
Twelve Labs: 多模态重塑视频内容检索
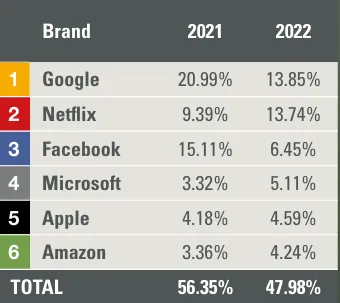
Twelve Labs: 多模态重塑视频内容检索Cisco 曾在 2018 年做过测算,全球已经有超过 75% 的数据是视频内容,互联网视频数据流量超过 50%。
来自主题: AI资讯
11505 点击 2024-08-27 11:47
Cisco 曾在 2018 年做过测算,全球已经有超过 75% 的数据是视频内容,互联网视频数据流量超过 50%。

土地和电力资源成为AI行业的“香饽饽”,而工业用地正好能满足AI数据中心建设的部分“刚需”。
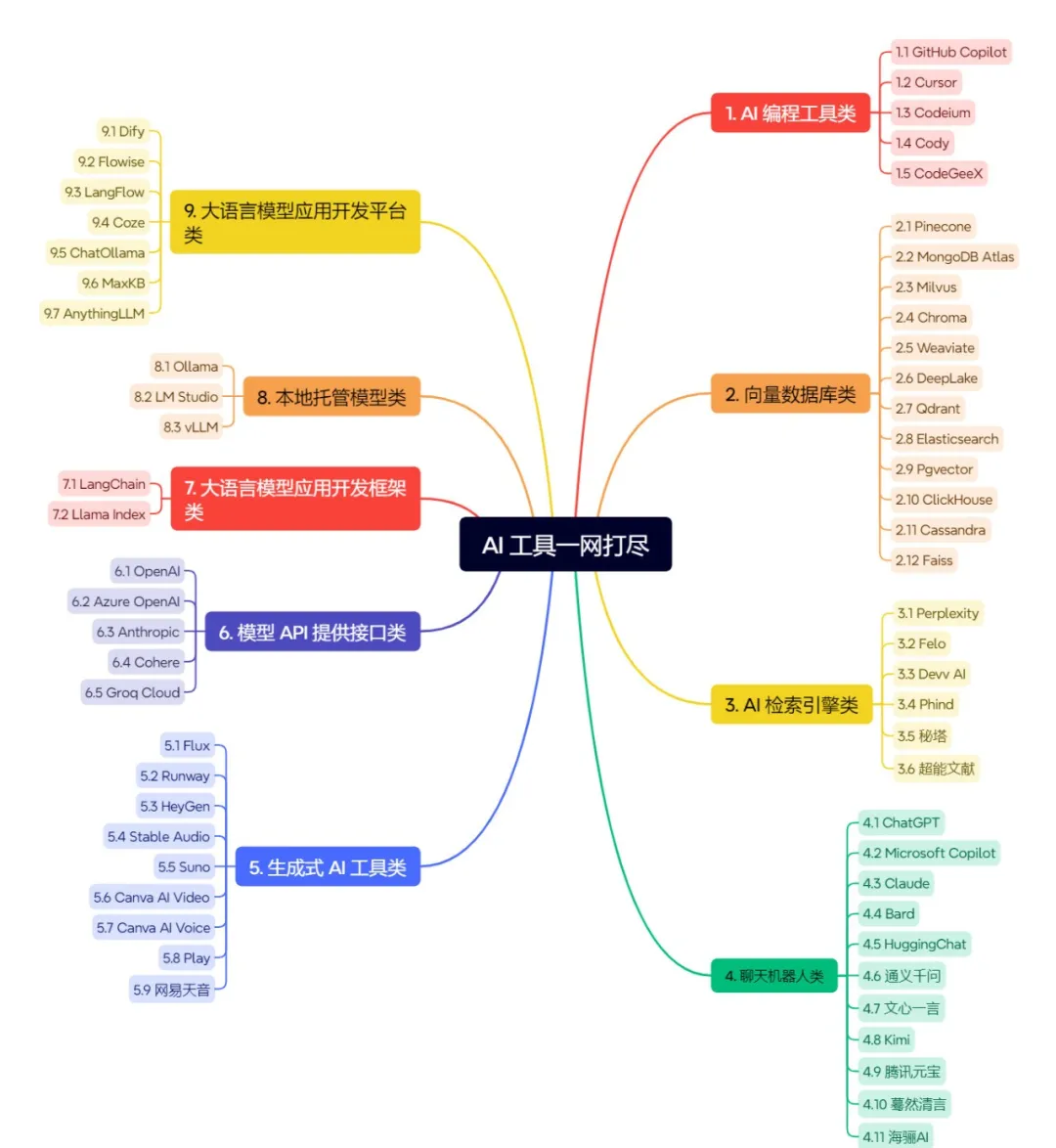
在当今人工智能领域,大语言模型及其相关工具正在迅速发展,涵盖了编程、数据库、检索引擎、聊天机器人、生成式 AI 工具、模型 API、开发框架和平台等各个方面。

随着LLM不断迭代,偏好和评估数据中大量的人工标注逐渐成为模型扩展的显著障碍之一。Meta FAIR的团队最近提出了一种使用迭代式方法「自学成才」的评估模型训练方法,让70B参数的Llama-3-Instruct模型分数超过了Llama 3.1-405B。

本文引入了 Transfusion,这是一种可以在离散和连续数据上训练多模态模型的方法。

在人工智能领域,图像生成技术一直是一个备受关注的话题。近年来,扩散模型(Diffusion Model)在生成逼真且复杂的图像方面取得了令人瞩目的进展。然而,技术的发展也引发了潜在的安全隐患,比如生成有害内容和侵犯数据版权。这不仅可能对用户造成困扰,还可能涉及法律和伦理问题。

这篇文章对如何进行领域模型训练进行一个简单的探讨,主要内容是对 post-pretrain 阶段进行分析,后续的 Alignment 阶段就先不提了,注意好老生常谈的“数据质量”和“数据多样性”即可。

今年以来,具身智能正在成为学术界和产业界的热门领域,相关的产品和成果层出不穷。

代码知识原来这么重要。

Emory大学的研究团队提出了一种创新的方法,将大语言模型(LLM)在文本图(Text-Attributed Graph, 缩写为TAG)学习中的强大能力蒸馏到本地模型中,以应对文本图学习中的数据稀缺、隐私保护和成本问题。通过训练一个解释器模型来理解LLM的推理过程,并对学生模型进行对齐优化,在多个数据集上实现了显著的性能提升,平均提高了6.2%。