
智能体工程火爆中美!猎豹CEO亲自开播春节“养龙虾”经历!X疯传:如何成为世界级 Agent 工程师
智能体工程火爆中美!猎豹CEO亲自开播春节“养龙虾”经历!X疯传:如何成为世界级 Agent 工程师Agentic Engineering 这个词刚被大神 Karpathy 提出了 1 个月,就已经有了不少大佬现身说法如何管理你的 Agent团队了。
来自主题: AI资讯
8528 点击 2026-03-05 14:55
 搜索
搜索
Agentic Engineering 这个词刚被大神 Karpathy 提出了 1 个月,就已经有了不少大佬现身说法如何管理你的 Agent团队了。
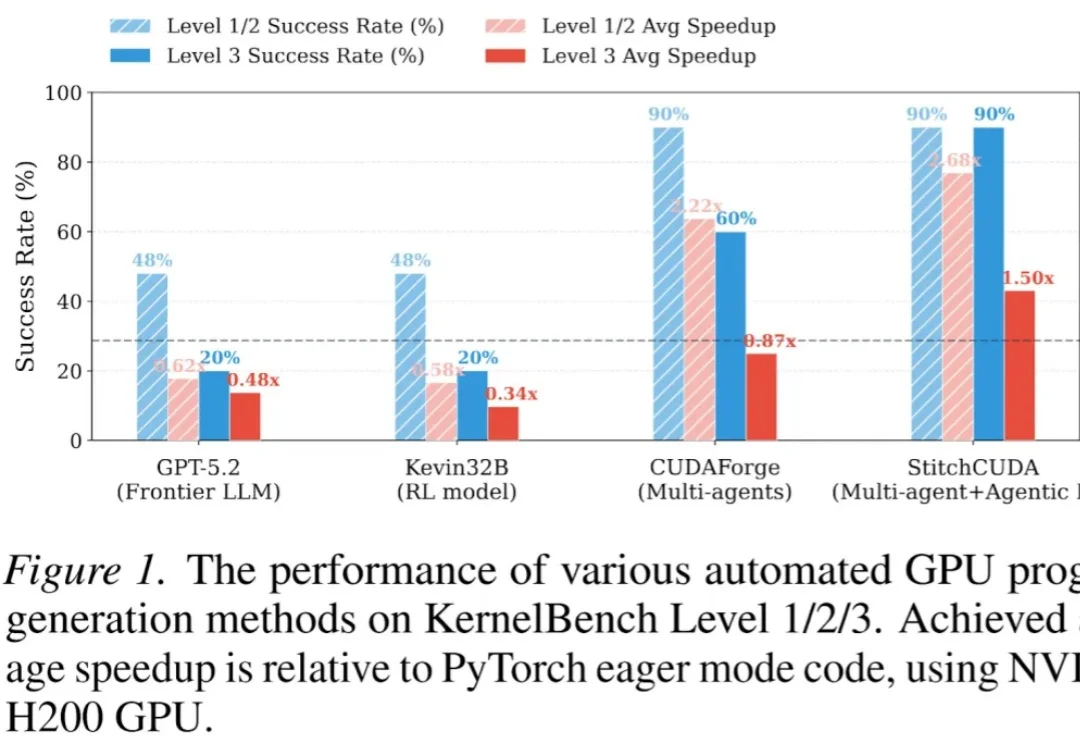
现有的 LLM 自动化 CUDA 方法大多只能优化单个 Kernel,面对完整的端到端 GPU 程序(如整个 VisionTransformer 推理)往往束手无策。

刚刚,YC最新创业清单点名「AI欺诈猎手」。当黑灰产开始用AI作案,防守方也在组建智能体军团——反欺诈的终局,或许不是更强风控,而是一个自带安全基因的智能体世界。

Openclaw是不是不如骆老师轶航家的狗还需要探讨,但云端Openclaw肯定是路边一条。

如果科研中的文献阅读、代码演进、实验验证都可以由智能体自主完成,科学发现的方式会被重新定义吗?自主科研智能体(Autonomous Research Agent)的兴起,正在把这一设想带入现实:科学家有望回归科学品味和探索源头,智能体承担科研全链路的繁琐工作,两者在人机协同的闭环中共探新的重大科研突破。
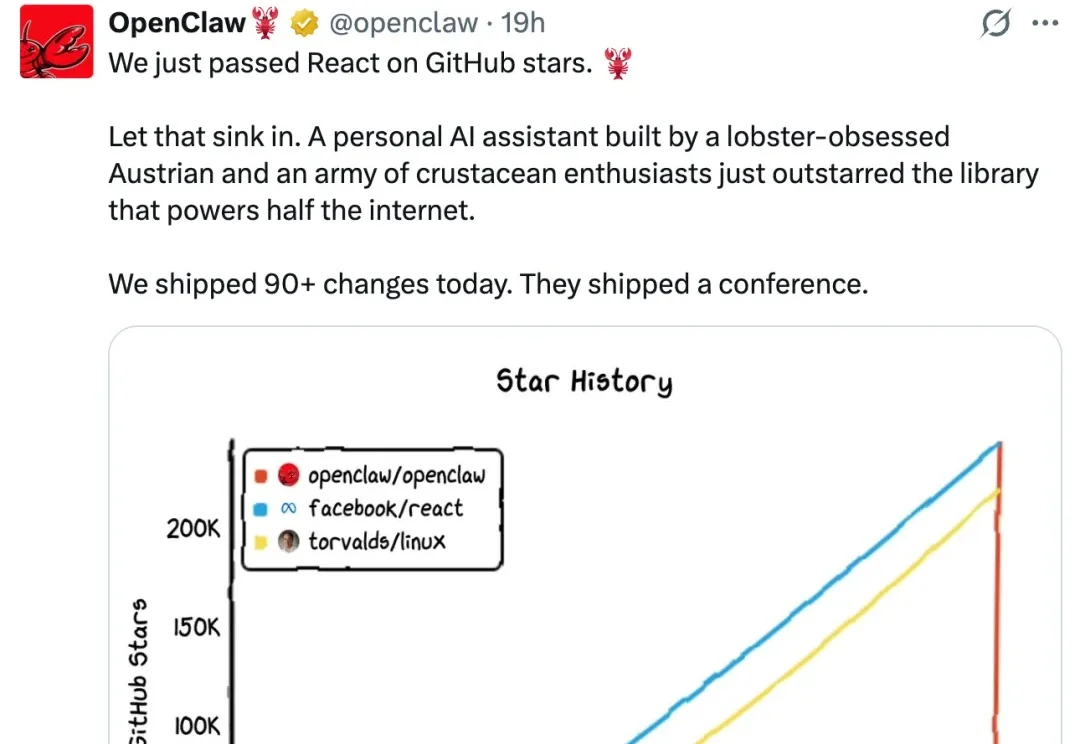
2026 开年已两个月,Agent 依然是全球最引人注目的 AI 赛道之一。OpenClaw(原 Clawbot)掀起的那波 Agent 热潮至今仍在发酵,甚至让「一人公司」概念第一次真正有了落地的可能性。

冲刺多智能体第一股,毛利率超80%。

让AI自己写高性能GPU代码,字节Seed与清华AIR团队做到了。
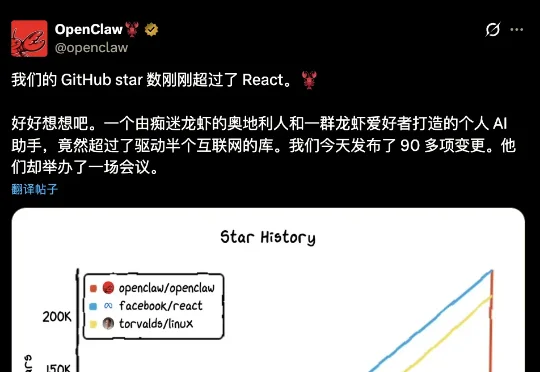
仅用两月,本地AI框架OpenClaw击败Linux,登顶GitHub星标榜!本文回顾了OpenClaw爆火之路,及其背后反映的开源社区趋势变化。
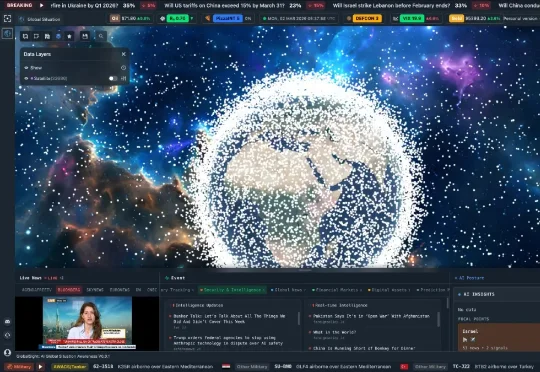
当传统媒体还在急于拼凑前线的碎片,当西装革履的智库专家还在连夜召开研讨会时,一个残酷的现实已经摆在所有人面前:在信息爆炸的地缘政治博弈中,如果你还在依赖人工分析和新闻推送来观察一场战争,你已经彻底沦为信息差的最底端。