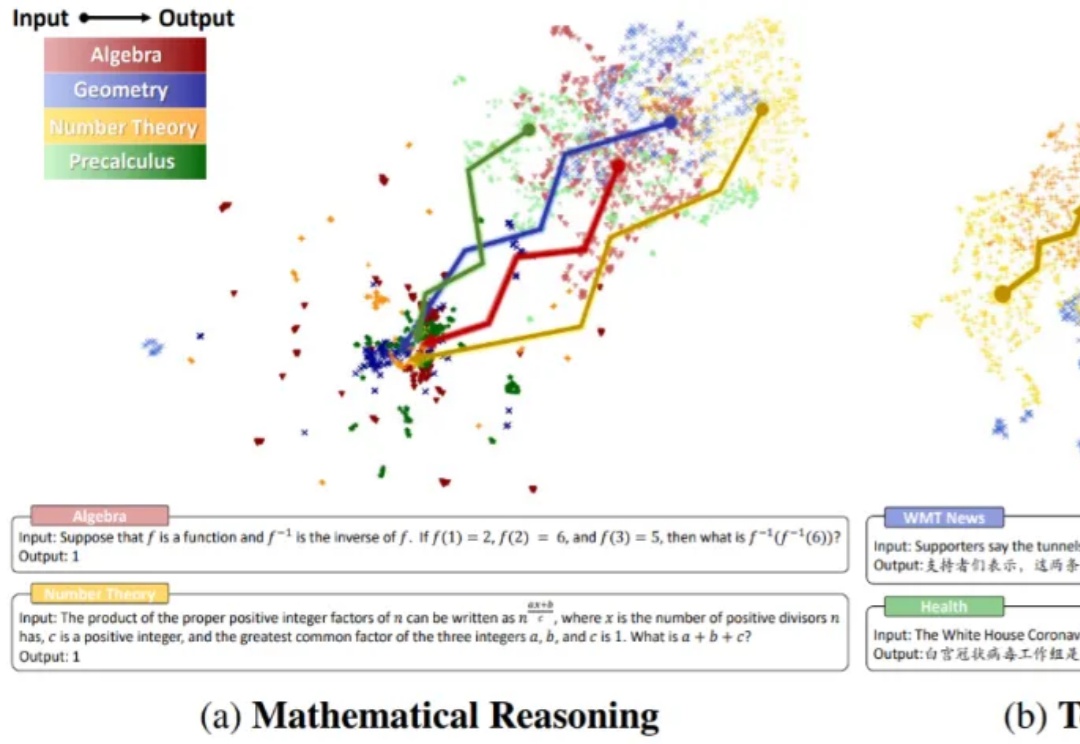
本文将介绍数学推理场景下的首个分布外检测研究成果。
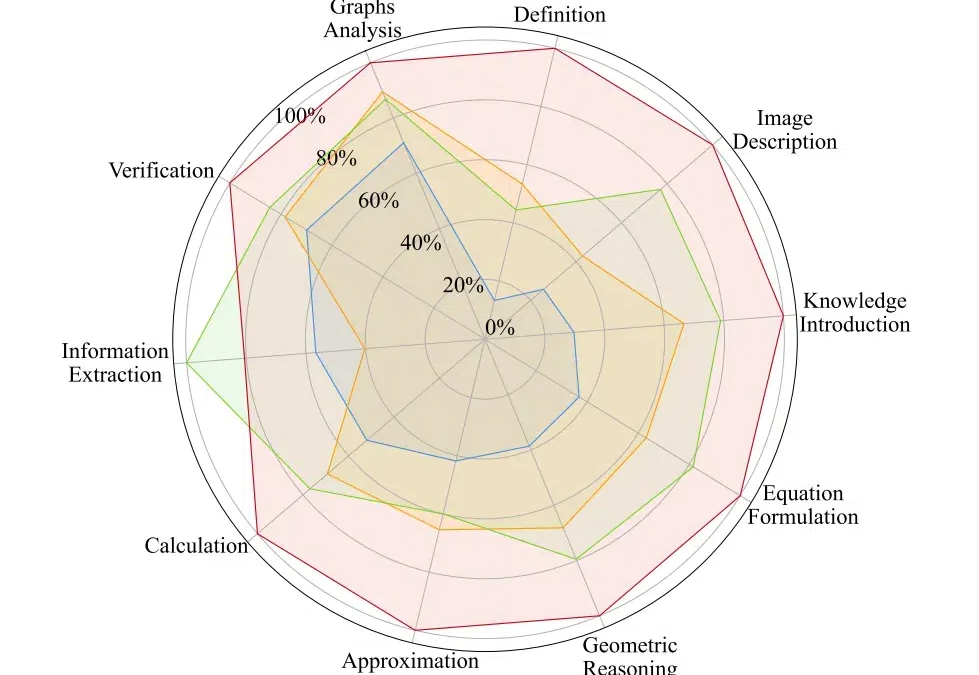
AtomThink 是一个包括 CoT 注释引擎、原子步骤指令微调、政策搜索推理的全流程框架,旨在通过将 “慢思考 “能力融入多模态大语言模型来解决高阶数学推理问题。量化结果显示其在两个基准数学测试中取得了大幅的性能增长,并能够轻易迁移至不同的多模态大模型当中。