
延迟下降20×,token减少4.4×!突破多智能体「共识」瓶颈
延迟下降20×,token减少4.4×!突破多智能体「共识」瓶颈过去一年,LLM Agent几乎成为所有 AI 研究团队与工业界的共同方向。OpenAI在持续推进更强的推理与工具使用能力,Google DeepMind将推理显式建模为搜索问题,Anthropic则通过规范与自我批判提升模型可靠性。
来自主题: AI技术研报
10613 点击 2026-02-07 14:04
 搜索
搜索
过去一年,LLM Agent几乎成为所有 AI 研究团队与工业界的共同方向。OpenAI在持续推进更强的推理与工具使用能力,Google DeepMind将推理显式建模为搜索问题,Anthropic则通过规范与自我批判提升模型可靠性。
一睁眼,Anthropic上新模型,让Claude Opus 4.6来给您拜!年!了!
大模型的革命行将结束,即将开启的会是物理 AI 时代?

2026 刚来到 2 月,无论是底层模型大厂还是初创公司统统加速开卷,其中 Agentic Memory 方向的快速进化更是把大模型的能力上限推向了 NEXT LEVEL!

刚刚,何恺明团队提出全新生成模型范式漂移模型(Drifting Models)。
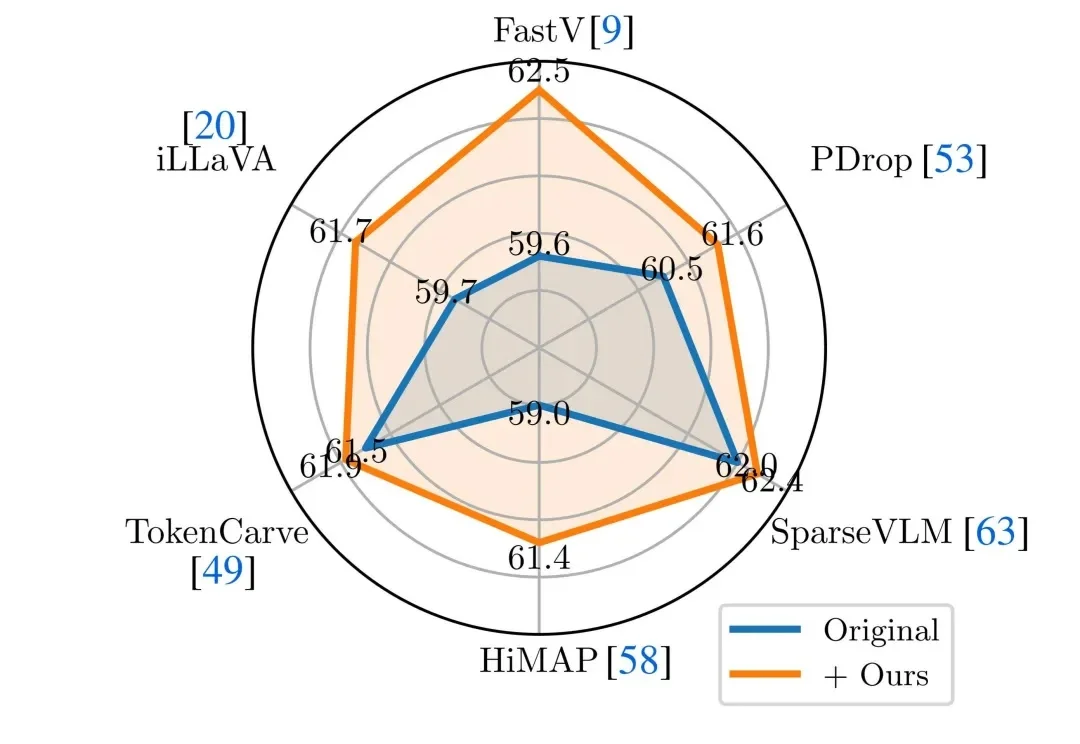
近年来,Vision-Language Models(视觉 — 语言模型)在多模态理解任务中取得了显著进展,并逐渐成为通用人工智能的重要技术路线。然而,这类模型在实际应用中往往面临推理开销大、效率受限的问题,研究者通常依赖 visual token pruning 等策略降低计算成本,其中 attention 机制被广泛视为衡量视觉信息重要性的关键依据。
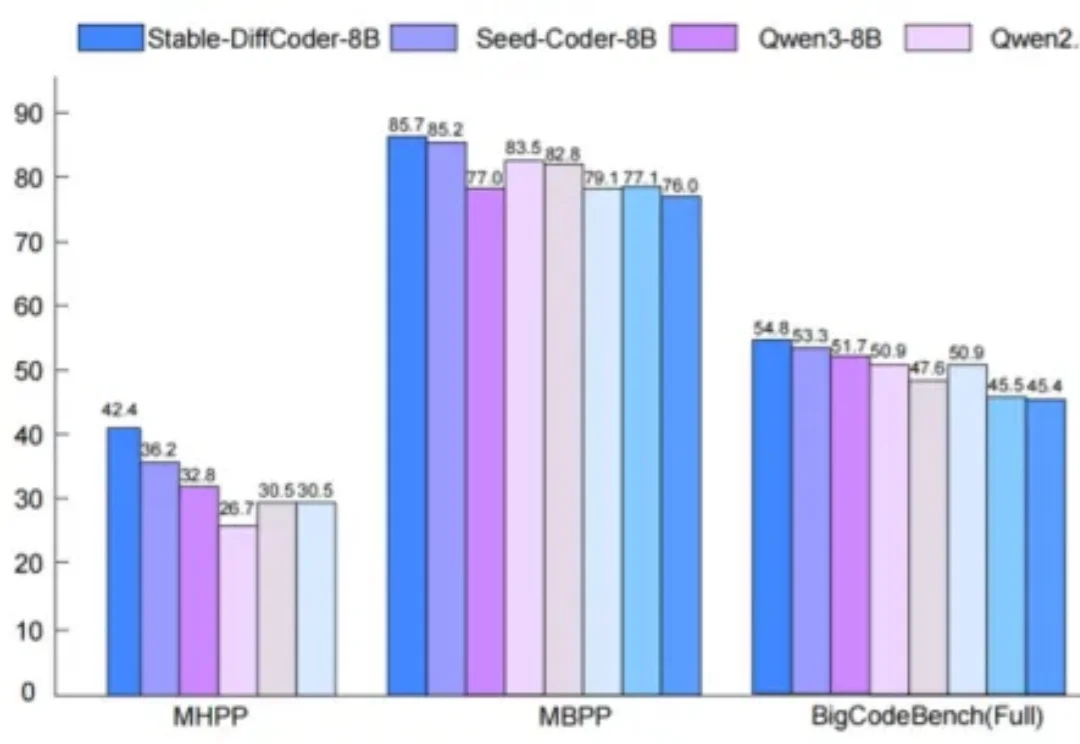
扩散语言模型(Diffusion Language Models, DLLMs)因其多种潜在的特性而备受关注,如能加速的非自回归并行生成特性,能直接起草编辑的特性,能数据增强的特性。然而,其模型能力往往落后于同等规模的强力自回归(AR)模型。
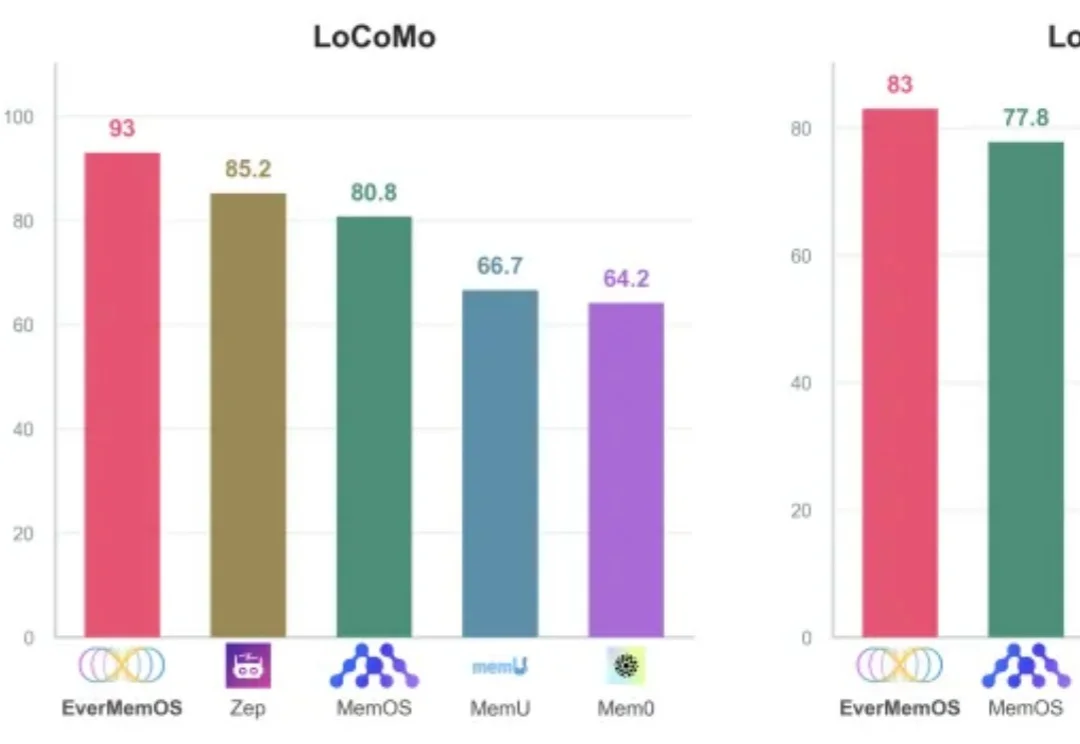
开年,DeepSeek论文火遍全网,内容聚焦大模型记忆。
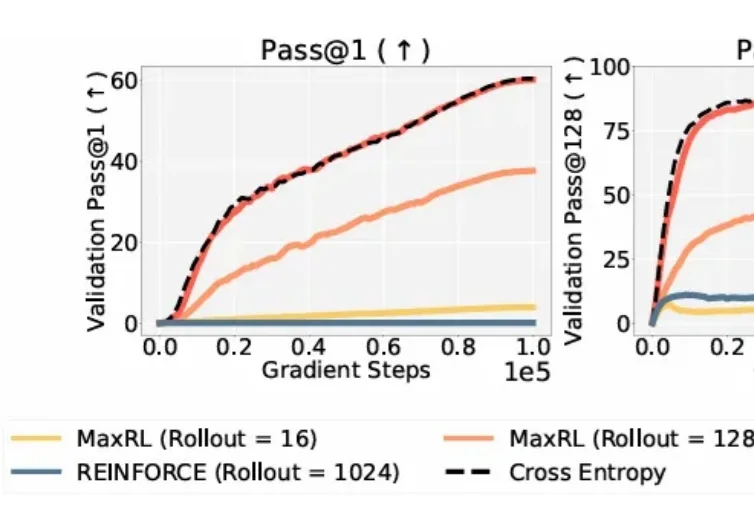
在大模型时代,从代码生成到数学推理,再到自主规划的 Agent 系统,强化学习几乎成了「最后一公里」的标准配置。
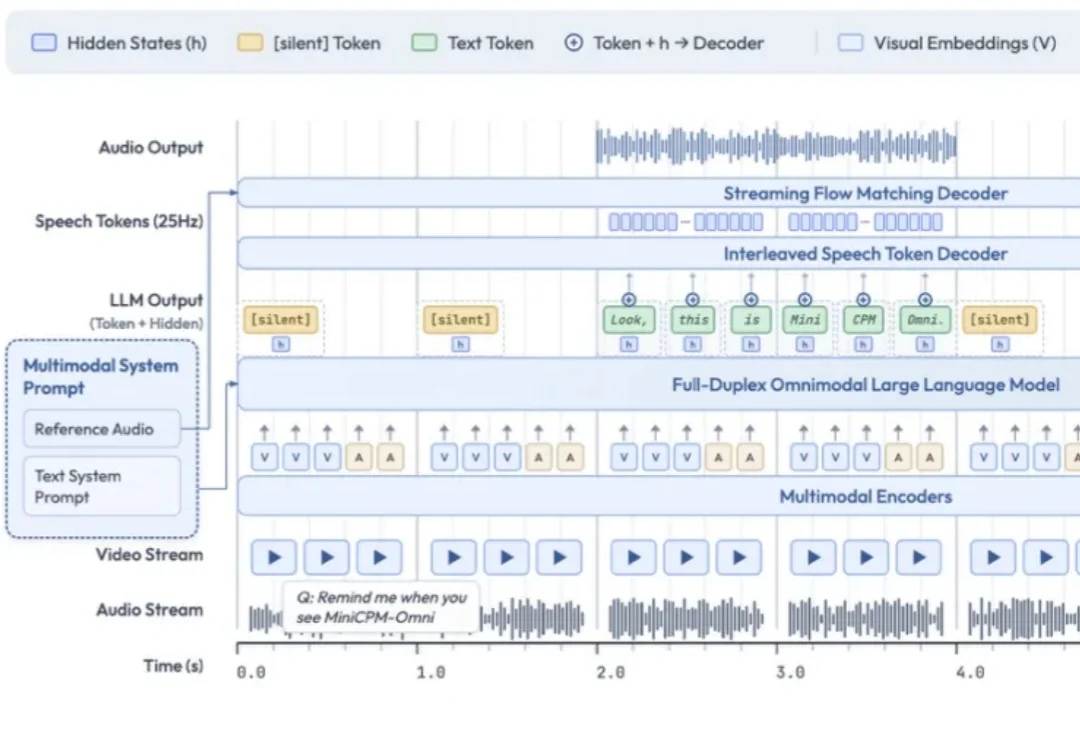
空气炸锅“叮”了一声。