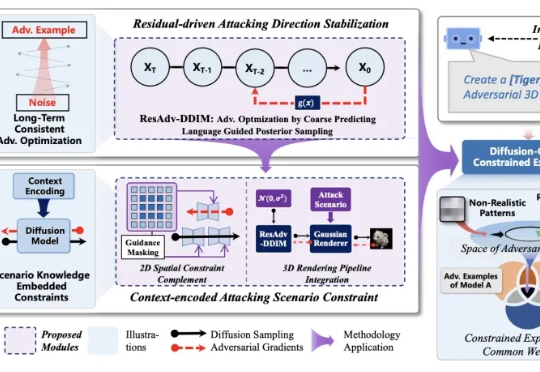
一个指令误导智能模型!北航等首创3D语义攻击框架,成功率暴涨119%
一个指令误导智能模型!北航等首创3D语义攻击框架,成功率暴涨119%人工智能模型的安全对齐问题,一直像悬在头顶的达摩克利斯之剑。 自对抗样本被发现以来,这一安全对齐缺陷,广泛、长期地存在与不同的深度学习模型中。
来自主题: AI资讯
7972 点击 2025-10-23 16:00
 搜索
搜索
人工智能模型的安全对齐问题,一直像悬在头顶的达摩克利斯之剑。 自对抗样本被发现以来,这一安全对齐缺陷,广泛、长期地存在与不同的深度学习模型中。
大模型在强化学习过程中,终于知道什么经验更宝贵了! 来自上海人工智能实验室、澳门大学、南京大学和香港中文大学的研究团队,最近提出了一套经验管理和学习框架ExGRPO—— 通过科学地识别、存储、筛选和学习有价值的经验,让大模型在优化推理能力的道路上,走得更稳、更快、更远。

近日,范鹤鹤(浙江大学)、杨易(浙江大学)、Mohan Kankanhalli(新加坡国立大学)和吴飞(浙江大学)四位老师提出了一种具有划时代意义的神经网络基础操作——Translution。 该研究认为,神经网络对某种类型数据建模的本质是:
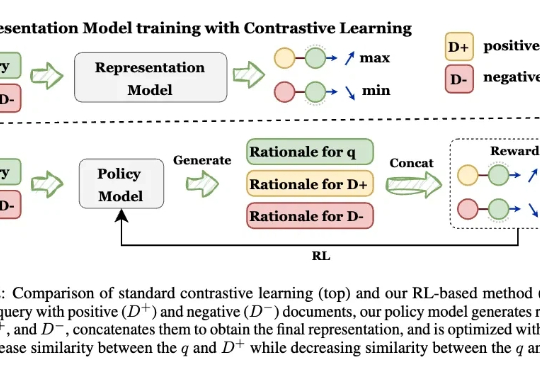
让模型先解释,再学Embedding! 来自UIUC、ANU、港科大、UW、TAMU等多所高校的研究人员,最新推出可解释的生成式Embedding框架——GRACE。过去几年,文本表征(Text Embedding)模型经历了从BERT到E5、GTE、LLM2Vec,Qwen-Embedding等不断演进的浪潮。这些模型将文本映射为向量空间,用于语义检索、聚类、问答匹配等任务。
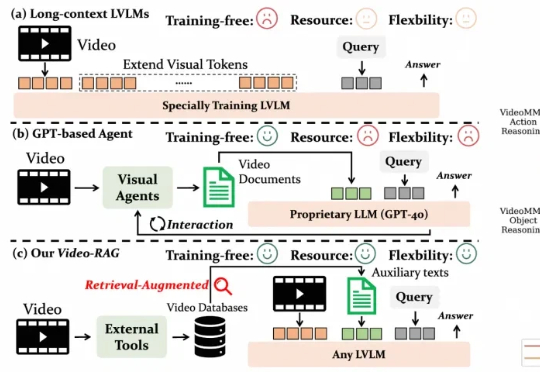
尽管视觉语言模型(LVLMs)在图像与短视频理解中已取得显著进展,但在处理长时序、复杂语义的视频内容时仍面临巨大挑战 —— 上下文长度限制、跨模态对齐困难、计算成本高昂等问题制约着其实际应用。针对这一难题,厦门大学、罗切斯特大学与南京大学联合提出了一种轻量高效、无需微调的创新框架 ——Video-RAG。
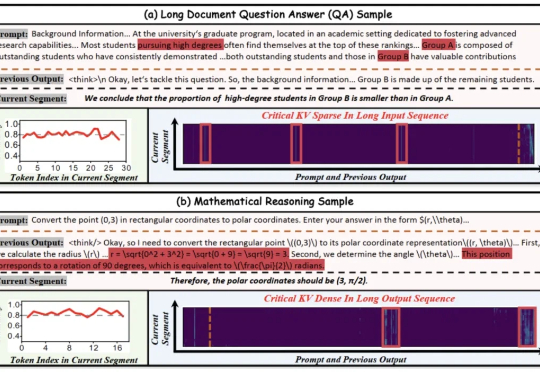
北大华为联手推出KV cache管理新方式,推理速度比前SOTA提升4.7倍! 大模型处理长序列时,KV cache的内存占用随序列长度线性增长,已成为制约模型部署的严峻瓶颈。
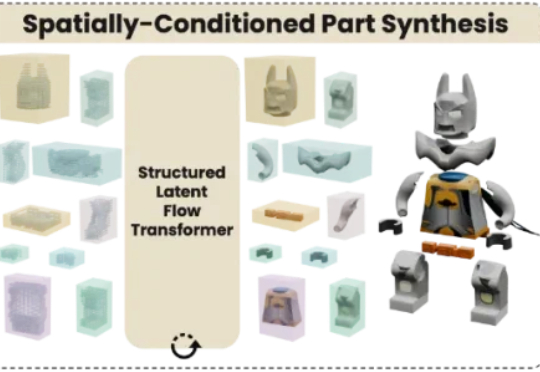
在3D内容创作领域,如何像玩乐高一样,自由生成、编辑和组合对象的各个部件,一直是一个核心挑战。香港大学、VAST、哈尔滨工业大学及浙江大学的研究者们联手,推出了一个名为 OmniPart 的全新框架,巧妙地解决了这一难题。该研究已被计算机图形学顶会 SIGGRAPH Asia 2025 接收。
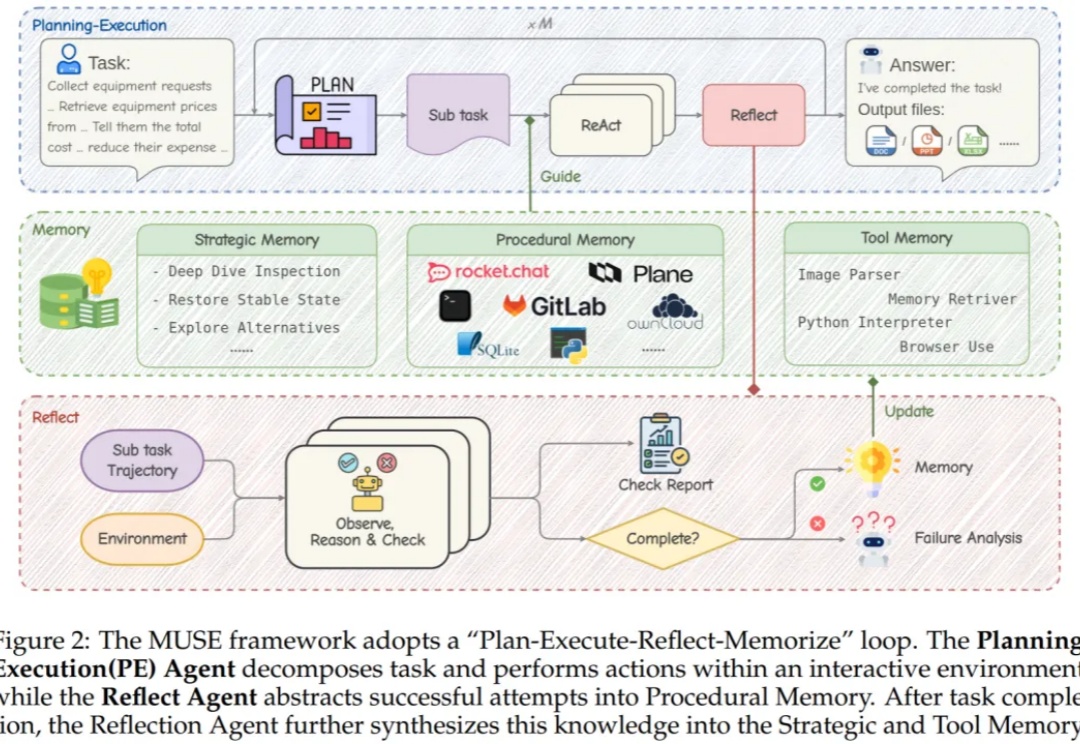
在人工智能的广阔世界里,我们早已习惯了LLM智能体在各种任务中大放异彩。但有没有那么一瞬间,你觉得这些AI“牛马”还是缺了点什么?

UC Berkeley、UW、AI2 等机构联合团队最新工作提出:在恰当的训练范式下,强化学习(RL)不仅能「打磨」已有能力,更能逼出「全新算法」级的推理模式。他们构建了一个专门验证这一命题的测试框架 DELTA,并观察到从「零奖励」到接近100%突破式跃迁的「RL grokking」现象。

不再依赖人工设计,让模型真正学会管理记忆。