
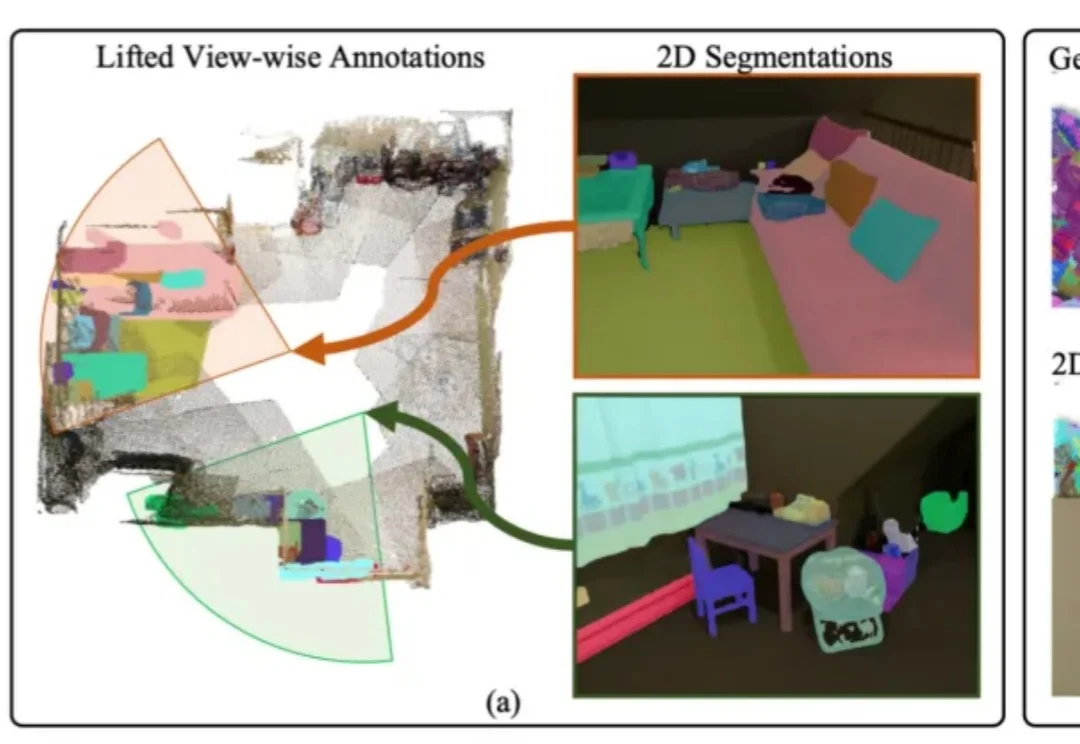
用2D先验自动生成3D标注,自动驾驶、具身智能有福了丨IDEA团队开源
用2D先验自动生成3D标注,自动驾驶、具身智能有福了丨IDEA团队开源3D模型的实例分割一直受限于稀缺的训练数据与高昂的标注成本,训练效果有待提升。
来自主题: AI技术研报
9560 点击 2026-01-19 08:55
3D模型的实例分割一直受限于稀缺的训练数据与高昂的标注成本,训练效果有待提升。

清华在Nature上发表的最新研究发现,AI使科学家更聚焦于数据丰富、问题明确的领域,导致创新单一化,跨界合作减少。研究团队提出「全流程科研智能体系统」,推动AI从工具进化为伙伴,拓展科学边界。
2026年第一月份,医疗AI赛道热闹非凡,我来谈以下10点观察:1.医疗是AI领域里很不好做的赛道。AI赛道正在细分化,有的赛道红海,有的赛道蓝海;而医疗AI赛道很纯粹,就是纯粹不好做。无论To Doctor(医疗专业人士),还是To C(普通消费者)。
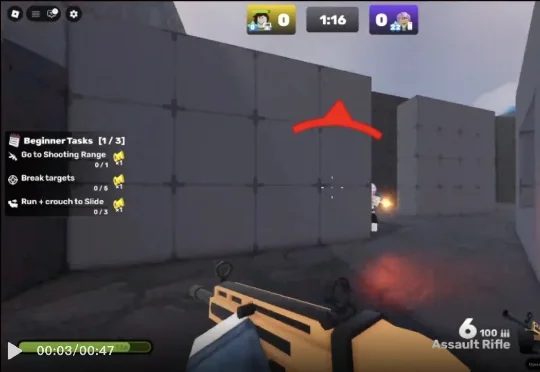
来自 Player2 的研究员们提出了 Pixel2Play(P2P)模型,该模型以游戏画面和文本指令作为输入,直接输出对应的键盘与鼠标操作信号。在消费级显卡 RTX 5090 上,P2P 可以实现超过 20Hz 的端到端推理速度,从而能够真正像人类一样和游戏进行实时交互。P2P 作为通用游戏基座模型,在超过 40 款游戏、总计 8300 + 小时的游戏数据上进行了训练,
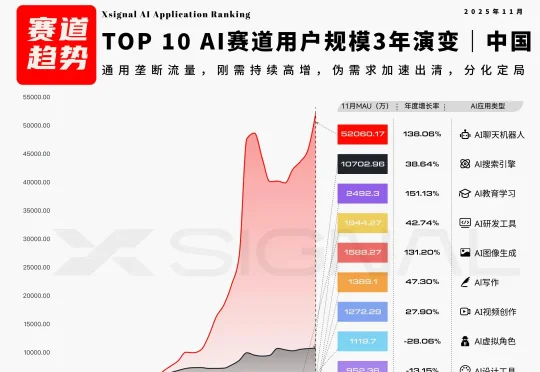
如果将2023年定义为AI的“奇点大爆炸”,那么站在2025年的终章回望,我们不得不承认:“百模大战”的硝烟已散,一个残酷而清晰的“双极化”新世界已然定型。2023-2025 这三年,全球 AI 应用市场完成了从“单点工具猎奇”向“双极化生态定局”的结构性跨越。

本次发布的核心——AIMesh,正是这场架构创新的集大成者。 它被定义为面向「AI工厂」的数据与内存网,核心思路是用一套「三网合一」的柔性网络,替代传统僵化的存储架构。
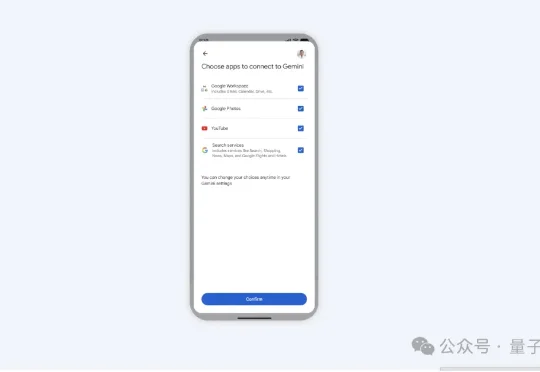
谷歌正式发布了由最新Gemini3模型驱动的“Personal Intelligence”功能。它将谷歌旗下四大应用的数据池进行了底层连接,让AI获得了跨应用权限。
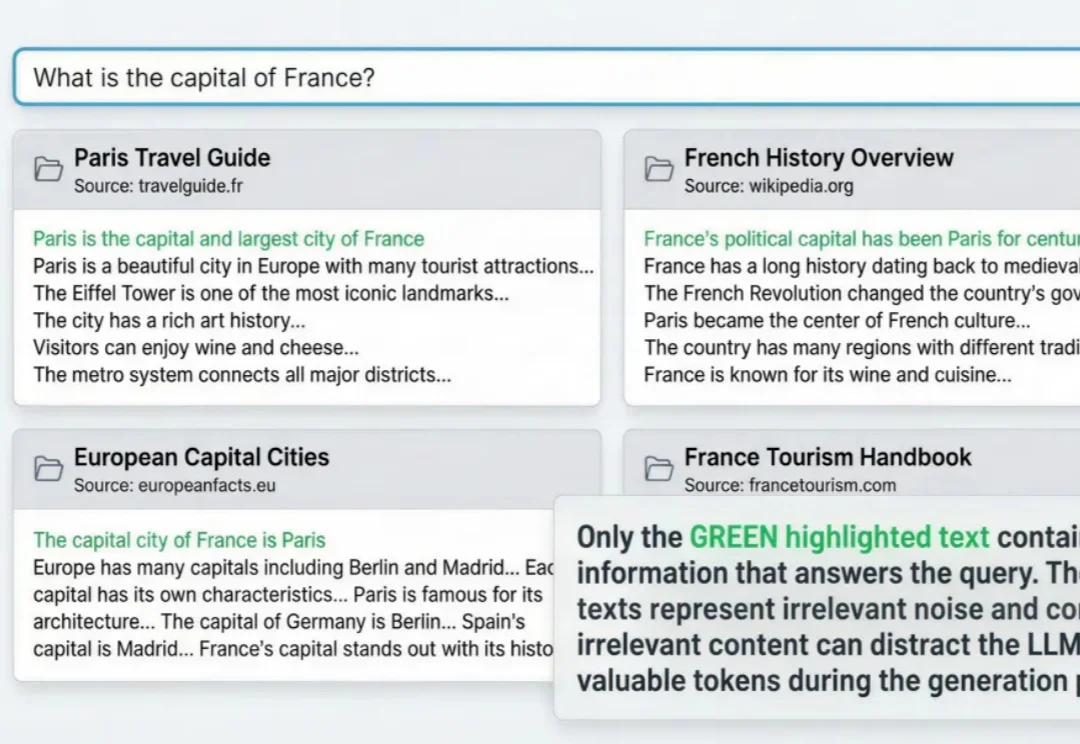
RAG与agent用到深水区,一定会遇到这个问题: 明明架构很完美,私有数据也做了接入,但项目上线三天,不但token账单爆了,模型输出结果也似乎总差点意思。

今天,OpenAI 宣布收购 Torch,一家成立刚满一年的医疗数据整合应用
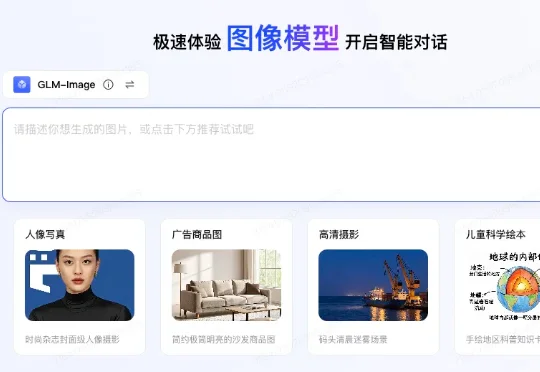
今天,首个在国产芯片上完成全程训练的SOTA(最佳水平)多模态模型开源。这是智谱联合华为开源的图像生成模型GLM-Image。从数据到训练的全流程,该模型完全基于昇腾Atlas 800T A2设备和昇思MindSpore AI框架完成构建。