开源模型突破原生多模态大模型性能瓶颈,上海AI Lab代季峰团队出品
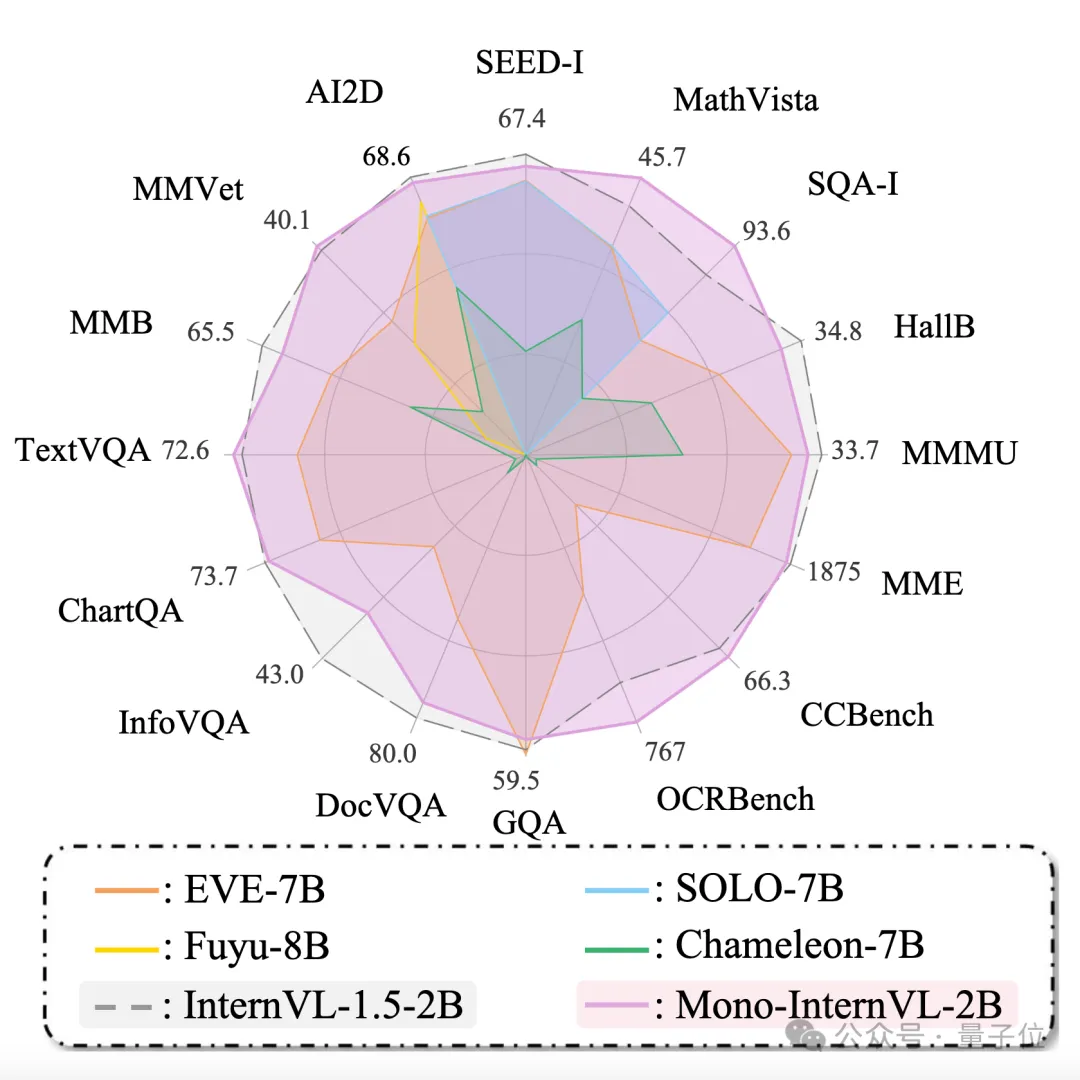
开源模型突破原生多模态大模型性能瓶颈,上海AI Lab代季峰团队出品原生多模态大模型性能瓶颈,迎来新突破! 上海AI Lab代季峰老师团队,提出了全新的原生多模态大模型Mono-InternVL。 与非原生模型相比,该模型首个单词延迟最多降低67%,在多个评测数据集上均达到了SOTA水准。
来自主题: AI技术研报
6585 点击 2024-10-25 15:37
 搜索
搜索
原生多模态大模型性能瓶颈,迎来新突破! 上海AI Lab代季峰老师团队,提出了全新的原生多模态大模型Mono-InternVL。 与非原生模型相比,该模型首个单词延迟最多降低67%,在多个评测数据集上均达到了SOTA水准。
「这才是开放研究该有的样子。」 经常刷 arXiv 的同学,你有没有发现页面上多了个新功能?这个新功能(图中的「Hugging Face」按钮)隐藏在「Code, Data, Media」选项卡下,选中之后就可以直达相关的 Hugging Face 论文、模型和数据集。

Time-MoE采用了创新的混合专家架构,能以较低的计算成本实现高精度预测。研发团队还发布了Time-300B数据集,为时序分析提供了丰富的训练资源,为各行各业的时间序列预测任务带来了新的解决方案。

视频多模态大模型(LMMs)的发展受限于从网络获取大量高质量视频数据。为解决这一问题,我们提出了一种替代方法,创建一个专为视频指令跟随任务设计的高质量合成数据集,名为 LLaVA-Video-178K。

大语言模型(LLM)正在推动通信行业向智能化转型,在自动生成网络配置、优化网络管理和预测网络流量等方面展现出巨大潜力。未来,LLM在电信领域的应用将需要克服数据集构建、模型部署和提示工程等挑战,并探索多模态集成、增强机器学习算法和经济高效的模型压缩技术。
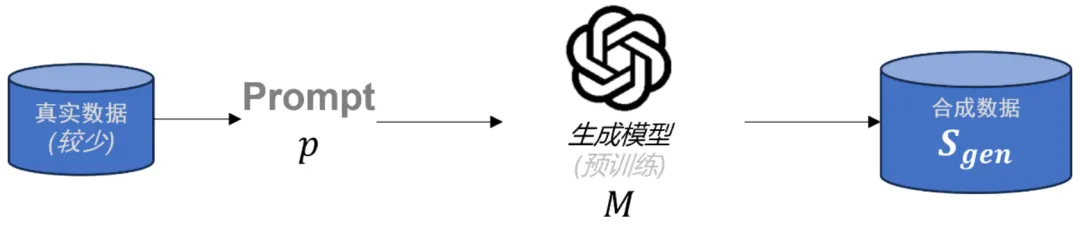
在大语言模型(LLMs)后训练任务中,由于高质量的特定领域数据十分稀缺,合成数据已成为重要资源。虽然已有多种方法被用于生成合成数据,但合成数据的理论理解仍存在缺口。为了解决这一问题,本文首先对当前流行的合成数据生成过程进行了数学建模。

LightRAG通过双层检索范式和基于图的索引策略提高了信息检索的全面性和效率,同时具备对新数据快速适应的能力。在多个数据集上的实验表明,LightRAG在检索准确性和响应多样性方面均优于现有的基线模型,并且在资源消耗和动态环境适应性方面表现更优,使其在实际应用中更为有效和经济。

经过三年的努力,ImageNet成为了一个包含1500万张互联网图像的数据集,涵盖了22000个物体类别概念。

传统的歌声任务,如歌声合成,大多是在利用输入的歌词和乐谱生成高质量的歌声。随着深度学习的发展,人们希望实现可控和能个性化定制的歌声生成。

美司法部考虑强制谷歌拆分,解决垄断问题。