

维基百科+大模型打败幻觉!斯坦福WikiChat性能碾压GPT-4,准确率高达97.3%
维基百科+大模型打败幻觉!斯坦福WikiChat性能碾压GPT-4,准确率高达97.3%大模型固有的幻觉问题严重影响了LLM的表现。斯坦福最新研究利用维基百科数据训练大模型,得到的WikiChat成为首个几乎不产生幻觉的聊天机器人。
来自主题: AI资讯
6064 点击 2024-01-03 14:00
大模型固有的幻觉问题严重影响了LLM的表现。斯坦福最新研究利用维基百科数据训练大模型,得到的WikiChat成为首个几乎不产生幻觉的聊天机器人。

最近由UCSC的研究人员发表论文,证明大模型的零样本或者少样本能力,几乎都是来源于对于训练数据的记忆。
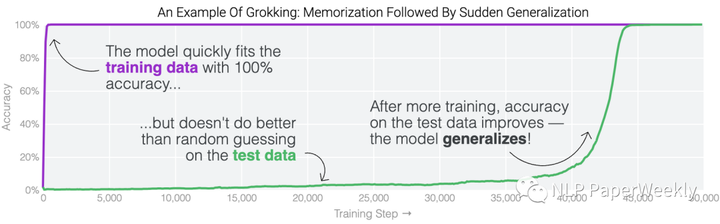
今天分享一篇符尧大佬的一篇数据工程(Data Engineering)的文章,解释了speed of grokking指标是什么,分析了数据工程
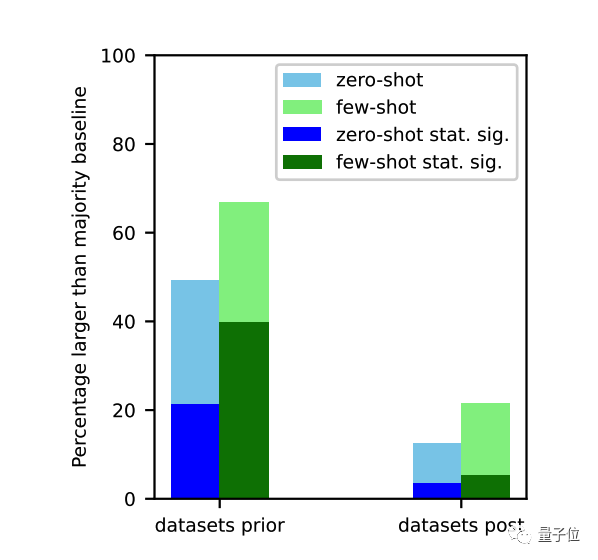
对于ChatGPT变笨原因,学术界又有了一种新解释。加州大学圣克鲁兹分校一项研究指出:在训练数据截止之前的任务上,大模型表现明显更好。

2023年的LLM开源社区都发生了什么?来自Hugging Face的研究员带你回顾并重新认识开源LLM
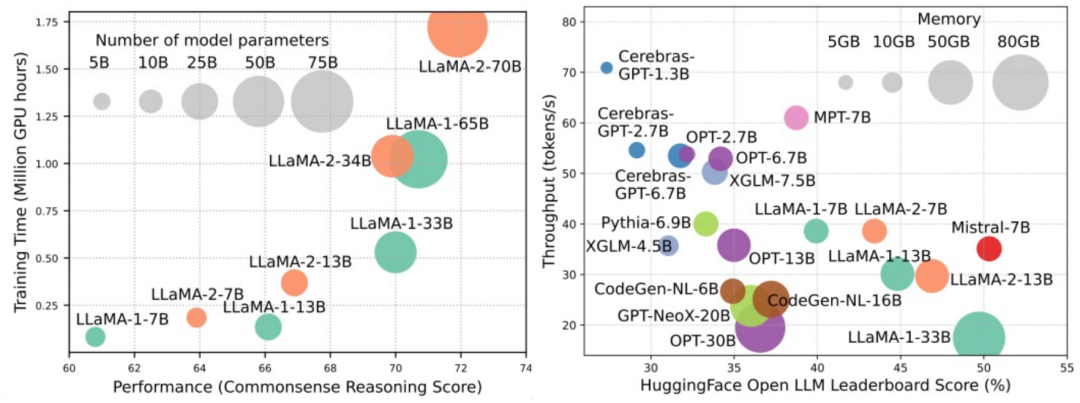
大规模语言模型(LLMs)在很多关键任务中展现出显著的能力,比如自然语言理解、语言生成和复杂推理,并对社会产生深远的影响。然而,这些卓越的能力伴随着对庞大训练资源的需求(如下图左)和较长推理时延(如下图右)。因此,研究者们需要开发出有效的技术手段去解决其效率问题。

向量存储检索是个真需求,然而专用向量数据库已经凉了。
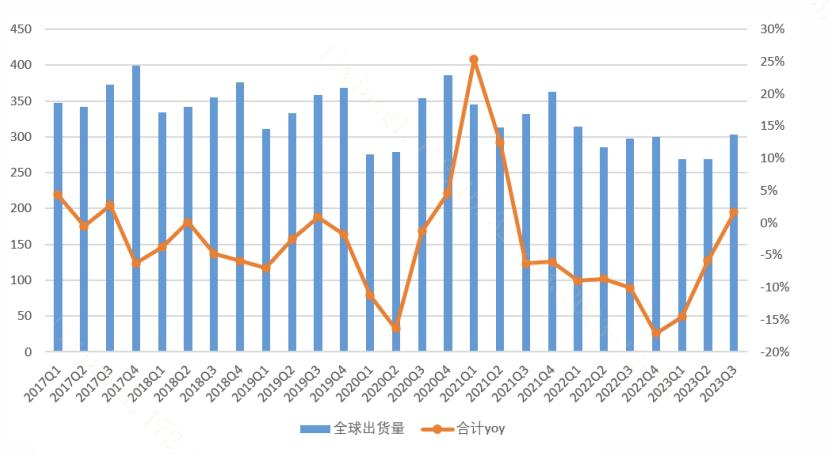
12月14-15日,2023年中国游戏产业年会在广州召开,会上发布年度游戏产业数据,数据显示2023年国内游戏行业重回增长通道,市场规模达到3029.6亿元,同比增长13.95%。
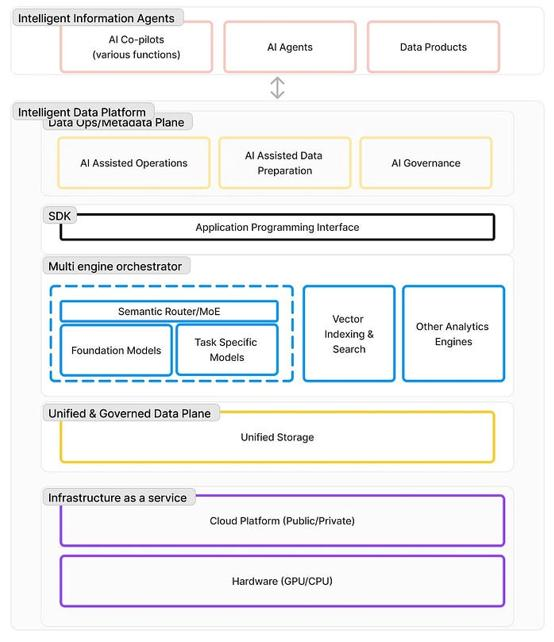
在 2023 年即将结束之际,我们会发现随着 ChatGPT 的引入,世界发生了不可逆转的变化。人工智能的主流化继续以强劲势头推进,我们如何应对这些不断变化的时代需要信念的飞跃。

深圳鲲云信息科技有限公司(以下简称「鲲云科技」)宣布完成数亿元C轮融资。此轮融资由普罗资本领投,鼎晖百孚、联通旗下联创基金、张科垚坤基金、钟楼金控集团跟投。本轮资金主要用于支持下一代可重构数据流CAISA AI芯片的研发和规模落地,构建CAISA芯片在各垂直行业的产业化生态。