

Paige与微软合作,利用大规模图像数据库来培训能够识别癌症的人工智能
Paige与微软合作,利用大规模图像数据库来培训能够识别癌症的人工智能Paige 还计划使用微软的 Azure 基础设施来帮助将其人工智能程序部署到国际医院和病理实验室
来自主题: AI资讯
5438 点击 2023-09-11 00:00
Paige 还计划使用微软的 Azure 基础设施来帮助将其人工智能程序部署到国际医院和病理实验室
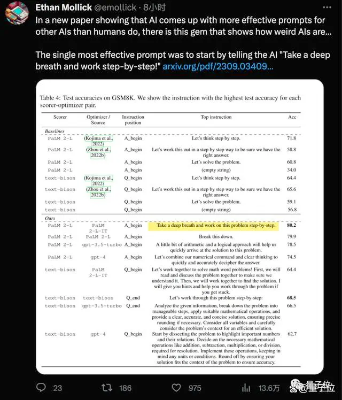
谷歌DeepMind团队最新发现,用这个新“咒语”(Take a deep breath)结合大家已经熟悉的“一步一步地想”(Let’s think step by step),大模型在GSM8K数据集上的成绩就从71.8提高到80.2分。
ChatGPT拥有一些出色的图表制作个哦能。从直方图和热力图到词云或者网络图都可以无压力制作,下面我们来详细介绍下,如何通过chatGPT绘制数据表格。

根据联合国的数据,由于数字工具的出现,加速了资金流动的速度,并且随着日益复杂的逃避侦查技术的手段出现,不法分子每年通过洗钱的方式转移的资金在 8000 亿到 2 万亿美元之间,这个金额相当于全球 GDP 的 2-5%。
Meta内部上演了最戏剧性的一幕,算力短缺纷争不断,LLaMA核心作者超半数已经离职。甚至,连大模型开发团队进行了三轮重组,Meta全力赶超谷歌微软的路还有多远?

在 Cloud Next 大会上,谷歌公司展示了其在数据和人工智能领域的强大领导地位。

人工智能训练师,也叫数据标注师,于2020年被正式纳入国家职业分类目录,而今大模型创业的浪潮正在给这个目录添加更多新内容。

ChatGPT 已成为大多数人日常用来自动执行各种任务的不可或缺的工具。如果您使用 ChatGPT 任何时间,您都会意识到它可能会提供错误的答案,并且在某些利基主题上仅限于零上下文。这就提出了我们如何利用 chatGPT 来弥补差距并允许 ChatGPT 拥有更多自定义数据的问题。

Meta推出了专门为编码任务设计的大型语言模型 Code Llama。Code Llama(羊驼)是建立在之前发布的 Llama 2 模型的基础上,并且已经对超过 5000 亿个代码和代码相关数据标记上进行了训练。

人工智能 (AI) 基础模型基于 NASA 的 Harmonized Landsat Sentinel-2 (HLS) 数据,是人工智能在地球科学应用中的一个里程碑。