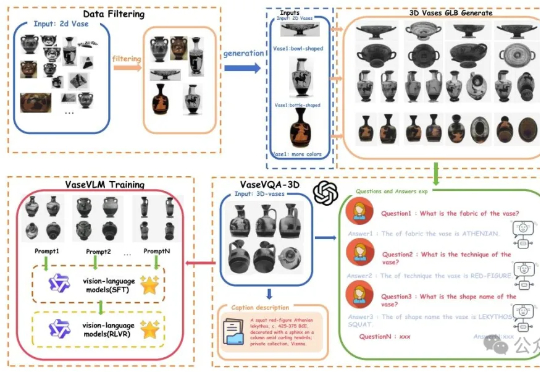
北大团队让AI学会考古!全球首个古希腊陶罐3D视觉问答数据集发布,还配了专用模型
北大团队让AI学会考古!全球首个古希腊陶罐3D视觉问答数据集发布,还配了专用模型现在AI都懂文物懂历史了。一项来自北京大学的最新研究引发关注:他们推出了全球首个面向古希腊陶罐的3D视觉问答数据集——VaseVQA-3D,并配套推出了专用视觉语言模型VaseVLM。这意味着,AI正在从“识图机器”迈向“文化考古Agent”。
来自主题: AI技术研报
8964 点击 2025-11-07 14:49
 搜索
搜索
现在AI都懂文物懂历史了。一项来自北京大学的最新研究引发关注:他们推出了全球首个面向古希腊陶罐的3D视觉问答数据集——VaseVQA-3D,并配套推出了专用视觉语言模型VaseVLM。这意味着,AI正在从“识图机器”迈向“文化考古Agent”。

数据集蒸馏是一种用少量合成数据替代全量数据训练模型的技术,能让模型高效又节能。WMDD和GUARD两项研究分别解决了如何保留原始数据特性并提升模型对抗扰动能力的问题,使模型在少量数据上训练时既准确又可靠。

在开放研究领域里,苹果似乎一整个脱胎换骨,在纯粹的研究中经常会有一些出彩的工作。这次苹果发布的研究成果的确出人意料:他们用谷歌的 Nano-banana 模型做个了视觉编辑领域的 ImageNet。
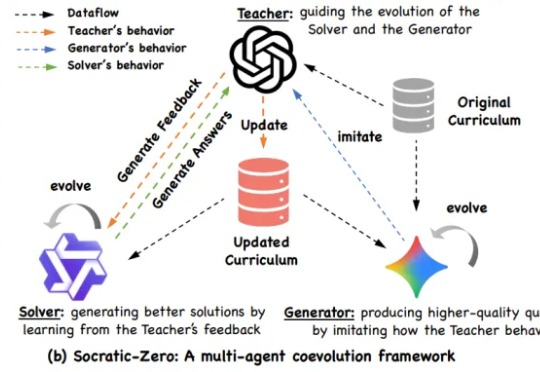
阿里巴巴与上海交通大学 EPIC Lab 联合提出 Socratic-Zero,一个完全无外部数据依赖的自主推理训练框架。该方法仅从 100 个种子问题出发,通过三个智能体的协同进化,自动生成高质量、难度自适应的课程,并持续提升模型推理能力。

在金融、医疗等高度敏感的应用场景中,拜占庭鲁棒联邦学习(BRFL)能够有效避免因数据集中存储而导致的隐私泄露风险,同时防止恶意客户端对模型训练的攻击。然而,即使是在模型更新的过程中,信息泄露的威胁仍然无法完全规避。为了解决这一问题,全同态加密(FHE)技术通过在密文状态下进行安全计算,展现出保护隐私信息的巨大潜力。

复旦大学NLP实验室研发Game-RL,利用游戏丰富视觉元素和明确规则生成多模态可验证推理数据,通过强化训练提升视觉语言模型的推理能力。创新性地提出Code2Logic方法,系统化合成游戏任务数据,构建GameQA数据集,验证了游戏数据在复杂推理训练中的优势。
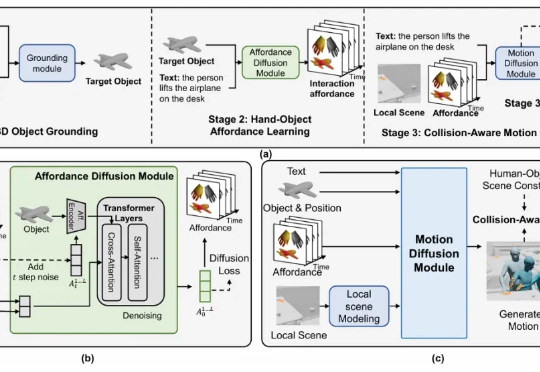
该研究首次提出了含可移动物体的 3D 场景中,基于文本的人 - 物交互生成任务,并构建了大规模数据集与创新方法框架,在多个评测指标上均取得了领先效果。
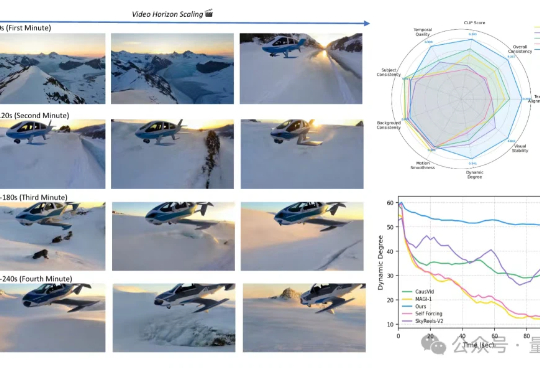
从5秒到4分钟,Sora2也做不到的分钟级长视频生成,字节做到了!这就是字节和UCLA联合提出的新方法——Self-Forcing++,无需更换模型架构或重新收集长视频数据集,就能轻松生成分钟级长视频,也不会后期画质突然变糊或卡住。
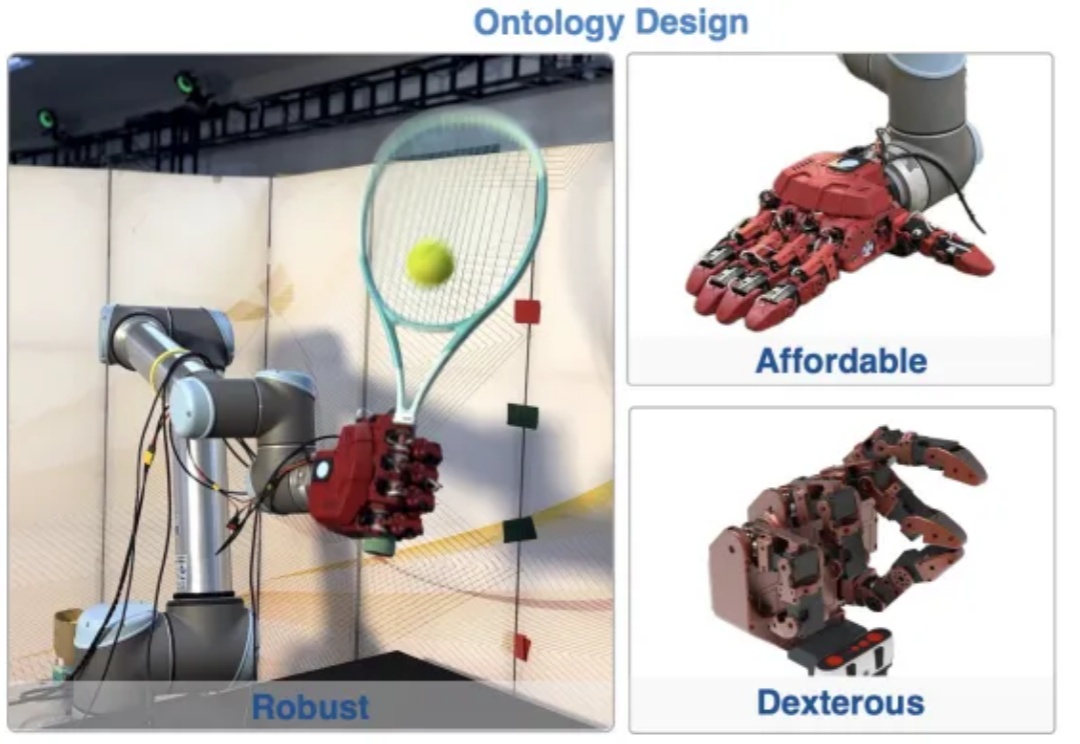
在最近的一篇 NeurIPS 25 中稿论文中,来自中山大学、加州大学 Merced 分校、中科院自动化研究所、诚橙动力的研究者联合提出了一个全新开源的高自由度灵巧手平台 — RAPID Hand (Robust, Affordable, Perception-Integrated, Dexterous Hand)。

图片来源:David AI Labs David AI Labs 这家初创公司通过出售音频数据集来帮助训练人工智能模型,近期在新一轮融资中从投资者处筹集了 5000 万美元——这表明为 AI 开发提供