
谷歌新发现:DeepSeek推理分裂出多重人格,左右脑互搏越来越聪明
谷歌新发现:DeepSeek推理分裂出多重人格,左右脑互搏越来越聪明AI变聪明的真相居然是正在“脑内群聊”?!
来自主题: AI技术研报
10668 点击 2026-01-21 12:01
 搜索
搜索
AI变聪明的真相居然是正在“脑内群聊”?!
不知道有多少人曾为了让数据图表既“好看”又“好懂”,而在设计软件与代码编辑器之间反复横跳,熬到“头秃”。

在2026年的世界经济论坛上,微软 CEO 萨提亚·纳德拉(Satya Nadella)与贝莱德 CEO 拉里·芬克(Larry Fink)进行了一场对话。
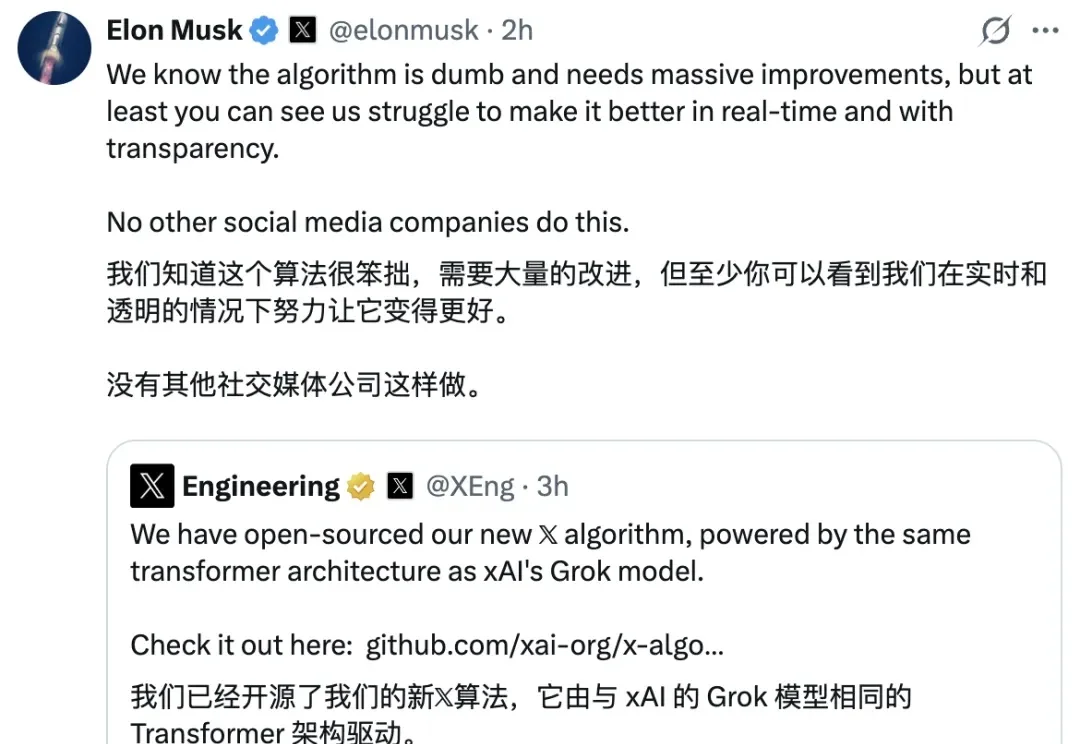
刚刚,𝕏 平台(原 Twitter 平台)公布了全新的开源消息:已将全新的推荐算法开源,该算法由与 xAI 的 Grok 模型相同的 Transformer 架构驱动。
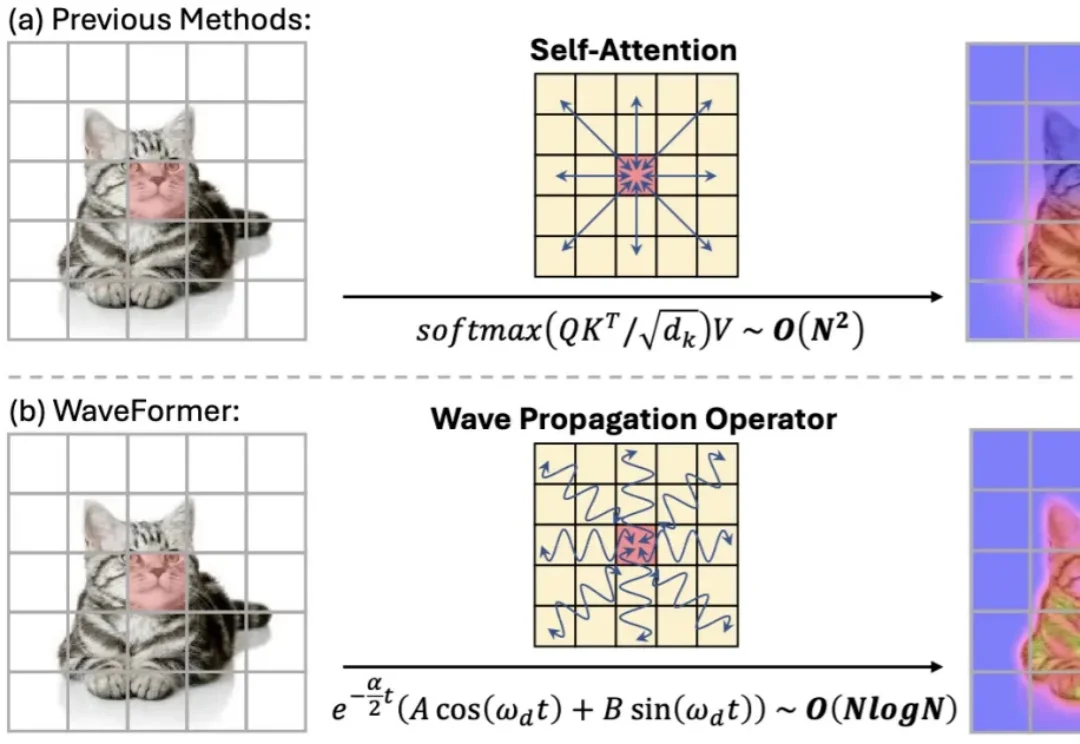
“全局交互” 几乎等同于 self-attention:每个 token 都能和所有 token 对话,效果强,但代价也直观 —— 复杂度随 token 数平方增长,分辨率一高就吃不消。现有方法大多从 “相似度匹配” 出发(attention),或从 “扩散 / 传导” 出发(热方程类方法)。但热方程本质上是一个强低通滤波器:随着传播时间增加,高频细节(边缘、纹理)会迅速消失,导致特征过平滑。

如果你最近关注了 GitHub,可能会注意到一个有趣的现象: YOLO 的版本号,直接从 11 跳到了 26。
2025 年 1 月 20 日,DeepSeek(深度求索)正式发布了 DeepSeek-R1 模型,并由此开启了新的开源 LLM 时代。在 Hugging Face 刚刚发布的《「DeepSeek 时刻」一周年记》博客中,DeepSeek-R1 也是该平台上获赞最多的模型。

昨天,Claude刚刚被曝要有永久记忆,今天就被开发者抢先一步。一个叫Smart Forking的扩展,让大模型首次拥有「长期记忆」,无需重头解释。开发者圈沸腾了:难以置信,它真的能跑!
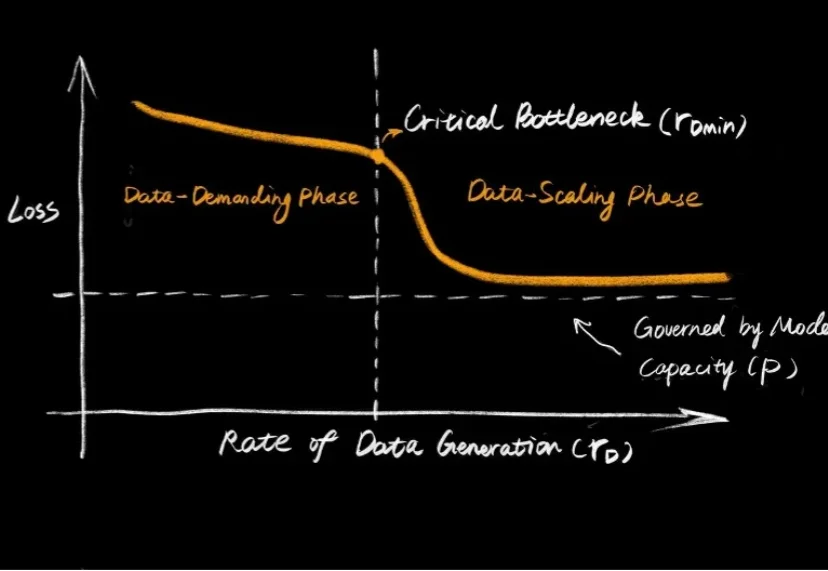
大语言模型的爆发,让大家见证了 Scaling Law 的威力:只要数据够多、算力够猛,智能似乎就会自动涌现。但在机器人领域,这个公式似乎失效了。

我们进入了一个模型不再只是“工具”的时代。真正的突破,不在于它能做多少事,而在于它是否能读懂你的意图、情绪与沉默。