
大模型一体机塞进这款游戏卡,价格砍掉一个数量级
大模型一体机塞进这款游戏卡,价格砍掉一个数量级基于锐炫™ A770显卡的大模型一体机,在性价比上真的是太香了。它非常适合30-50人规模的团队来使用。一个“性价比”关键词,道破了为什么大模型一体机里面会出现英特尔游戏卡。
来自主题: AI资讯
9923 点击 2025-04-09 17:10
 搜索
搜索
基于锐炫™ A770显卡的大模型一体机,在性价比上真的是太香了。它非常适合30-50人规模的团队来使用。一个“性价比”关键词,道破了为什么大模型一体机里面会出现英特尔游戏卡。
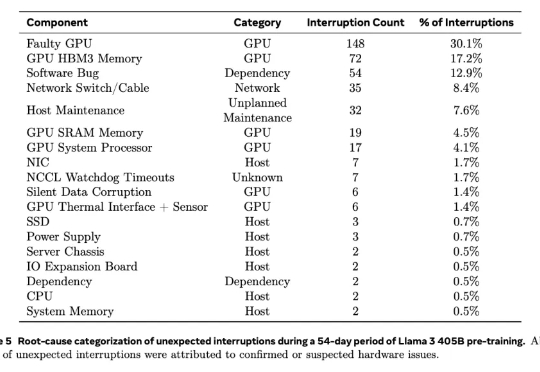
根据去年2024年7月28日Meta公司在训练大模型(Llama 3)时使用“16384 个 英伟达H100 GPU 集群”的经验,该显卡在高负载、大规模集群运行环境下容易出现以下故障点:

在主流电商平台,Go2 目前起售价接近 1 万块,与一张普通显卡的价格相当,这个价位也让其更像是一款面向市场的、相对高端的消费电子产品。或许正是因为 Go2 价格相对「亲民」且定位贴近大众,知名维修网站 iFixit 也将目光投向了这款机器狗,并特别邀请了机器人专家 Marcel Stieber 对其进行了一次深入的拆解。
仅用32B,就击败o1-mini追平671B满血版DeepSeek-R1!阿里深夜重磅发布的QwQ-32B,再次让全球开发者陷入狂欢:消费级显卡就能跑,还一下子干到推理模型天花板!
满血版DeepSeek R1部署A100,基于INT8量化,相比BF16实现50%吞吐提升! 美团搜推机器学习团队最新开源,实现对DeepSeek R1模型基本无损的INT8精度量化。
Ilya Sutskever 在 NeurIPS 会上直言:大模型预训练这条路可能已经走到头了。上周的 CES 2025,黄仁勋有提到,在英伟达看来,Scaling Laws 仍在继续,所有新 RTX 显卡都在遵循三个新的扩展维度:预训练、后训练和测试时间(推理),提供了更佳的实时视觉效果。

在美国发布AI禁令后,特朗普随即宣布了一项预算高达5000亿美元的AGI计划——星际之门,以保证其在AI领域的领先地位。而在大洋彼岸的中国,一家名为Deepseek的中国创业公司,只用了2048块显卡,就训练出了一个能与顶级模型相媲美的Deepseek-V3模型。

本周三,各路媒体对英伟达 GeForce RTX 5090 的评测宣告解禁。基于最新 Blackwell 架构,新一代旗舰显卡无疑将成为未来几年你能买到的最好的显卡。

英伟达针对中国市场即将发售的RTX 5090D被曝出无法「炼丹」,3秒即可自动锁死算力。而且也不再支持多卡服务器配置与超频。该显卡或成「笼中金雀」,只能供游戏党细细赏玩了。

MuseAI 是由阿里集团爱橙科技研发的面向阿里内部的 AIGC 创作工作台,同时通过与阿里云旗下魔搭社区合作共建的形式,将主体能力通过魔搭社区的 AIGC 专区对公众开放。