

工业数据是生成式AI之后的创新点
工业数据是生成式AI之后的创新点搜索引擎、手机、电子商务、社交网站等的个人数据,仅占全世界数据量的1成。剩下的9成是工业数据,尚未得到加工利用。企业订单、物联网、汽车行驶数据等,这些企业数据一旦统合,将是一场革新。工业数据争夺将愈演愈烈……
来自主题: AI资讯
5435 点击 2023-11-23 15:27
搜索引擎、手机、电子商务、社交网站等的个人数据,仅占全世界数据量的1成。剩下的9成是工业数据,尚未得到加工利用。企业订单、物联网、汽车行驶数据等,这些企业数据一旦统合,将是一场革新。工业数据争夺将愈演愈烈……
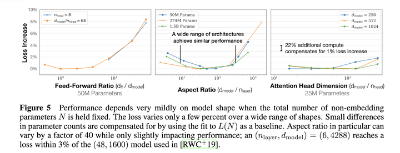
计划训练一个10B的模型,想知道至少需要多大的数据?收集到了1T的数据,想知道能训练一个多大的模型?老板准备1个月后开发布会,给的资源是100张A100,那应该用多少数据训一个多大模型最终效果最好?

C-MCR利用现有多模态对比表征间可能存在的重叠模态,来连接不同的对比表征,从而学到更多模态间的对齐关系,实现了在缺乏配对数据的多模态间进行训练。

微软在最近的Ignite大会上宣布了一系列以AI为中心的新产品和功能,包括自研芯片、端到端机架和数据平台等。微软已经成为全球最潮的科技公司之一。
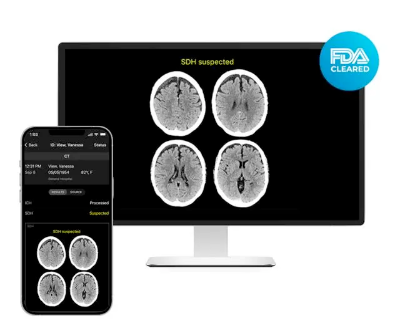
专注于人工智能医学影像分析的美国RapidAI公司宣布,美国食品药品监督管理局(FDA)批准其Rapid SDH用于美国的医院。Rapid SDH 由 AI (人工智能)提供支持,其AI 用过往的患者数据进行训练,以发现急性和慢性硬膜下血肿的潜在指标。
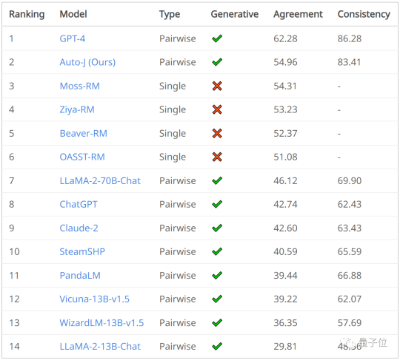
评估大模型对齐表现最高效的方式是?在生成式AI趋势里,让大模型回答和人类价值(意图)一致非常重要,也就是业内常说的对齐(Alignment)。
数据显示,2017年,医疗人工智能行业发展迅速。行业内仅对外公布的融资事件就有近30起,融资总额超过18亿元人民币,其中,推想医疗、深睿医疗、图玛深维等均在一年内获得两次融资,且融资规模在亿元以上。
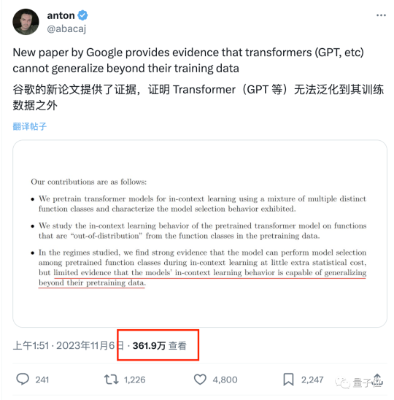
针对Transformer,谷歌DeepMind一项新的发现引起了不小争议: 它的泛化能力,无法扩展到训练数据以外的内容。

生成式AI的快速发展带来了一系列风险和挑战,包括碳足迹、虚假信息、语境理解不足、数据依赖、舆论操纵、对人类生存的威胁、专用模型前景、存在偏见、伦理问题和是否取代人类创造力等。

LLM这个缩写在机器翻译中被误解为“法学硕士”,而不是“大语言模型”。 • 机器翻译系统通常依赖上下文和大量文本数据来学习翻译,导致LLM更容易被翻译成“法学硕士”。