
深度|具身合成数据的路线之争,谁将率先走出困境?
深度|具身合成数据的路线之争,谁将率先走出困境?本文主要描述了具身合成数据两条主要技术路线之争:“视频合成+3D重建”or “端到端3D生成”。参考自动驾驶的成功经验,前者模态转换链路过长导致误差累积,'直接合成3D数据'理论上有信息效率优势,但需要克服“常识欠缺”等挑战。
来自主题: AI技术研报
11525 点击 2025-04-09 10:07
本文主要描述了具身合成数据两条主要技术路线之争:“视频合成+3D重建”or “端到端3D生成”。参考自动驾驶的成功经验,前者模态转换链路过长导致误差累积,'直接合成3D数据'理论上有信息效率优势,但需要克服“常识欠缺”等挑战。

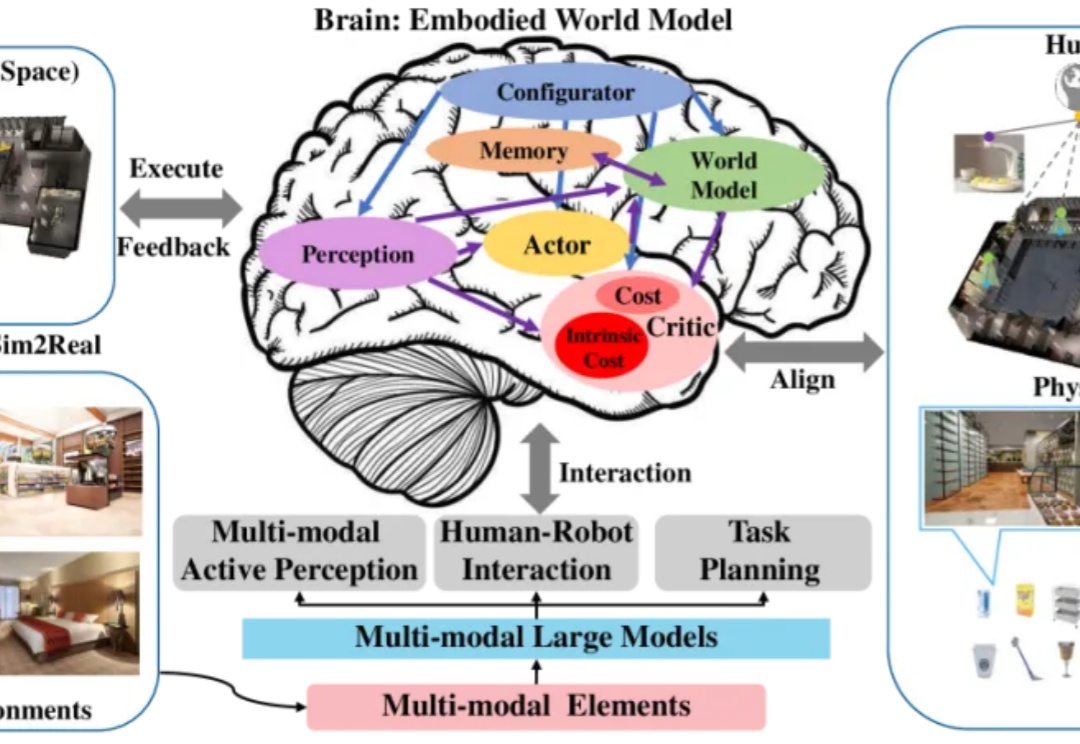
大规模数据集和标准化评估基准显著促进了自然语言处理和计算机视觉领域的发展。然而,机器人领域在如何构建大规模数据集并建立可靠的评估体系方面仍面临巨大挑战。
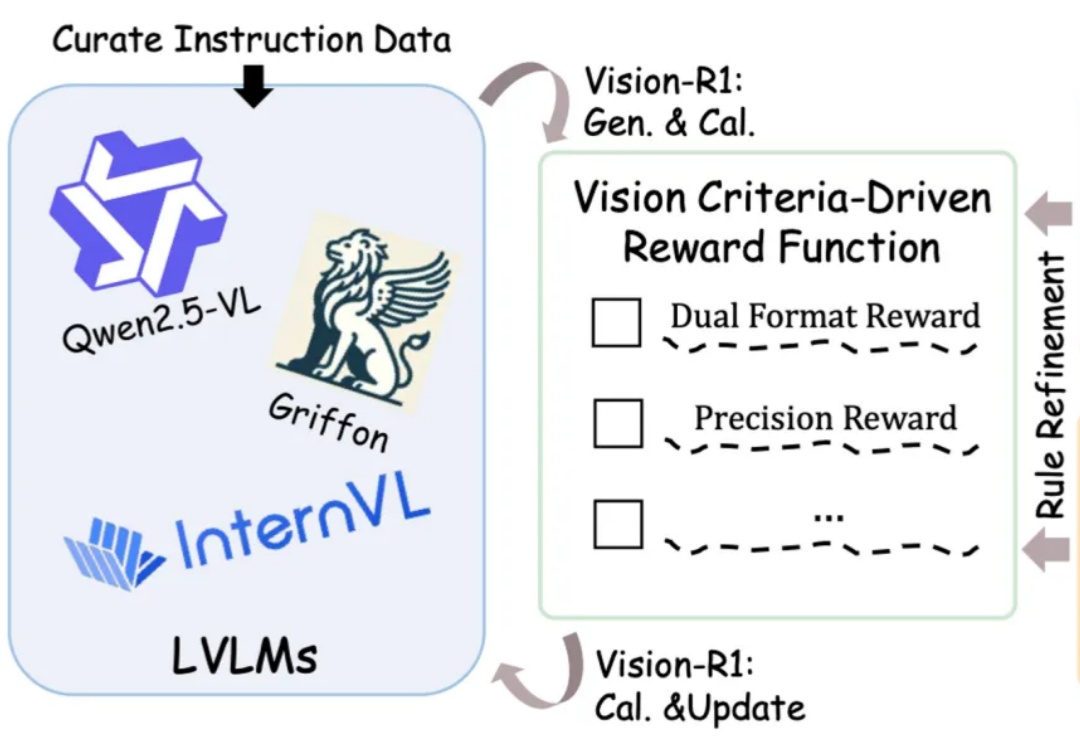
图文大模型通常采用「预训练 + 监督微调」的两阶段范式进行训练,以强化其指令跟随能力。受语言领域的启发,多模态偏好优化技术凭借其在数据效率和性能增益方面的优势,被广泛用于对齐人类偏好。目前,该技术主要依赖高质量的偏好数据标注和精准的奖励模型训练来提升模型表现。然而,这一方法不仅资源消耗巨大,训练过程仍然极具挑战。
如何让大模型更懂「人」?

让大语言模型更懂特定领域知识,有新招了!
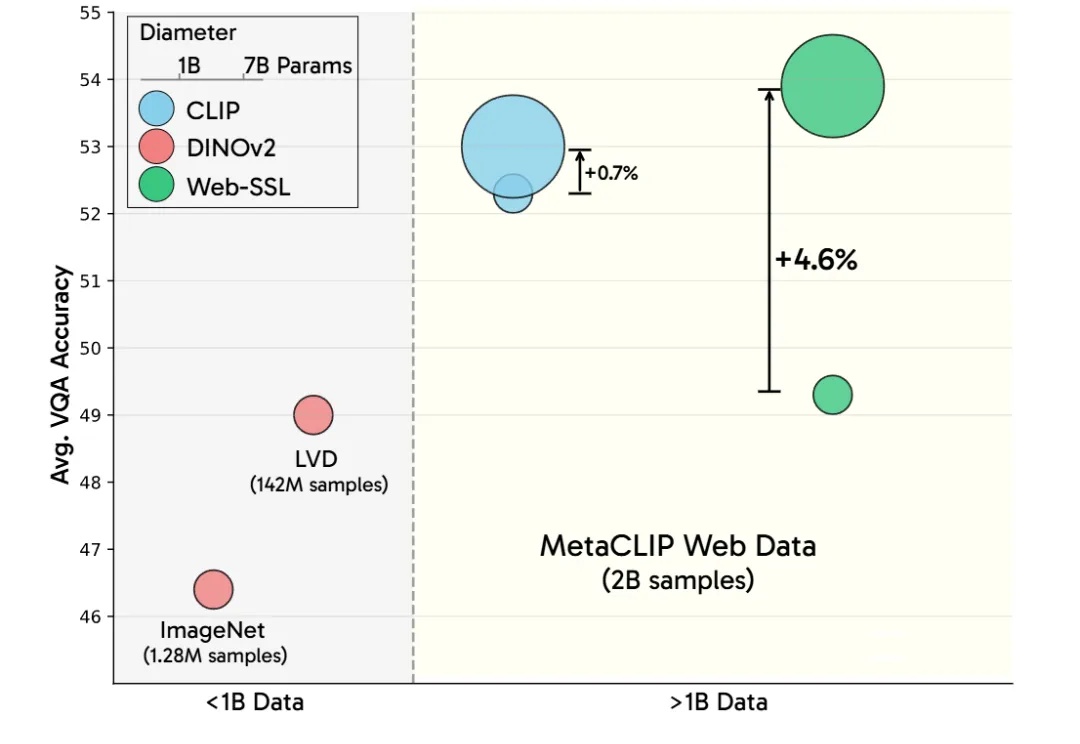
LeCun谢赛宁等研究人员通过新模型Web-SSL验证了SSL在多模态任务中的潜力,证明其在扩展模型和数据规模后,能媲美甚至超越CLIP。这项研究为无语言监督的视觉预训练开辟新方向,并计划开源模型以推动社区探索。

AI爬虫是互联网最顽固的「蟑螂」,不讲规则、压垮网站,令开发者深恶痛绝。面对这种AI时代的「DDoS攻击」,极客们用智慧反击:或设「神之审判」Anubis,或制造数据陷阱,以幽默和代码让机器人自食其果。这场攻防战,正演变成一场精彩绝伦的网络博弈。

不是我说,年轻人群体到底怎么看AI、用AI啊???

在人工智能飞速发展的今天,LLM 的能力令人叹为观止,但其局限性也日益凸显 —— 它们往往被困于训练数据的「孤岛」,无法直接触及实时信息或外部工具。

自2022年11月,美国硅谷初创公司OpenAI推出首款基于大语言模型的现象级聊天机器人ChatGPT以来,AI技术与我们的生活日益紧密。然而,大模型降世两年多,人们却吃惊地发现,自己最终的那个梦想,一个有强大AI为人类工作的社会,一个有更多的闲暇,上四休三甚至每周工作更短时间的世界,却仿佛更遥远了,我们变得更忙了,而且,这个事实居然在数据上得到了确认。