
独家|千觉机器人完成亿元融资,加速物理智能触觉感知、数据与模型体系落地
独家|千觉机器人完成亿元融资,加速物理智能触觉感知、数据与模型体系落地Z Potentials 获悉,近日,国内具身触觉头部企业千觉机器人科技(上海)有限公司(以下简称“千觉机器人”或“Xense Robotics”)完成亿元融资。本轮融资由顶级具身智能产业方与吉德电器战略投资,新锐投资机构天季资本共同投资。
来自主题: AI资讯
6387 点击 2026-07-14 15:52
 搜索
搜索
Z Potentials 获悉,近日,国内具身触觉头部企业千觉机器人科技(上海)有限公司(以下简称“千觉机器人”或“Xense Robotics”)完成亿元融资。本轮融资由顶级具身智能产业方与吉德电器战略投资,新锐投资机构天季资本共同投资。

同一个问题,换一种语言问 Claude,得到的可能不只是措辞不同的答案。

曾经我们对 AI 的期待还比较朴素,写邮件、翻译论文、聊天搭子……那时候,AI 像一个初出茅庐的实习生,你指哪它打哪,但也经常一本正经地胡说八道。
近日,自监督学习新工作 VISReg(Variance-Invariance-Sketching Regularization)获图灵奖得主 Yann LeCun 连续转发并给予高度认可 —— 他在转发时评价道「VICReg begat SIGReg which begat VISReg」(VICReg 孕育了 SIGReg,SIGReg 又孕育了 VISReg),

7月6日,腾讯混元Hy3正式版发布。

AI 智能体,现在有了专用的算力。

Reve 在 7 月 9 日把图像模型迭代到了 2.1 版。距离 2.0 发布刚好一个月,放在基础模型圈子这不算常见。前面只挡着一个 OpenAI 的 GPT Image 2。另外官方说:「训练这版模型用的算力不到排行榜前后邻居的十分之一」。
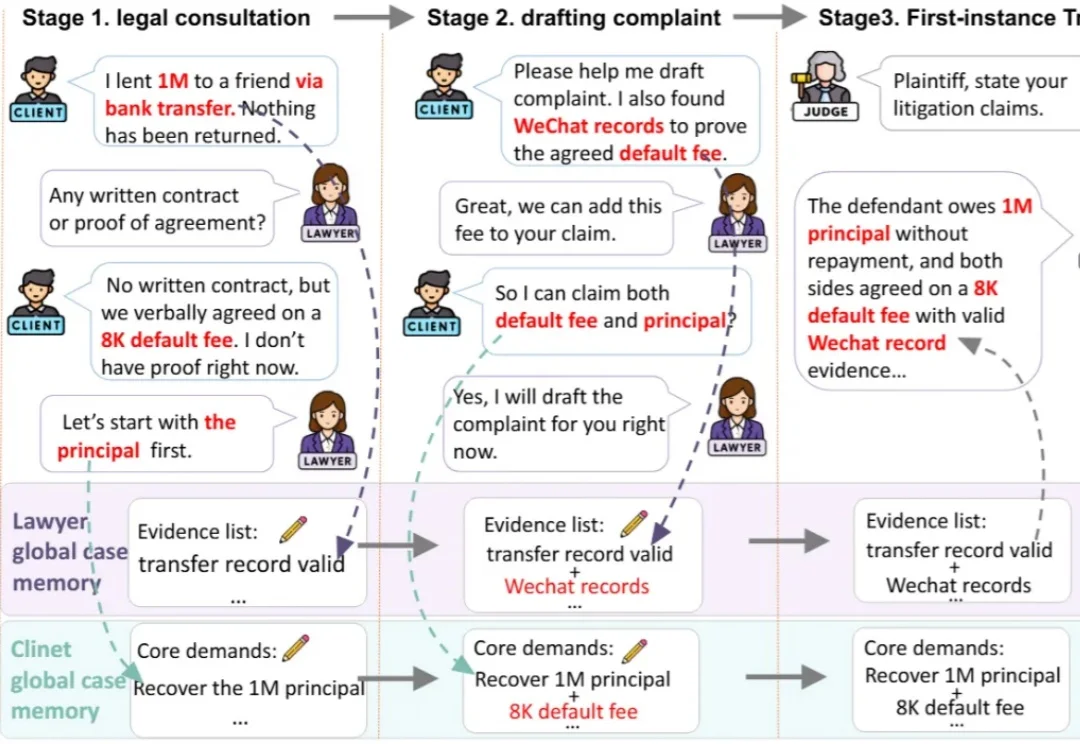
打官司,从来不是一问一答就能结束的事。
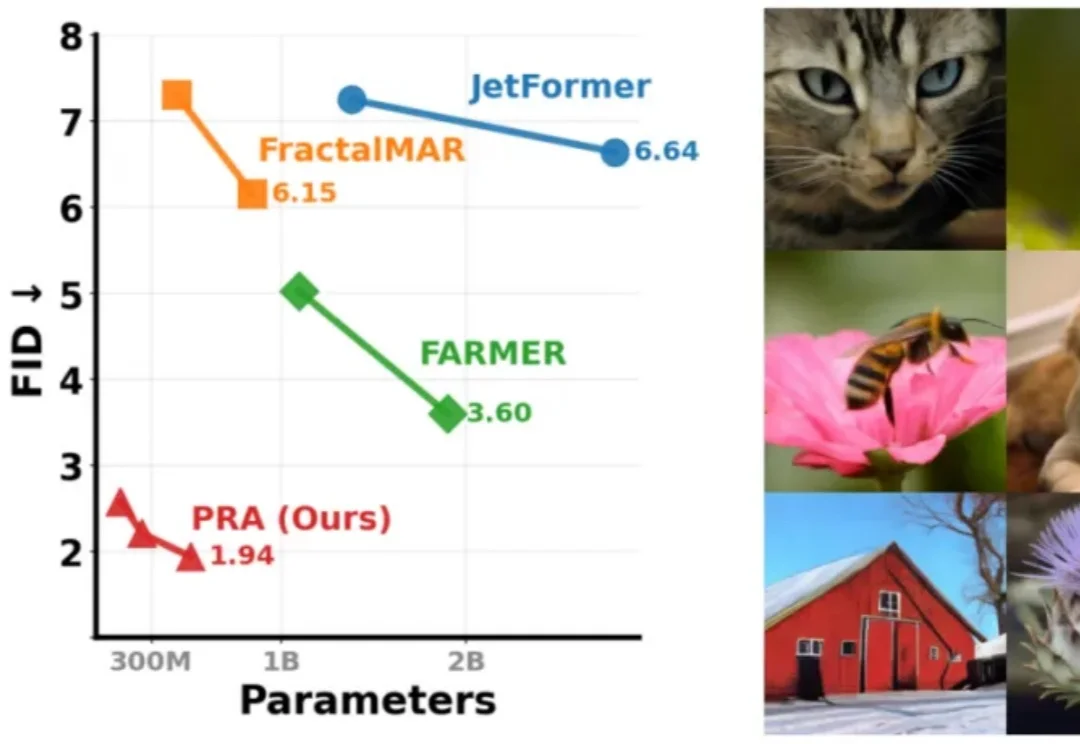
过去几年,扩散模型几乎定义了高质量图像生成:从随机噪声出发,经过多轮迭代,逐步 “雕刻” 出一张图像。但随着大语言模型席卷人工智能领域,另一条路线正迅速走到舞台中央 —— 图像,能否也像语言一样,通过自回归方式逐步生成?

7月13日,阶跃星辰在上海正式发布面向智能体时代的大模型原生AI终端品牌STEPX,并同步推出全球首个智能体原生操作系统Step AOS(Step Agentic-native OS)和阶跃新一代个人智能体阶跃Amoo,正式打通了从基座模型、智能体系统到硬件终端的完整链路。