

覆盖 7 百万问答数据,上海 AI Lab 发布 ChemLLM,专业能力比肩 GPT-4
覆盖 7 百万问答数据,上海 AI Lab 发布 ChemLLM,专业能力比肩 GPT-4内含一键部署教程
来自主题: AI技术研报
8749 点击 2024-09-04 17:42
内含一键部署教程

说好的AI给人类打工呢? 为了拿到新数据、训练AI大模型,字节等互联网大厂正在亲自下场,以单次300元不等的价格招募“AI录音员”,定制语料库。

据相关数据显示,早在 2020 年,国内选择语音输入的用户数量已经达到 2.5 亿,使用率接近 40%,更为便捷的语音交流,已经越来越成为主流。

近年来,Transformer等预训练大模型在语言理解及生成等领域表现出色,大模型背后的Scaling Law(规模定律)进一步揭示了模型性能与数据量、算力之间的关系,强化了数据在提升AI表现中的关键作用。

AnyGraph聚焦于解决图数据的核心难题,跨越多种场景、特征和数据集进行预训练。其采用混合专家模型和特征统一方法处理结构和特征异质性,通过轻量化路由机制和高效设计提升快速适应能力,且在泛化能力上符合Scaling Law。
基于公司私有组件生成代码,这个问题的本质是:由于大模型的训练数据集不包含你公司的私有组件数据,因此不能够生成符合公司私有组件库的代码。
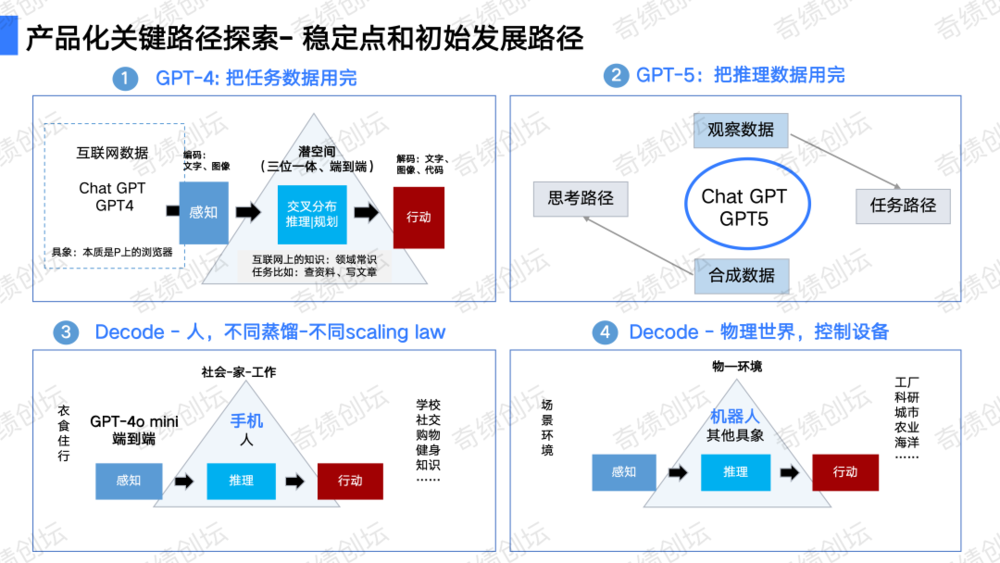
本文简述了大模型产品化的挑战与策略,特别关注OpenAI的实践,如ChatGPT的用户接受度和GPTs的数据限制。

该论文作者均来自于华南理工大学马千里教授团队,所在实验室为机器学习与数据挖掘实验室。论文的三位共同第一作者为博士生郑俊豪、硕士生邱圣洁、硕士生施成明,主要研究方向包括大模型和终生学习等,通讯作者为马千里教授(IEEE/ACM TASLP 副主编)。

8月28日至30日,2024中国国际大数据产业博览会正在贵阳火热进行中。“产业链上下游的人都来了。”一位行业人士观察,与以往不同,这届数博会上,数据要素、智算基础设施建设,正在和智能化、大模型行业应用等一起成为被密集讨论的话题。

近日,创投数据服务商 IT桔子发布了《2024年中美独角兽公司发展分析报告》 。作为全球拥有独角兽企业数量最多的两个国家,对比中国和美国的独角兽在产业、估值、城市分布等维度的差异,分析他们的发展路径、轨迹,有着更重要的意义。