

第一次,多模态大模型学会边看边听,Meta新作性能暴涨113%
第一次,多模态大模型学会边看边听,Meta新作性能暴涨113%Meta联合多所高校发布首个可规模化自动生成第一视角音视频理解数据的引擎EgoAVU ,让多模态大模型首次真正「听懂世界」。
来自主题: AI技术研报
8723 点击 2026-02-28 15:26
Meta联合多所高校发布首个可规模化自动生成第一视角音视频理解数据的引擎EgoAVU ,让多模态大模型首次真正「听懂世界」。
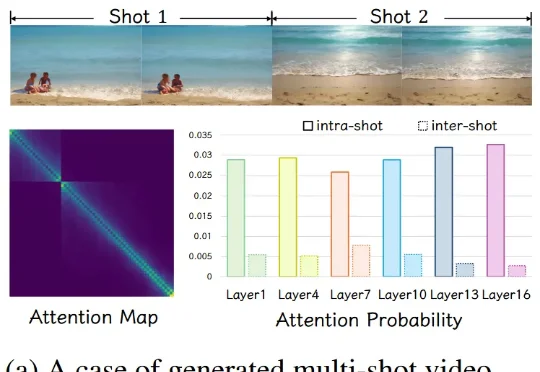
基于对注意力特性的观察,CineTrans 提出块对角掩码的通用机制,使视频生成模型能高效地自动化转场。为了进一步提升转场模型的效果和准确性,作者设计了详细的多镜头视频生产管线,并收集了一个高质量、多镜头数据集 Cine250K,大幅提升多镜头转场视频生成的效果。作为首个时间级可控的自动化转场模型,CineTrans 为这一领域的众多后续方法提供了关键技术。

GeoPT提出了一种全新的动力学提升预训练范式,通过合成动力学(Synthetic Dynamics)将静态几何“提升”到动态空间,让模型在无标签数据上通过学习粒子轨迹演化来获取物理直觉。
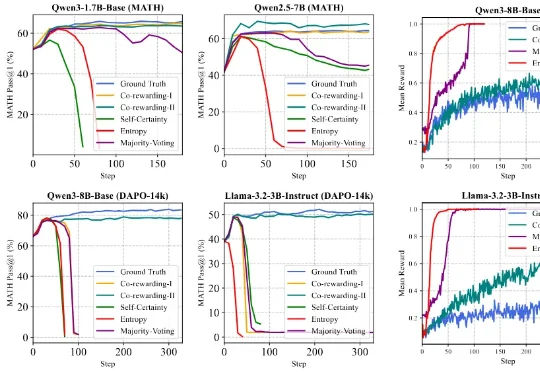
针对这一挑战,来自香港浸会大学和上海交通大学的可信机器学习和推理组提出了一个全新的自监督 RL 框架 ——Co-rewarding。该框架通过在数据端或模型端引入互补视角的自监督信号,稳定奖励获取,提升 RL 过程中模型奖励投机的难度,从而有效避免 RL 训练崩溃,实现稳定训练和模型推理能力的诱导。

奥特曼又又又又口出狂言了。在印度 Express Adda 的论坛上,Sam Altman 聊了很多 AI 话题,从 AGI 到中美 AI 竞争,再到数据中心用水问题。但最火的那段,是他回应 AI 能耗批评时说的:「人们总谈训练 AI 模型需要多少能源……但训练人类也需要大量能源,得花 20 年时间,消耗那么多食物,才能变聪明。」
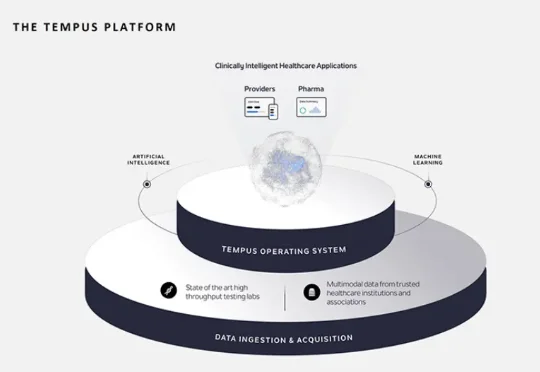
「中国巴菲特」段永平,押注AI医疗。 数据显示,段永平Q4买入了AI医疗公司Tempus AI,新进11万股。 段永平曾一手打造小霸王、步步高,还是OPPO、vivo的幕后奠基人;之后退居幕后转向投资
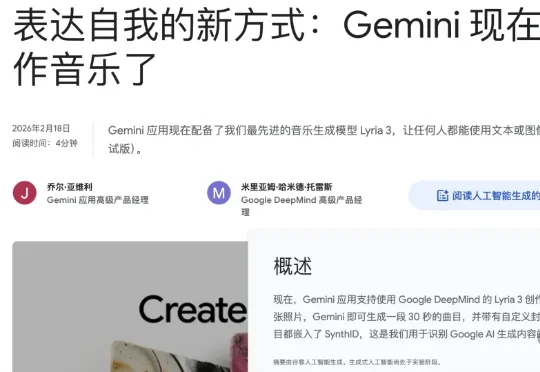
谷歌在 7.5 亿月活的 Gemini 中上线了 AI 音乐生成功能,输入一句话或一张照片,几秒就能得到一首带人声和歌词的完整歌曲。背后是 DeepMind 最新的 Lyria 3 模型,训练数据超 200 万首曲目。对 Suno 等 AI 音乐创业公司而言,竞争从此不再只是比模型,更是要比入口。
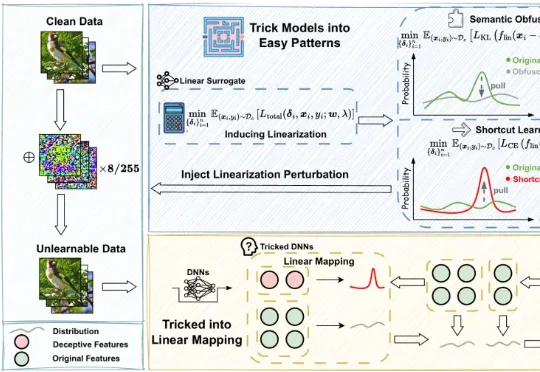
不可学习样本(Unlearnable Examples)是一类用于数据保护的技术,其核心思想是在原始数据中注入人类难以察觉的微小扰动,使得未经授权的第三方在使用这些数据训练模型时,模型的泛化性能显著下降,甚至接近随机猜测,从而达到阻止数据被滥用的目的。
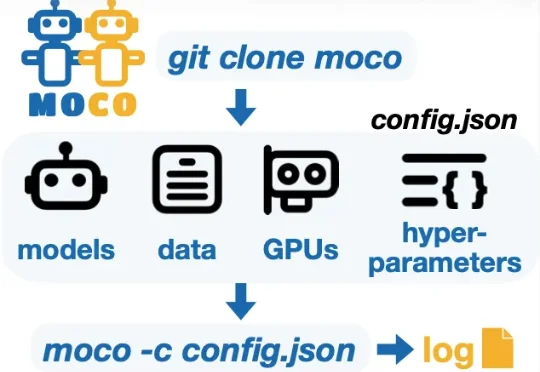
为了支持多模型协同研究并加速这一未来愿景的实现,华盛顿大学 (University of Washington) 冯尚彬团队联合斯坦福大学、哈佛大学等研究人员提出 MoCo—— 一个针对多模型协同研究的 Python 框架。MoCo 支持 26 种在不同层级实现多模型交互的算法,研究者可以灵活自定义数据集、模型以及硬件配置,比较不同算法,优化自身算法,以此构建组合式人工智能系统。MoCo 为设计、
其依据是Micro1的25亿美元(约合人民币173亿元)最新估值。福布斯报道称,成立于2022年的Micro1被曝正在以25亿美元估值洽谈新融资,如果Micro1锁定或超过这一估值,安萨里在该公司持有的约42%股份价值将超过10亿美元(约合人民币69亿元)。