
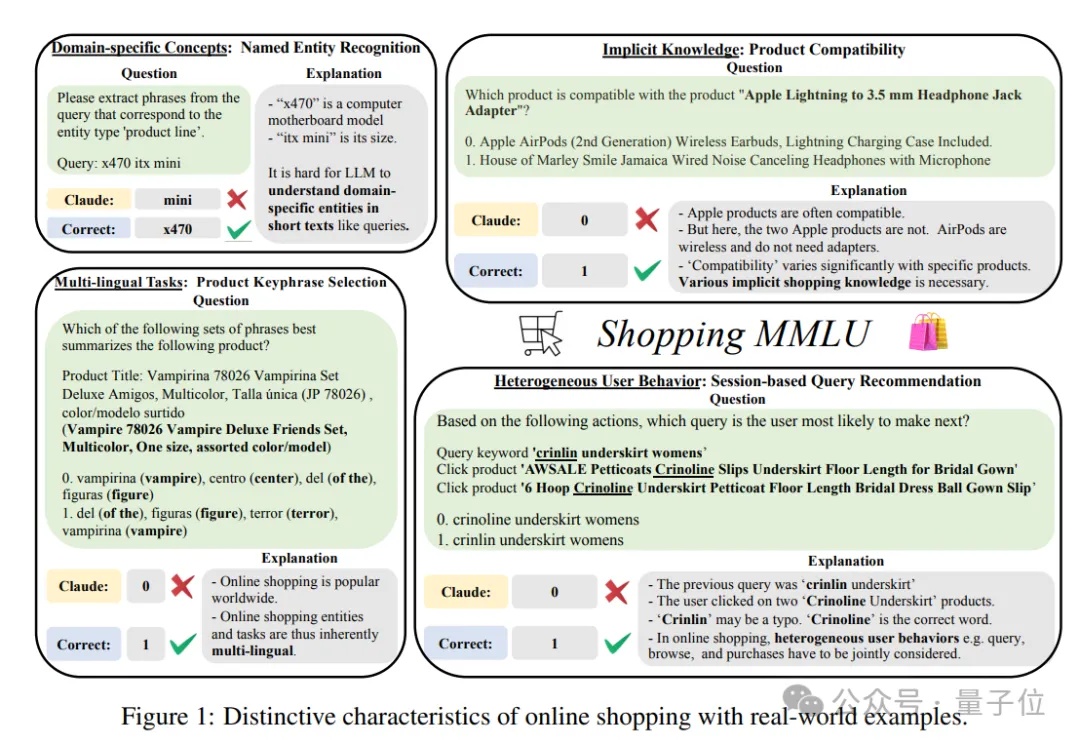
多样任务真实数据,大模型在线购物基准Shopping MMLU开源|NeurIPS&KDD Cup 2024
多样任务真实数据,大模型在线购物基准Shopping MMLU开源|NeurIPS&KDD Cup 2024谁是在线购物领域最强大模型?也有评测基准了。
来自主题: AI技术研报
4639 点击 2024-11-20 15:09
谁是在线购物领域最强大模型?也有评测基准了。
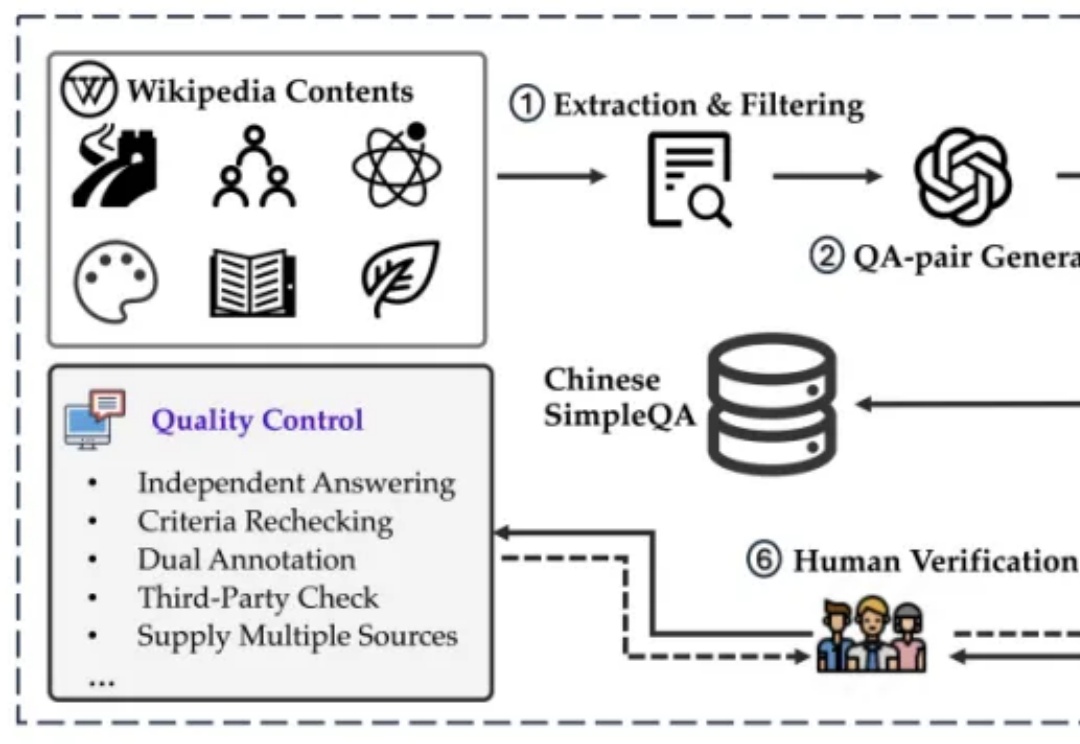
如何解决模型生成幻觉一直是人工智能(AI)领域的一个悬而未解的问题。为了测量语言模型的事实正确性,近期 OpenAI 发布并开源了一个名为 SimpleQA 的评测集。而我们也同样一直在关注模型事实正确性这一领域,目前该领域存在数据过时、评测不准和覆盖不全等问题。例如现在大家广泛使用的知识评测集还是 CommonSenseQA、CMMLU 和 C-Eval 等选择题形式的评测集。

在今天的Ignite开发者大会上,微软发布了两款专为其数据中心基础设施设计的新芯片:Azure Integrated HSM和Azure Boost DPU。
在AI领域数据和算力的军备竞赛中,AI从业者要么紧密跟随OpenAI等领先公司做进一步的应用开发,要么在Transformer机制日益显现局限之时探索新的路径。
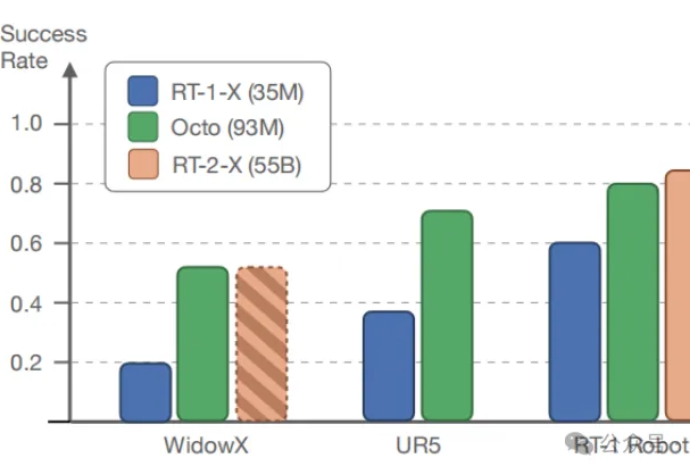
在多样化的机器人数据集上预训练的大型策略有潜力改变机器人学习:与从头开始训练新策略相比,这种通用型机器人策略可以通过少量的领域内数据进行微调,同时具备广泛的泛化能力。

随着汽车进入“AI驱动”的时代,不止各大品牌新车拼智能,出行平台也在布局面向智驾产业的“自动驾驶工具链”。

如今,机器人学习最大的瓶颈是缺乏数据。与图片和文字相比,机器人的学习数据非常稀少。目前机器人学科的主流方向是通过扩大真实世界中的数据收集来尝试实现通用具身智能,但是和其他的基础模型,比如初版的 StableDiffusion 相比,即使是 pi 的数据都会少七八个数量级。

哈佛斯坦福MIT等机构首次提出「精度感知」scaling law,揭示了精度、参数规模、数据量之间的统一关系。数据量增加,模型对量化精度要求随之提高,这预示着AI领域低精度加速的时代即将结束!

通过过程奖励模型(PRM)在每一步提供反馈,并使用过程优势验证器(PAV)来预测进展,从而优化基础策略,该方法在测试时搜索和在线强化学习中显示出比传统方法更高的准确性和计算效率,显著提升了解决复杂问题的能力。

近日,中科大王杰教授团队 (MIRA Lab) 针对离线强化学习数据集存在多类数据损坏这一复杂的实际问题,提出了一种鲁棒的变分贝叶斯推断方法,有效地提升了智能决策模型的鲁棒性,为机器人控制、自动驾驶等领域的鲁棒学习奠定了重要基础。论文发表在 CCF-A 类人工智能顶级会议 Neural Information Processing Systems(NeurIPS 2024)。