
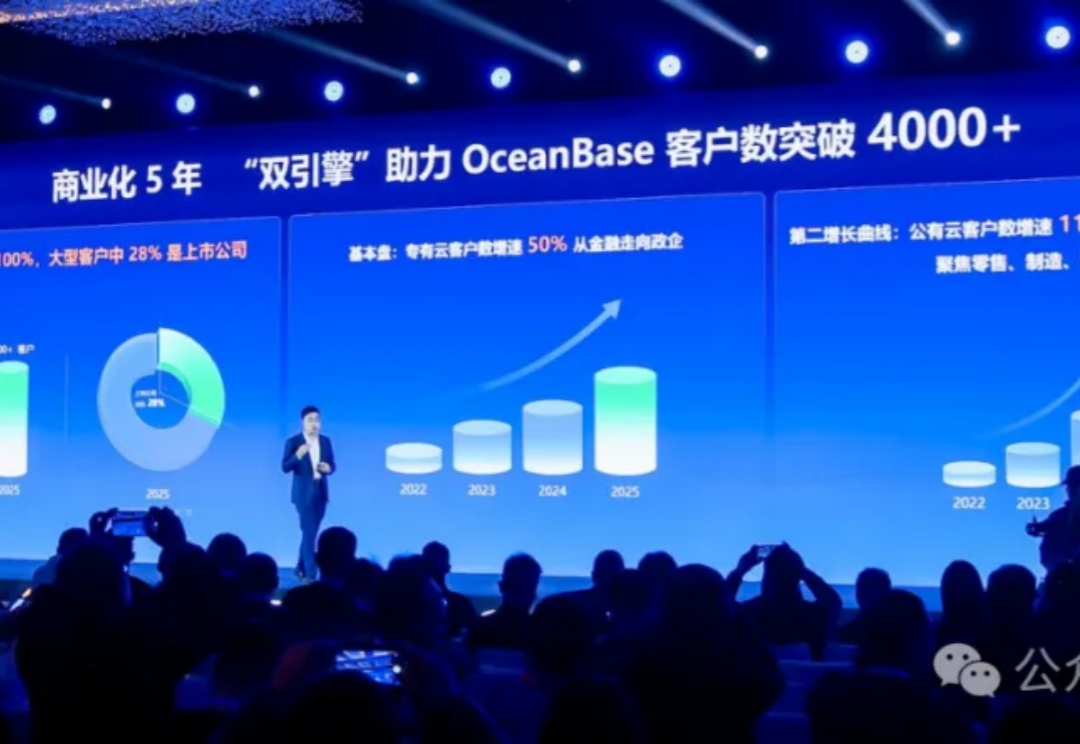
三行代码就能手搓一个AI应用!蚂蚁OceanBase开源其首款AI数据库
三行代码就能手搓一个AI应用!蚂蚁OceanBase开源其首款AI数据库AI时代,真是啥都要快。
来自主题: AI资讯
10231 点击 2025-11-20 10:07
AI时代,真是啥都要快。

在视觉处理任务中,Vision Transformers(ViTs)已发展成为主流架构。然而,近期研究表明,ViT 模型的密集特征中会出现部分与局部语义不一致的伪影(artifact),进而削弱模型在精细定位类任务中的性能表现。因此,如何在不耗费大量计算资源的前提下,保留 ViT 模型预训练核心信息并消除密集特征中的伪影?

在腾讯四年,朱庆旭曾将多种训练数据喂给具身模型,最终他得出结论:“基于遥操作数据训练的主流方案,有着原理性缺陷。”
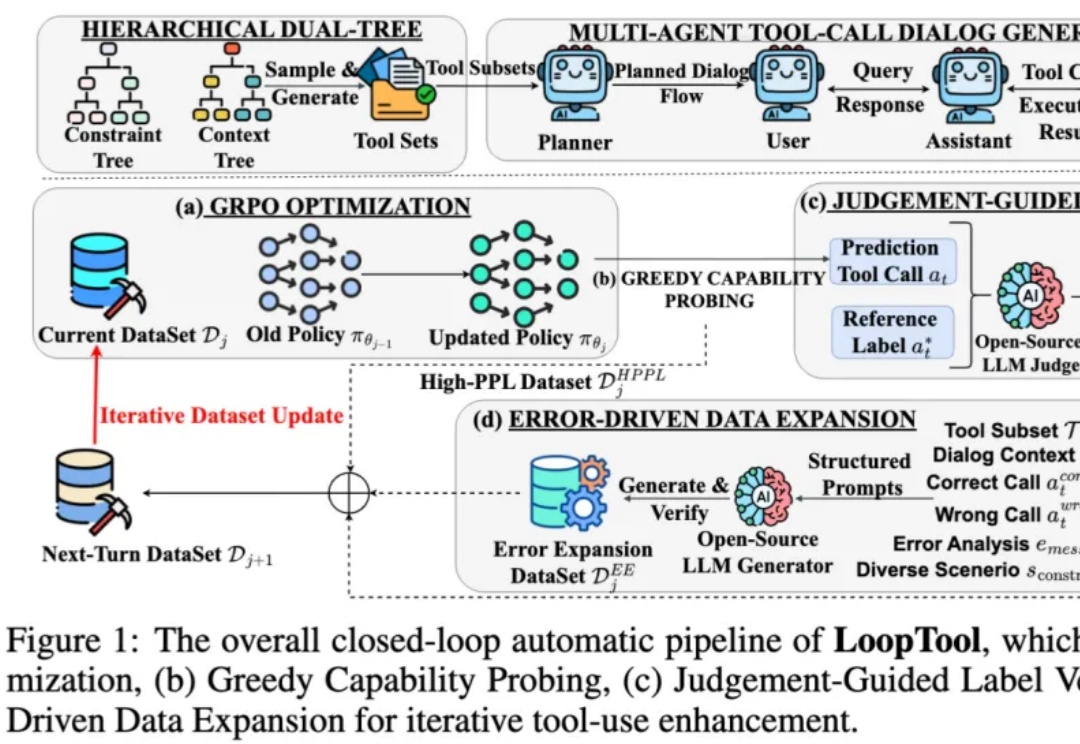
在过去两年,大语言模型 (LLM) + 外部工具的能力,已成为推动 AI 从 “会说” 走向 “会做” 的关键机制 —— 尤其在 API 调用、多轮任务规划、知识检索、代码执行等场景中,大模型要想精准调用工具,不仅要求模型本身具备推理能力,还需要借助海量高质量、针对性强的函数调用训练数据。
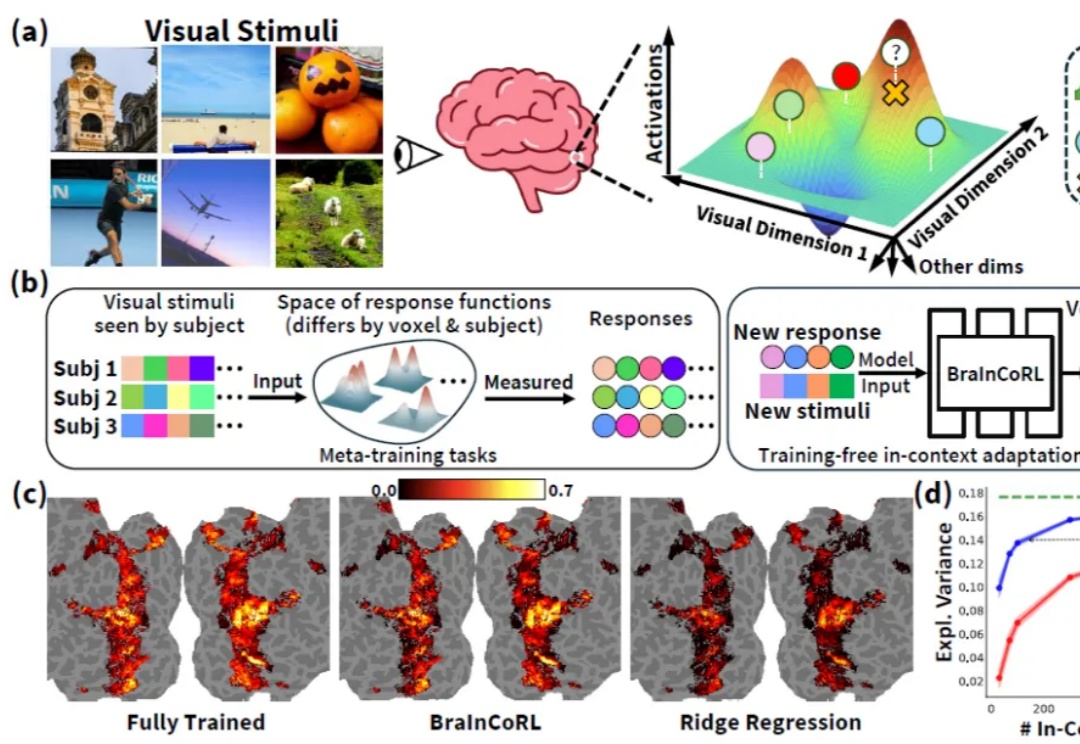
人类高级视觉皮层在个体间存在显著的功能差异,而构建大脑编码模型(brain encoding models)—— 即能够从视觉刺激(如图像)预测人脑神经响应的计算模型 —— 是理解人类视觉系统如何表征世界的关键。传统视觉编码模型通常需要为每个新被试采集大量数据(数千张图像对应的脑活动),成本高昂且难以推广。

AI智能体正把医疗AI从「看片子」升级成会思考、能行动的「医生搭档」。研究人员发表的最新综述,用通俗语言拆解智能体如何读懂多模态数据、像专家一样规划决策,又能扮演医生、护士、健康管家等多重角色;同时提醒:越智能越危险,必须配套严格评估、隐私保护与伦理护栏,才敢让它走进真实诊疗。
最近风投机构对所谓"新实验室"有一系列投资动向。

具身智能的Scaling Law正蓄势待发。

港大、港科大与西电团队登上Nature子刊,破解AI芯片核心难题。他们攻克存算一体架构中模数转换器(ADC)这个占能耗87%的「黑洞」,利用忆阻器可编程特性打造能自适应数据分布的「智能标尺」,使AI芯片功耗锐减57.2%,面积缩小30.7%,为下一代高效AI硬件系统开辟新路。

长期以来,多模态代码生成(Multimodal Code Generation)的训练严重依赖于特定任务的监督微调(SFT)。尽管这种范式在 Chart-to-code 等单一任务上取得了显著成功 ,但其 “狭隘的训练范围” 从根本上限制了模型的泛化能力,阻碍了通用视觉代码智能(Generalized VIsioN Code Intelligence)的发展 。