
“26年具身智能,做不过来,根本做不过来”:含陶大程教授独家专访 l 深度产业观察
“26年具身智能,做不过来,根本做不过来”:含陶大程教授独家专访 l 深度产业观察2026年具身智能这么热, 美国旧金山PI Robotics这家机器人创业公司, 你真得知道。
来自主题: AI资讯
6415 点击 2026-04-14 08:40
 搜索
搜索
2026年具身智能这么热, 美国旧金山PI Robotics这家机器人创业公司, 你真得知道。

这个月,具身智能领域又卷出新高度:硅谷独角兽公司 Generalist AI 发布全新一代基础模型 GEN-1,将机器人包装手机、折纸箱这些活的平均成功率直接拉到了创纪录的 99%,折纸箱的速度更是飙到了以前的三倍(34s vs 12.1s)。

智东西4月12日消息,昨日下午,宇树科技在B站和社交平台X上发出一段新视频,其人形机器人H1跑步速度达到每秒10米,宇树官方称H1用“普通人的体质,跑出了世界冠军的速度”,再次刷新人形机器人的世界纪录。

4 月 10 日晚,灵初智能发布了大模型、数据集与合作计划:包括策略模型 Psi-R2、世界模型 Psi-W0,以及总规模近 10 万小时的人类操作数据。它想回答的问题也很直接 —— 当真机数据不再是唯一解,机器人还能靠什么继续 scaling?
人工智能和机器人领域,有一个反直觉现象: 往往人类觉得复杂、困难的任务,机器人做起来很容易;而人类不以为意的一些感知与运动技能,让机器复现异常困难。

硅谷「华人地图第一人」入局具身数据赛道。

从高价值商业场景切入,打造“真通用”的具身智能。
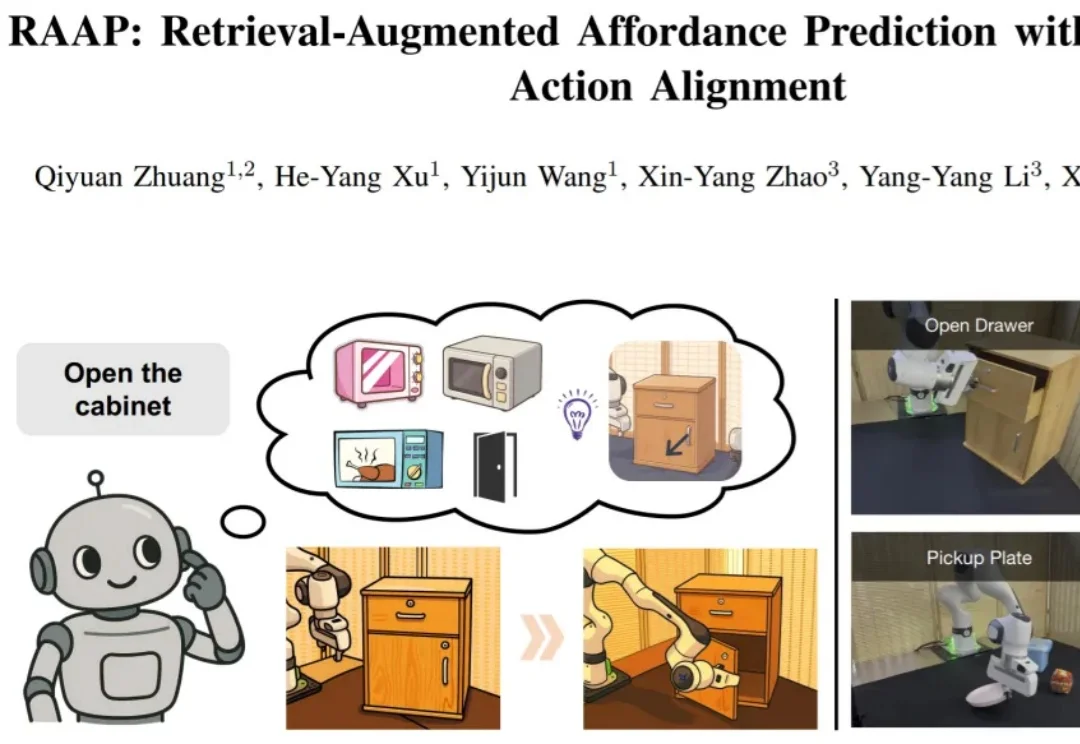
在具身智能领域,可供性(affordance)预测 —— 即让机器人从视觉观测中理解 "在哪里操作"(接触点)与 "如何操作"(动作方向)—— 是实现精细化机器人操作的基础之一。精细操作要求机器人不仅能定位到物体的可交互区域,更要掌握接触后的准确运动方向,例如判断抽屉把手的精确拉动方向完成开合。

刚刚,深圳机器人芯片公司地瓜机器人宣布拿下1.5亿美元(约合人民币10.24亿元)B2轮新融资,某零售科技与供应链巨头、滴滴、Prosperity7风投基金、高瓴创投、淡马锡旗下Vertex Growth、五源资本等产业巨头及一线资本参投。

刚刚,奥特曼亲自为打工人送上了一份「超级智能时代的生存指南」。发钱、上4休3、机器人交税养社保……这份13页的政策文件直接引爆硅谷。当造AI的人开始教你生存指南,说明这场风暴已经比所有人想象的都要近了。