
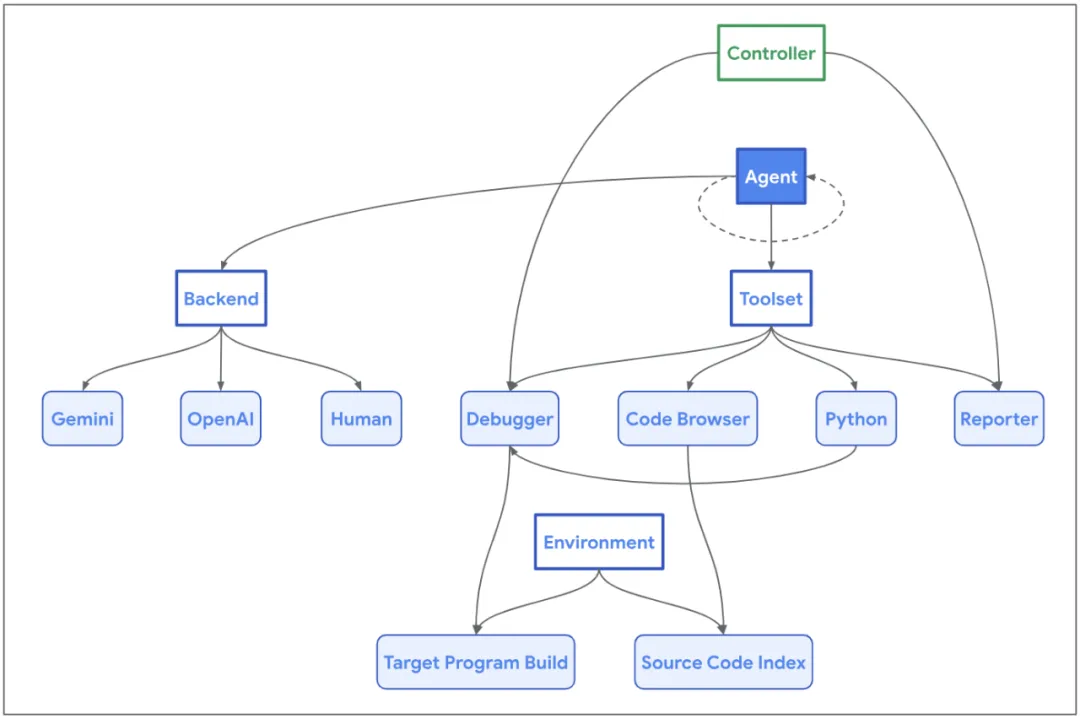
谷歌内部项目:大模型AI智能体发现了代码漏洞
谷歌内部项目:大模型AI智能体发现了代码漏洞开源数据库引擎 SQLite 有 bug,还是智能体检测出来的!
来自主题: AI资讯
7290 点击 2024-11-02 16:29
开源数据库引擎 SQLite 有 bug,还是智能体检测出来的!

多图像场景也能用DPO方法来对齐了! 由上海交大、上海AI实验室、港中文等带来最新成果MIA-DPO。 这是一个面向大型视觉语言模型的多图像增强的偏好对齐方法。
今天 ChatGPT 的搜索功能发布了,或许是已经用 Perplexity 比较习惯,此次 ChatGPT 的搜索就没太多惊艳感了,所以我体验了一下感觉效果一般般,看看后续多用用会不会有更多不一定的体验。

大模型热,企业落地难?就在刚刚,百川智能推出「1+3」产品矩阵,一站式解决大模型商业化难题。「系列优质通用数据+领域增强训练工具链」,仅需10分钟就能让企业自主成为模型定制增强专家,实现行业最佳的多场景可用率。

对于人类而言,一旦掌握了 “打开瓶盖” 的动作,面对 “拧紧螺丝” 这样的任务通常也能游刃有余,因为这两者依赖于相似的手部动作。然而,对于机器人来说,即使是这样看似简单的任务转换依然充满挑战。例如,换成另一种类型的瓶盖,机器人可能无法成功打开。这表明,目前的机器人方法尚未充分让模型学习到任务的内在执行逻辑,而只是单纯的依赖于数据拟合。

已与多家国内外头部主机厂、Tier1供应商、具身智能公司签约

近年来,大语言模型(Large Language Models, LLMs)的研究取得了重大进展,并对各个领域产生了深远影响。然而,LLMs的卓越性能来源于海量数据的大规模训练,这导致LLMs的训练成本明显高于传统模型。

自去年底以来,时序预测领域正在经历重大转型,从传统的「单一数据集训练单一模型」的模式逐步转向「通用预测基础模型」。

清华大学推出的SonicSim平台和SonicSet数据集针对动态声源的语音处理研究提供了强有力的工具和数据支持,有效降低了数据采集成本,实验证明这些工具能有效提升模型在真实环境中的性能。
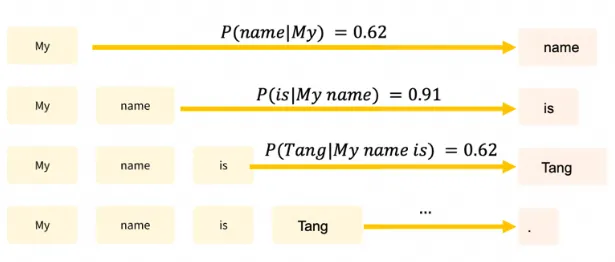
文章详细讨论了如何确保大型语言模型(LLMs)输出结构化的JSON格式,这对于提高数据处理的自动化程度和系统的互操作性至关重要。