
比Flux更强大的文生图模型来了!秘诀是“集百家之长”
比Flux更强大的文生图模型来了!秘诀是“集百家之长”打造更强大文生图模型新思路有—— 面对Flux、stable diffusion、Omost等爆火模型,有人开始主打“集各家所长”。
来自主题: AI资讯
10035 点击 2024-10-19 10:21
 搜索
搜索
打造更强大文生图模型新思路有—— 面对Flux、stable diffusion、Omost等爆火模型,有人开始主打“集各家所长”。
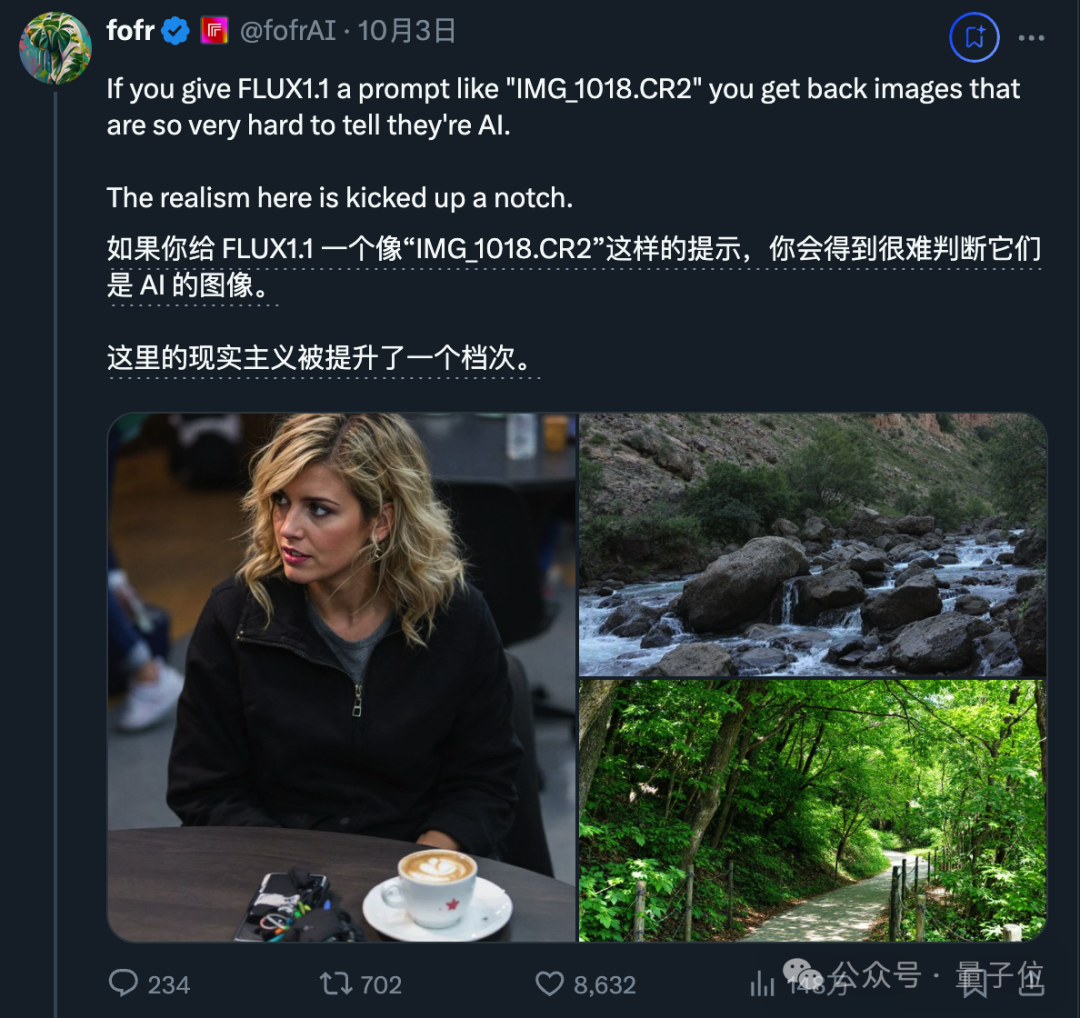
最新AI文生图模型Flux1.1,一夜刷屏。
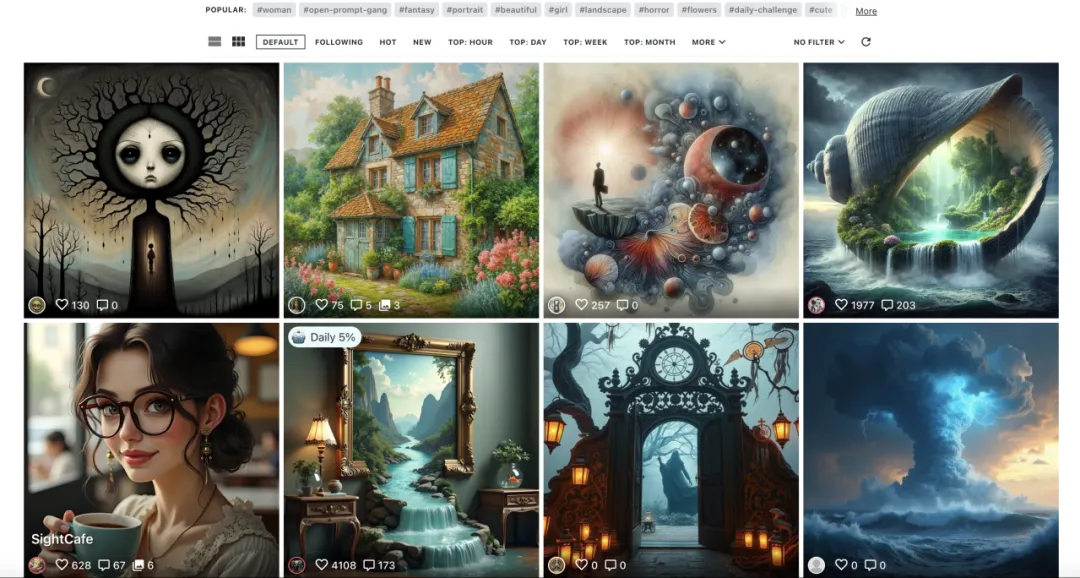
Flux 带起又一波文生图模型的热潮,NightCafe 是其中的受益者之一。

前两天Ideogram 更新了 2.0版本,并且现在可以免费体验。

随着大模型的落地按下加速键,文生图无疑是最火热的应用方向之一。
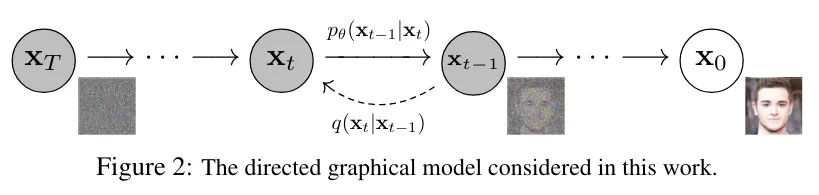
近日,来自加州大学尔湾分校等机构的研究人员,利用延迟掩蔽、MoE、分层扩展等策略,将扩散模型的训练成本降到了1890美元。

最强开源文生图模型一夜易主! 智东西8月2日报道,昨日晚间,开源文生图模型霸主Stable Diffusion原班人马,宣布推出全新的图像生成模型FLUX.1。
只需Image Tokenizer,Llama也能做图像生成了,而且效果超过了扩散模型。

超越扩散模型!自回归范式在图像生成领域再次被验证——
OpenAI在5月14日推出了新一代人工智能模型GPT-4o,支持文本、音频和图像的任意组合输入,并能够生成文本、音频和图像的任意组合输出。仅仅一天后,谷歌就在新一届I/O开发者大会上发布、更新了十多款产品,包括AI助手Project Astra、文生图模型Imagen3、对标Sora的文生视频模型Veo,以及备受瞩目的大模型Gemini 1.5 Pro的升级版。