32专家MoE大模型免费商用!性能全面对标Llama3,单token推理消耗仅5.28%
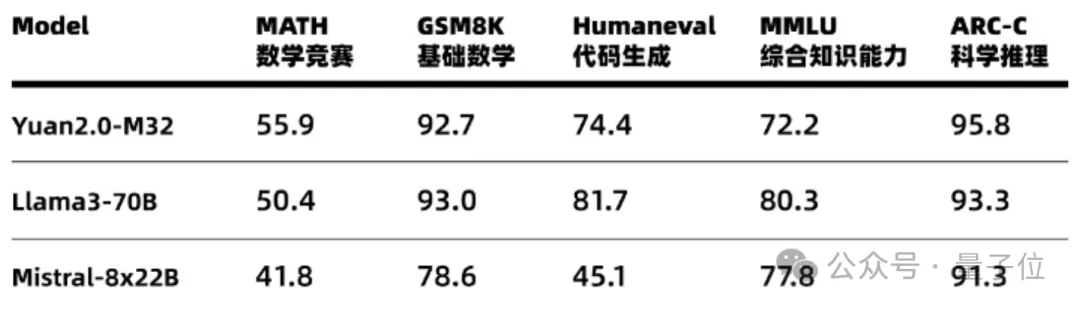
32专家MoE大模型免费商用!性能全面对标Llama3,单token推理消耗仅5.28%每个token只需要5.28%的算力,精度就能全面对标Llama 3。
来自主题: AI技术研报
11476 点击 2024-05-30 15:51
 搜索
搜索
每个token只需要5.28%的算力,精度就能全面对标Llama 3。

在大模型实际部署落地的过程中,如何赋予大模型持续学习的能力是一个至关重要的挑战。这使其能够动态适应新的任务并不断获得新的知识。大模型的持续学习主要面临两个重大挑战,分别是灾难性遗忘和知识迁移。灾难性遗忘是指模型在学习新任务时,会忘记其已掌握的旧任务。知识迁移则涉及到如何在学习新任务时有效地应用旧任务的知识来提升新任务学习的效果。

通过提示查询生成模块和任务感知适配器,大一统框架VimTS在不同任务间实现更好的协同作用,显著提升了模型的泛化能力。该方法在多个跨域基准测试中表现优异,尤其在视频级跨域自适应方面,仅使用图像数据就实现了比现有端到端视频识别方法更高的性能。

国产大模型最新进展,这次来自“国家队”! 刚刚,全栈国产化生态大模型“九天智能基座”正式发布! 它由中国移动自研。包括万卡算力、千亿模型及百汇平台三部分。 其中模型部分是九天自主研发的从算子到框架全栈国产训练的千亿参数大模型,能力达到GPT-4的90%水平。
本文由GreenBit.AI团队撰写,团队的核心成员来自德国哈索·普拉特纳计算机系统工程院开源技术小组。我们致力于推动开源社区的发展,倡导可持续的机器学习理念。我们的目标是通过提供更具成本效益的解决方案,使人工智能技术在环境和社会层面产生积极影响。

既能像 Transformer 一样并行训练,推理时内存需求又不随 token 数线性递增,长上下文又有新思路了?

当地时间2024年5月22日,美国众议院外交事务委员会以压倒性多数,通过了一项限制AI模型出口的法案——《加强海外关键出口限制国家框架法案》(Enhancing National Frameworks for Overseas Critical Exports Act / HR 8315,以下简称ENFORCE法案),旨在扩大美国政府监管人工智能系统出口的权力。
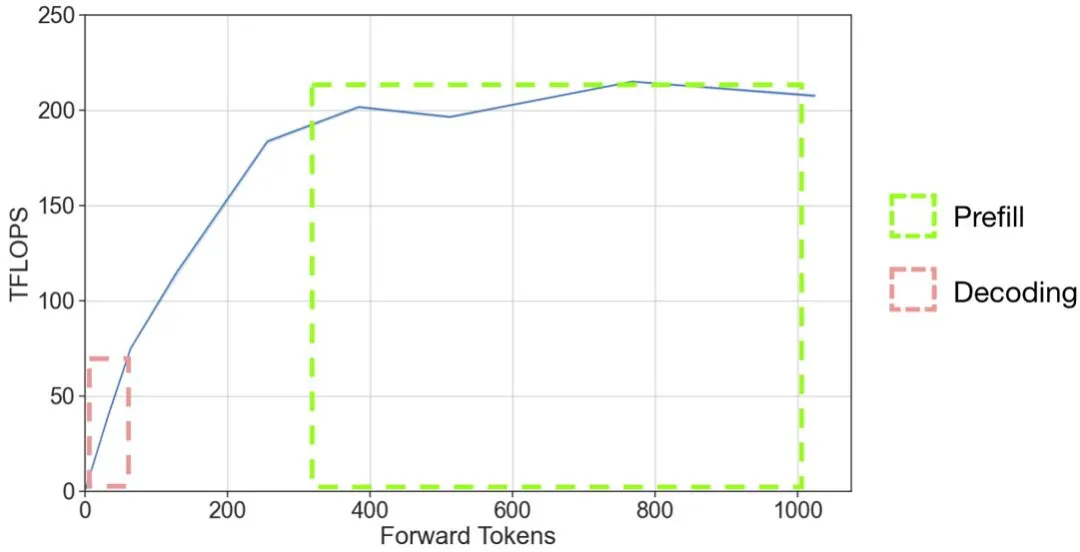
以 OpenAI 的 GPT 系列模型为代表的大语言模型(LLM)掀起了新一轮 AI 应用浪潮,但是 LLM 推理的高昂成本一直困扰着业务团队。

在多标签图像识别领域中,由于图像本身和潜在标签类别的复杂性,收集满足现有模型训练的多标签标注信息往往成本高昂且难以拓展。中山大学联合广东工业大学联手探索标注受限情况下的多标签图像识别任务,通过对多标签图像中的强语义相关性的探索研究,提出了一种异构语义转移(Heterogeneous Semantic Transfer, HST) 框架,实现了有效的未知标签生成。

英伟达正在宣传其Grace Hopper的异构计算框架正在被分布于世界各地的9台超算系统所使用,共同实现了惊人的 200 exaflops的AI计算能力。这表明英伟达正在为世界上一些更强大的人工智能系统供货,已经开始取代AMD和英特尔在高性能计算领域的地位。