

英伟达神秘视频基础模型「Cosmos」曝光,数据全靠偷
英伟达神秘视频基础模型「Cosmos」曝光,数据全靠偷为了这个视频模型,英伟达每天正在疯狂地爬取相当于 80 年时长的视频数据。
来自主题: AI资讯
11247 点击 2024-08-06 15:05
为了这个视频模型,英伟达每天正在疯狂地爬取相当于 80 年时长的视频数据。

英伟达版Sora曝光——

The Information近日爆出了一则OpenAI的亏损新闻,其中新增的关键数据包括: OpenAI目前单月收入约为2.83mnUSD,全年营收可能在35~45亿美金。 OpenAI 24年推理成本将达到40亿美金,训练成本将达到30亿美金。

如今一场席卷人工智能圈的“石油危机”已经出现,几乎每一家AI厂商都在竭力寻求新的语料来源,但再多的数据似乎也填不满AI大模型的胃口。更何况越来越多的内容平台意识到了手中数据的价值,纷纷开始敝帚自珍。为此,“合成数据”也成为了整个AI行业探索的新方向。

大模型展现出了卓越的指令跟从和任务泛化的能力,这种独特的能力源自 LLMs 在训练中使用了指令跟随数据以及人类反馈强化学习(RLHF)。
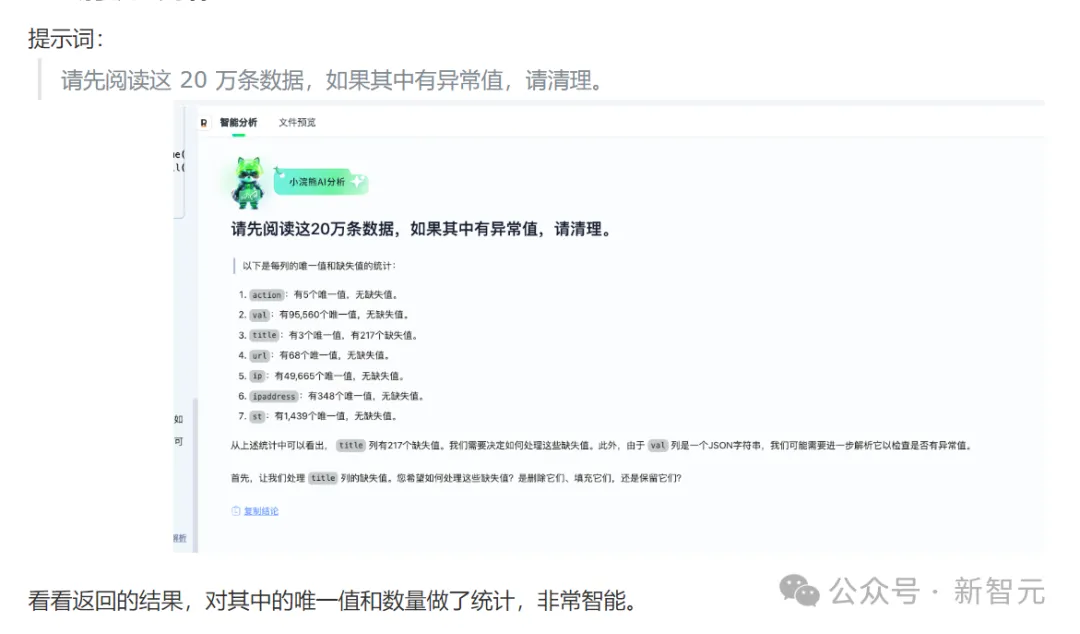
有什么方法可以帮忙节省时间增加效率吗?最近一款AI办公工具爆火,不仅用户猛增,网上还涌现一大批体验小作文。 一看时间点,原来是进入如火如荼的打工旺季Q3了,哭了,人生再无暑假。 这款名为「办公小浣熊」,是来自商汤科技的大模型AI原生工具。除了完全免费外,「办公小浣熊」既有网页端入口,还有移动端小程序,聊着天就能把数据分析做了,操作非常方便。
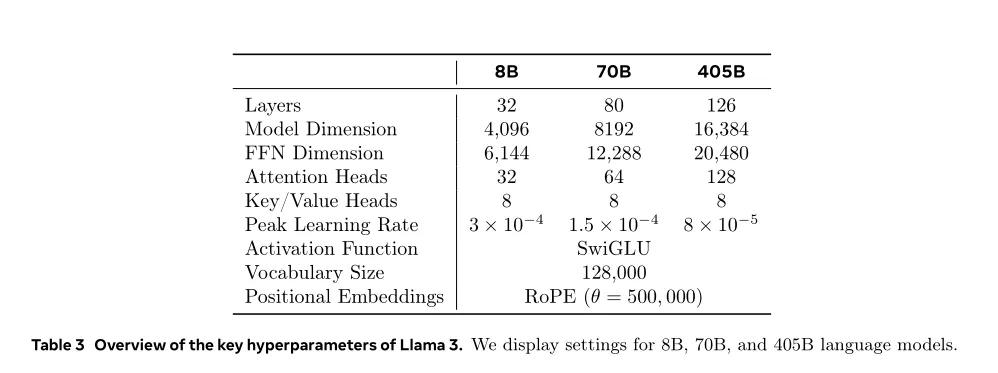
不同类型的数据配比如何配置:先通过小规模实验确定最优配比,然后将其应用到大模型的训练中。 Token配比结论:通用知识50%;数学与逻辑25%;代码17%;多语言8%。

家处某二线城市的明明,在当地一所普通高校就读,还有一年就要大学毕业的他,害怕毕业后不好找工作,最近花了2万多元在当地培训机构报名了“AI训练师”的课程。 AI训练师指“使用智能训练软件,在人工智能产品实际使用过程中进行数据库管理、算法参数设置、人机交互设计、性能测试跟踪及其他辅助作业的人员”,可以简单理解为,所有与AI训练相关的职业,这一职业,在2020年被纳入国家职业分类目录。

在商业化的道路上,AI模型的能力要进入具体场景才能产生巨大价值。Vanta就是一家在这个方面做的很好的公司。

为了解决这个问题,一些研究尝试通过强大的 Teacher Model 生成训练数据,来增强 Student Model 在特定任务上的性能。然而,这种方法在成本、可扩展性和法律合规性方面仍面临诸多挑战。在无法持续获得高质量人类监督信号的情况下,如何持续迭代模型的能力,成为了亟待解决的问题。